新基建浪潮之下,各行各业都在积极拥抱AI,进行智能化转型,以“AI+”为核心的科技策略,正在推动社会形态、经济结构不断发生变化。随着AI技术的进一步发展,传统家居、安防、驾驶、教育、商业、城市管理……都将被颠覆。
而在这一过程中,数据作为驱动AI向前快速飞奔的“燃料”,重要性日渐凸显,大量的数据采集标注需求涌向市场。据艾瑞咨询《2020年中国人工智能基础数据服务白皮书》预测:到2025年,AI基础数据服务市场规模将突破100亿元。
在市场规模迅速扩大的同时,市场对数据的需求也在发生变化。
AI数据产业正在迎来变革
AI作为一项前沿应用技术,受到社会各界的广泛关注,经过多年发展,如今AI面临着一个现实而又紧迫的挑战——商业化落地。
为了加快落地进程,AI算法企业需要解决两个问题,一是提升算法的精确度,以保证在市场中的领先性;二是保障算法模型稳定度,从而实现在各类场景中的适用性。
而解决这两个现实问题的最简单办法就是——数据,大量、高质量、场景化的数据。

目前,AI数据生产主要依赖于市场上林林总总的AI数据服务企业、外包团队以及兼职个人,由于市场需求量大、准入门槛低,行业整体处于野蛮生长状态,从拼人力逐渐过渡到了拼价格,但本质上数据质量却没有明显提升。
在中国信息通信研究院发布《人工智能发展白皮书(2018年)》中也曾提到了“在数据层面,主要存在流通不畅、数据质量良莠不齐和关键数据集缺失等问题。尤其是数据标注主要通过外包形式,劳动力水平决定了产出的标注数据质量。”
而随着AI的落地,对数据质量要求的逐渐提高,AI数据产业也正在迎来变革,原本粗放式的数据生产模式已经逐渐式微,景联文科技这类AI品牌数据服务商开始兴起。
自建标注团队是行业发展必然
纵观市场,AI数据生产主要有转包模式、众包模式、自建团队模式三类。
早期众包模式凭借着低廉的价格、大规模的人力资源从而占据着市场,但随着行业发展,众包模式的弊端初显:直接和标注团队对接,非常考验需求方项目管理能力,并且由于标注人员素质等原因,无法执行复杂任务。
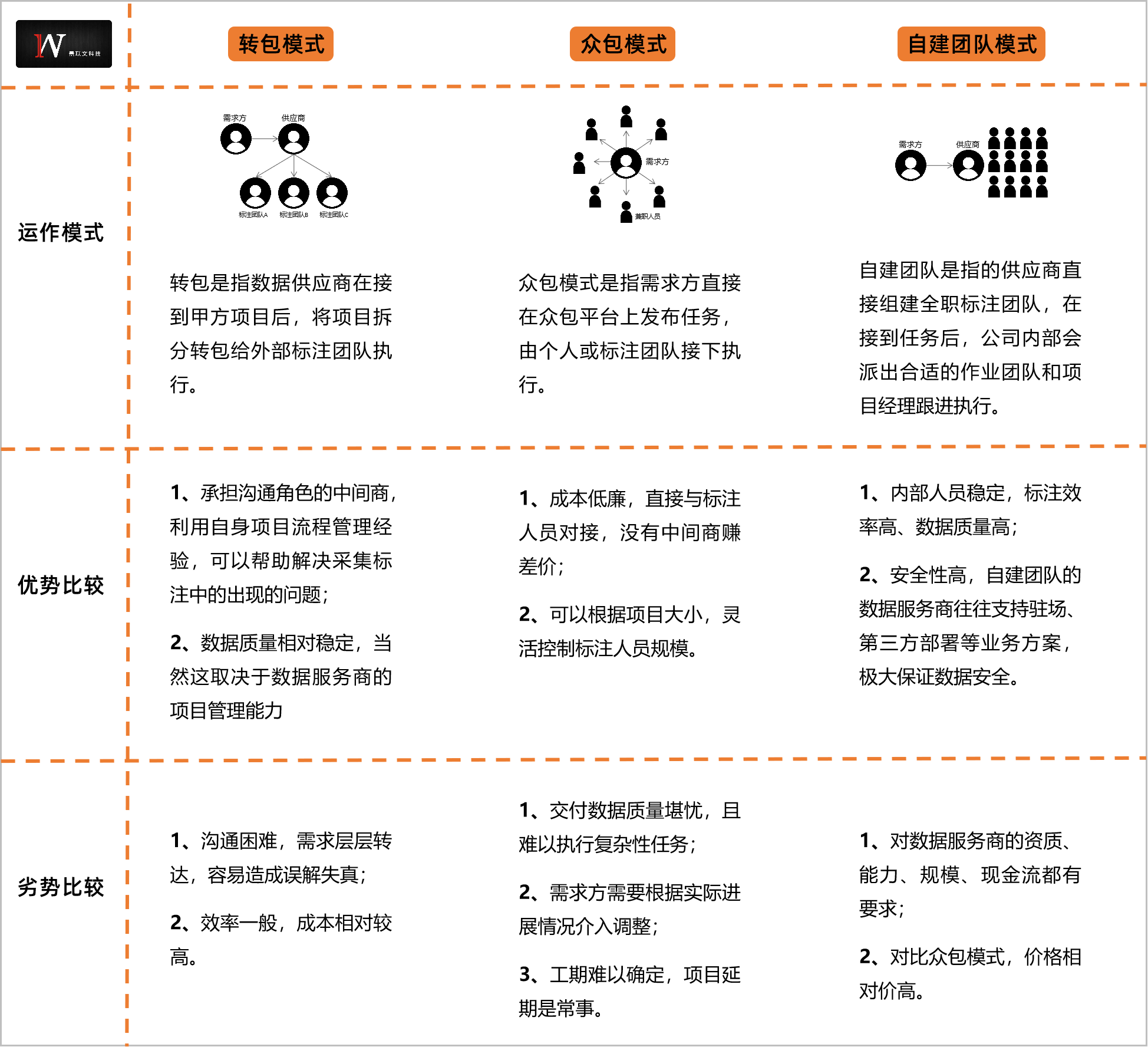
在众包模式不能满足市场的背景下,转包模式出现了。转包模式是由具备行业经验的数据供应商承接项目,再将项目拆分转包给标注团队或个人执行,数据供应商扮演的是一个沟通管理的角色,通过协调需求方以及标注团队,共同完成项目。
