NVIDIA Ampere架构使数学运算速度加倍,为各种神经网络处理提速。

如果你玩过叠叠乐,那么就可以把AI稀疏性(sparsity)想象成是叠叠乐。
游戏参与者首先将积木块交错堆叠成一座积木塔。然后,每名玩家轮流取出一块积木,过程中玩家必须小心翼翼的,不能让积木塔倒塌。
游戏开始的时候,抽取积木很容易,但越往后进行就会变得越惊险,最后必定会有一名玩家在取出积木时碰倒整个积木塔。
多年来,研究人员们一直在研究如何通过稀疏性加速AI,其过程就像是在玩儿数字版的“叠叠乐”。他们尝试着尽可能多地从神经网络中抽出多余参数,同时又不破坏AI的超高精度。
这样做是为了减少深度学习所需的矩阵乘法堆,从而缩短取得准确结果的时间。但到目前为止,还没有出现“大赢家”。
过去,研究人员尝试了多种技术,抽出部分的权重甚至达到了神经网络的95%。但是,在整个过程中,他们所花的时间要远多于他们所节省的时间,而且他们还需要付出巨大的努力来弥补精简后的模型精度。此外,适用于一种模型的精简方法往往并不适用于其他模型。
但如今,这一问题得到了解决。
数字稀疏
NVIDIA Ampere架构为NVIDIA A100 GPU带来了第三代Tensor Core核心,其可以充分利用网络权值下的细粒度稀疏优势。相较于稠密数学计算(dense math),最大吞吐量提高了2倍,而且不会牺牲深度学习的矩阵乘法累加任务的精度。
测试表明,这种稀疏方法在许多AI任务(包括图像分类、对象检测和语言翻译)中使用,都能保持与使用稠密数学计算相同的精度。该方法还已在卷积神经网络和递归神经网络以及基于attention的transformer上进行了测试。
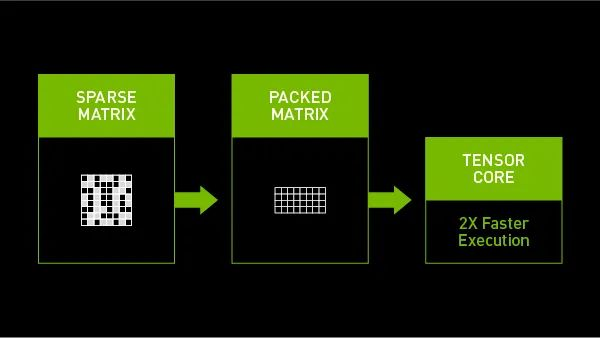
A100使用稀疏矩阵加速AI推理任务
内部数学加速能够对应用层面产生重大影响。A100 GPU可以利用稀疏性运行BERT(BERT是最新的自然语言处理模型),其运行速度比稠密数学计算快50%。
NVIDIA Ampere架构利用了神经网络中小值的普遍性,让尽可能多的AI应用受益。具体而言,该架构定义了一种可以减少一半权值(50%稀疏)来训练神经网络的方法。
少即是多,但前提是正确
一些研究人员使用粗粒度的剪枝方法从神经网络层中切断整个通道,这往往会降低网络精度。而NVIDIA Ampere架构中的方法采用了结构化稀疏和细粒度修剪技术,因此不会明显降低精度,用户可以在重训练模型时进行验证。
在将网络修剪到合适状态后,A100 GPU将自动完成其余工作。
A100 GPU中的Tensor Core核心能够有效地压缩稀疏矩阵以实现合适的稠密数学计算。跳过矩阵中的实际值为零的位置能够减少计算量,从而节省功耗和时间。压缩稀疏矩阵还可以减少占用宝贵的内存和带宽。
我们对稀疏性的支持是NVIDIA Ampere架构中的众多新功能之一,它将AI和HPC性能推向新的高度。








