作为一家以产品和技术取胜的公司,神策数据秉承把事情做到极致的精神,一直坚持在技术上迭代创新,永无止境地追求用更少的硬件资源处理更多的数据,且保持查询速度不断提升。随着服务的行业越来越多,神策数据在向客户学习的过程中也不断调整产品方法论和整体信息架构,补充产品功能,完善产品易用性。在神策2020数据驱动用户大会现场,神策数据联合创始人&CTO曹犟代表神策数据,详细介绍神策数据近期在技术和产品方面取得的新进展。本文内容根据现场演讲整理而成。
一、不止是用户行为数据分析工具,更是全新的数字化营销闭环解决方案 从数据角度而言,神策数据处理的不仅仅是用户行为数据,还包括第三方电商数据、广告数据、第一方如CRM、卡券系统等业务数据,贯通整合多渠道多类型数据源;从产品角度而言,神策数据也不仅仅提供一个数据分析工具,而是一个基于企业数据流的完整的数字化营销闭环解决方案。 在详解该话题之前,曹犟先与大家介绍了神策数据的产品演进,他认为,产品理念决定产品布局。在创业之初,神策数据就一直强调数据源的重要性,强调数据根基,强调数据驱动,强调自助式数据分析,强调数据可以在业务决策和产品智能两方面发挥作用。在过去5年里,随着服务的行业和客户越多,收集到需求也越广泛,团队在产品理念、数字化经营有了更多的认识,提出全新的SDAF运营框架,把整个数字化营销活动划分为感知(Sense)、决策(Decision)、行动(Action)、反馈(Feedback)四大环节。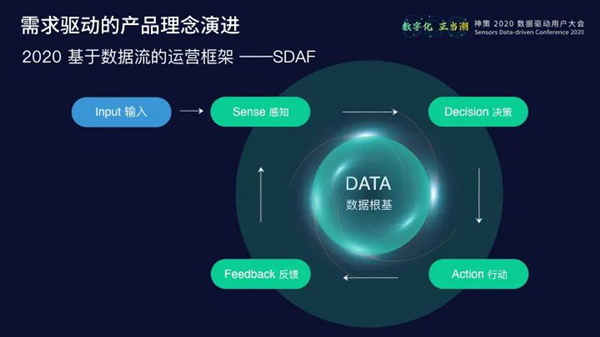 基于全新的产品理念,神策数据团队重新调整了整个产品矩阵设计。按照全新的SDAF运营框架,将神策分析、神策用户画像、神策智能运营、神策智能推荐、神策客景等产品,从一个个单独的产品重新整合成数据根基、分析云、营销云三大部分。
基于全新的产品理念,神策数据团队重新调整了整个产品矩阵设计。按照全新的SDAF运营框架,将神策分析、神策用户画像、神策智能运营、神策智能推荐、神策客景等产品,从一个个单独的产品重新整合成数据根基、分析云、营销云三大部分。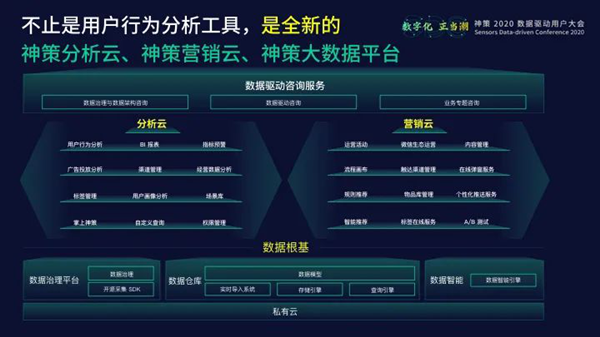 神策数据根基部分,由数据治理平台、数据仓库、数据智能引擎、私有云平台4个基础部分组成;神策分析云部分,不仅整合了全新升级后的用户行为分析、用户画像、指标预警、掌上神策等功能组件,还包括最近新推出的经营数据分析、广告分析等全新功能模块,提供更加全面、广泛的分析能力;神策营销云部分,完整地提供了弹窗、流程画布、内容管理、标签在线服务等一系列新功能,帮助客户完整地实现数据应用,打通数据驱动闭环的最后一节。同时,神策数据依然坚持数据驱动的咨询服务,坚持以产品+服务的方式为客户创造价值。