但转包模式也并非没有缺陷,由于供应商没有自己的采集标注团队,就容易出现层层转包情况,数据倒手数次,安全性无法保证。
对于科技企业而言,数据意味着未来,数据隐私和安全是科技公司做决策首要前提,因此,也有部分数据供应商投入大量资金、人力组建自有标注团队,并提供驻场、第三方部署等业务方案,解决了客户后顾之忧。
景联文科技CEO郑晓薇解释道:“传统AI数据生产,无论是转包还是众包,本质上都是一种轻资产模式,这样的优点是前期投入成本低,周转率快,但弊端也就是对交付数据质量和服务态度难以把控。AI大规模落地在即,未来行业对数据的需求将从量转向质的层面,因此,自建团队模式是行业发展的必然。”
景联文科技:自建标注团队,生产高质量AI数据
景联文作为市场上最早一批自建标注团队的AI数据服务商,在业务开展之初,就砸下重金组建项目团队,确保服务流程的规范与高效。
经过多年沉淀,目前景联文在全国范围内拥有5个标注基地,220名全职人工智能训练师;上线了自有标注平台,涵盖了绝大多数主流标注工具,支持语义分割、拉框标注、多边形标注、关键点标注、3D点云、2D3D融合标注、图片分类、声纹识别、ASR转写、韵律标注、NLP、文本分类、OCR转写、情绪判断等多种标注业务;提供企业私有化部署、跨地区作业等定制服务。
谈及自建标注团队的初衷,郑晓薇表示:“早期景联文专注于指纹防伪算法,随着业务的推进,公司有大批量指纹采集需求。考虑到指纹采集工作涉及到公众隐私,因此公司决定内部培养专业团队执行。”

一次偶然的机会,某科技大厂客户在参观了景联文数据基地后,希望景联文代为标注一批保密数据,由此景联文正式踏入了AI基础数据市场。短时间内,景联文凭借着多年处理敏感数据的经验,以及长期深耕To B市场的流程管理经验积累,在行业迅速站稳脚跟。
截至目前,景联文科技已与阿里巴巴、华为、vivo、美团、字节跳动、滴滴、陌陌、海康威视、大华、宇视、同济大学、中国人民大学、工信部中国电子技术标准化研究院、公安部一所等多家企业、机构达成深入合作。
景联文科技立足行业、放眼未来,从工具到团队管理,全方位构建完整业务生态。在AI数据服务这条赛道上,景联文还将继续前进,为AI落地提供高质量、场景化的数据支持。








