你走进澡堂,雾气弥漫。眼睛看到的人影模模糊糊。既看不清楚细节,也不知道是谁,只能看到大概轮廓。
你觉得手足无措,一分钟都不想待在那里。
你看到的情景,就是听障人士在真实世界里听到的情况。雾气相当于他们听到的嘈杂的声音。所有声音的细节统统丢失,听到的人声和音乐声,都淹没在一片非常浓厚嘈杂的噪音里。
对我们健全人来说,一直在雾气弥漫的场景里看东西,可以想象多么痛苦。对于听障人士而言,他们一辈子,7×24小时,都被困在了这样的环境里。
“如果能帮助他们,让他们听得见、听得清、听得真,听到我们健全人能听见的声音,那真是一件非常有意义的事情。”腾讯多媒体实验室高级总监商世东表示。
刚过去的9月27日,国际聋人日当天,腾讯多媒体实验室联合腾讯公益慈善基金会、深圳市信息无障碍研究会等机构召开发布会,宣布发起“天籁行动”——面向公益开发者、设备厂商、相关机构开放腾讯天籁AI音频技术,应用于听障人群无障碍建设等相关社会责任领域。
天籁行动,是腾讯“科技向善”的一次最新实践。从2019年11月11日开始,腾讯将“科技向善”写进公司最新的使命与愿景之中。
科技与人类的关系,在近年越发受到关注和讨论。事实上,不只腾讯,诸多科技公司都开始重视和强调用好科技,以科技为善:腾讯强调“科技向善”,华为强调“科技至善”。
如何让“科技向善”不是一句简单的口号,更要真正成为一个持续落地的使命。其背后的驱动机制,来自科技公司的技术外溢与产品力,带来持续不断的技术进步、产品落地和公益体系化建设。
腾讯天籁行动,正是这一科技向善机制的典型体现。腾讯分三步,实现了用AI帮助听障人士的科技实践:释放20余年音频技术积累,以产品力将技术落地于听障人群,为不同定制化场景研发针对性降噪解决方案。最终实现将人工耳蜗语音清晰度和识别度提升40%,极大改善听障人士的听觉体验,让他们“听得见”,更“听得清”。
1、从技术,到场景
优秀的技术研究团队,都有一个共同的特质:喜欢迎接未知的挑战,不断突破;越是遇到棘手的挑战,就会越兴奋。商世东和他所在的腾讯多媒体实验室,就是这样一支团队。
腾讯多媒体实验室,是腾讯公司前沿技术实验室之一,专注音视频通信技术的前瞻性研究,最擅长语音增强和降噪技术。针对语音在嘈杂环境中的情况,他们把经典信号处理和机器学习技术融合在一起,加上声学场景分析技术,打造了一套降噪解决方案。他们把降噪技术应用在包括腾讯会议等多个产品里,经过各种场景,各种设备,各样用户的体验和打磨,成功实现了国际领先的核心语音增强和降噪技术指标。
作为一个专注声音的研究团队,商世东和同事们在公司的一些无障碍项目交流当中,不止一次接触到听障人群。他们对声音的渴望,以及很多家庭为了孩子获得听的权利,付出了很多常人无法想象的努力,他们的坚持和努力,让人触动。
“一开始,这个技术是用在健全人的通信当中。但其实听障人员更需要语音增强和降噪技术,是用来解决他们听得见、听得懂的问题。”商世东说,”降噪技术对健全人是锦上添花,对听障人士是雪中送炭。”
世界卫生组织(WHO)数据显示,全球有约11亿年轻人(12-35岁之间)面临听力损失的风险,约4.66亿人患有残疾性听力损失。据第二次全国残疾人抽样调查结果显示,我国有听力残疾患者2780万人。而这2780万听障人士,通过科技填补自身缺陷的,不到5%。
商世东和腾讯多媒体实验室的同事们决定,将降噪技术贡献出来,提供给人工耳蜗厂商,让他们可以把采集到的声音信号进行降噪,帮助听障人士摆脱噪音烦恼,听到的干净得多、安静得多的声音世界。
但当他们试图把技术运用到人工耳蜗场景时,商世东和团队发现,他们遇到了前所未有的挑战:技术不是拿过来就可以用的,他们需要真正了解,对人工耳蜗用户来说,他们感到最痛的问题是什么。
“技术应用必须要场景驱动。我们需要了解,什么样的场景,人工耳蜗用户他们有最迫切的需要。” 商世东说。
“我们应该为他们做点什么?我们能为他们做点什么?”这是商世东和团队讨论最多的问题。
AI降噪技术需要在降噪和听觉感受之间取得平衡——人们可以听到一些场景声音,但不能太吵;不是一点噪声都没有,但要能把噪声能量控制在可接受的范围之内。
商世东和团队针对人工耳蜗的用户痛点,展开了深入调研。他们发现,对于人工耳蜗用户来说,有四类典型场景:第一类是音乐场景,他们想听音乐或看电视。第二类是干净的纯净语音场景,例如在家里只有跟家人的对话,没有太多嘈杂的声音。第三类是纯噪声的场景,比如戴着人工耳蜗的孩子想出去走一走,马路上有噪声,如果除了噪音什么都听不见就比较危险。第四类是带噪的语音场景,比如他们走在嘈杂的街道上,还能听得清,知道谁在跟他们讲话。
第三和第四类场景,是人工耳蜗用户们最痛的地方。没有AI降噪技术之前,技术很多时候顾此失彼,把所有的声音都放大了。他们在家里跟家人对话能听到,但是出去之后,有一些不想听到的声音就没办法屏蔽,特别吵。这时候又不能关掉人工耳蜗,否则什么都听不见了。
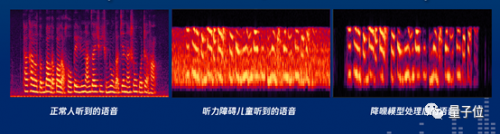
听障人士和健全人听到的声音波形对比
这个过程中最难的地方在于,如何判断哪些是噪音,哪些是有用的背景音?你去听一场交响乐,主旋律之外的鼓点、人们鼓掌的声音,都是突发的声音,机器很难判断是噪音,还是音乐。技术很容易把噪声识别成音乐。这给他们的研发进程带来了很大困扰。
“机器对连续的音乐很容易判断出来,但打击乐混在里面,机器很难讲它是噪声还是什么。就像打个喷嚏,我们语音特征也会显示是突发的噪声。噪声需要消除,但音乐不能消除,需要把音乐尽可能地保留住。” 商世东说。
为了解决这个困难,腾讯多媒体实验室针对性开发了针对人工耳蜗用户的多场景识别技术。通过人工智能深度学习做场景分类,用户常见的几种场景都能准确识别。比如听障儿童打电话的场景,声音里从电话里出来,跟声音从日常自然界出来又是不一样的,这个技术能把电话场景进一步识别出来。
针对人工耳蜗用户常见的4类声学场景,腾讯多媒体实验室在业界首次采用了基于深度学习的残