神策数据根基部分,由数据治理平台、数据仓库、数据智能引擎、私有云平台4个基础部分组成;神策分析云部分,不仅整合了全新升级后的用户行为分析、用户画像、指标预警、掌上神策等功能组件,还包括最近新推出的经营数据分析、广告分析等全新功能模块,提供更加全面、广泛的分析能力;神策营销云部分,完整地提供了弹窗、流程画布、内容管理、标签在线服务等一系列新功能,帮助客户完整地实现数据应用,打通数据驱动闭环的最后一节。同时,神策数据依然坚持数据驱动的咨询服务,坚持以产品+服务的方式为客户创造价值。
二、数据根基:采、传、治、存、查、智 数据采集是一切数据应用的基础,在全新的SDAF运营框架之下,神策数据根基则从数据采集扩展成了整个数据流,包括采集、传输、治理、存储、查询、智能引擎这几个部分。下面将围绕其中几个重点部分,展开介绍。 1.数据采集 神策数据坚持开源策略,目前已开源40+SDK,不断完善SDK矩阵,覆盖主流开发生态。同时,整个SDK团队在Flutter全埋点、React Native全埋点、Kotlin全埋点、SwiftUI全埋点、APP与H5打通等方面都有了全新的技术突破。随着服务群体的扩大,神策团队也在支持更复杂场景的数据采集,比如如何去更加自动化地采集曝光数据?如何适配机顶盒车机等一些终端?同时也在尝试一些更便捷智能的采集方案,比如如何让事件属性能够做动态的可视化关联?如何让整个数据采集工作变得更加场景化、行业化、智能化?在全新的产品战略下,神策采集的数据已经不再局限于用户行为数据,还包括各种私域、公域数据,同时,也会持续以产品化的方式,来优化解决数据采集方案。 2.数据治理 在数据治理方面,神策提出面向业务的“螺旋式”数据治理理念,将数据治理分为三个阶段:关注源头、关注波动、全面掌控。 第一阶段——关注源头。在建设数据的初期,重点关注数据的质量,强调从需求到测试按规范进行,保证源头安全大约可解决80%以上的问题。 第二阶段——关注波动。当业务越来越依赖于数据的准确性和实质性时,需要整个数据团队及时监控数据质量的变化,避免发生线上故障从而影响业务。 第三阶段——全面掌控。当业务越来越复杂、数据源越来越多,且各种运营动作对数据依赖程度较高时,需要整个业务团队和数据团队一起来关注数据质量。 神策针对特定的市场需求,推出了神策数据治理平台SDG,坚持以产品化的方式解决问题。 从日常统计结果可知,ID-Mapping相关问题的耗时可以占到一个数据处理项目的30%左右。早期,神策数据在ID-Mapping方面只支持一对一的映射,相当于一个注册ID只能跟一台设备ID进行关联。后来,神策数据可以支持一对多的ID-Mapping,即一个注册ID可以和多个设备ID进行关联,但需要离线地回溯修改历史数据。如今,神策数据已支持实时且一对多的ID-Mapping。
从日常统计结果可知,ID-Mapping相关问题的耗时可以占到一个数据处理项目的30%左右。早期,神策数据在ID-Mapping方面只支持一对一的映射,相当于一个注册ID只能跟一台设备ID进行关联。后来,神策数据可以支持一对多的ID-Mapping,即一个注册ID可以和多个设备ID进行关联,但需要离线地回溯修改历史数据。如今,神策数据已支持实时且一对多的ID-Mapping。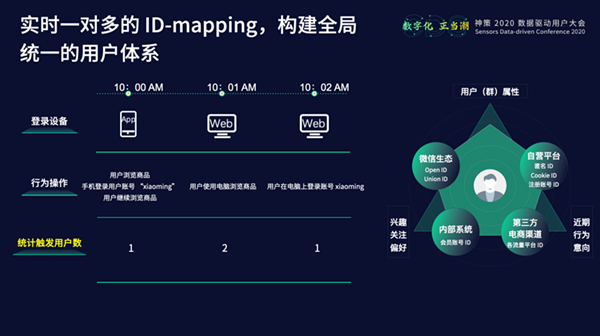 3.数据存储与查询 神策数据仓库,是团队基于业务进行的全新技术抽象。随着产品应用组件越来越多,团队将存储、查询、计算等会复用的抽象的数据处理能力组成了一个全新的技术组件,剥离了数据仓库层与数据应用层,将其称之为神策数据仓库(Sensors Data Warehouse),包含模型层、实现层、接口层三大层面。通过神策数据仓库,一方面,团队的应用开发变得更加简单,只需解决数据应用方面的问题,而无需考虑数据处理能力等方面的问题。另一方面,也尝试将神策数据仓库作为单独的产品组件对外开放。当然,神策数据仓库也不仅处理用户行为数据,不仅局限在支持Event-User-Item模型上,而是进一步扩展数据模型和处理的数据类型。
3.数据存储与查询 神策数据仓库,是团队基于业务进行的全新技术抽象。随着产品应用组件越来越多,团队将存储、查询、计算等会复用的抽象的数据处理能力组成了一个全新的技术组件,剥离了数据仓库层与数据应用层,将其称之为神策数据仓库(Sensors Data Warehouse),包含模型层、实现层、接口层三大层面。通过神策数据仓库,一方面,团队的应用开发变得更加简单,只需解决数据应用方面的问题,而无需考虑数据处理能力等方面的问题。另一方面,也尝试将神策数据仓库作为单独的产品组件对外开放。当然,神策数据仓库也不仅处理用户行为数据,不仅局限在支持Event-User-Item模型上,而是进一步扩展数据模型和处理的数据类型。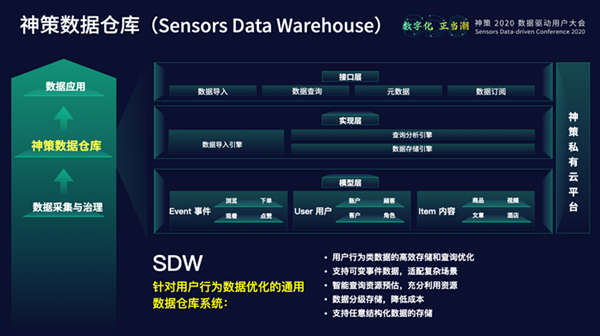 过去5年,神策持续优化存储与查询性能,从存储优化、查询执行优化、查询调度优化三方面的迭代优化出发,力争给用户带来更好的使用体验,降低客户的硬件使用成本。 4.数据智能引擎 数据根基的另一个重要组成部分则是神策智能引擎。早期,神策团队更多强调个性化推荐产品,但其实在个性化推荐产品之外,智能引擎也在分析和营销等领域发挥着重要价值,无论是基于数据做决策,还是基于决策做出更好的经营和营销动作,算法与数据智能都有其用武之地。目前,在包括预测、预警、LookAlike个性化等方面,神策整个算法团队已在很多不同的功能组件中尝试去探索算法的作用。神策的产品功能也逐渐开始与智能引擎进行结合,希望能够完成从“人用数据”到“人
过去5年,神策持续优化存储与查询性能,从存储优化、查询执行优化、查询调度优化三方面的迭代优化出发,力争给用户带来更好的使用体验,降低客户的硬件使用成本。 4.数据智能引擎 数据根基的另一个重要组成部分则是神策智能引擎。早期,神策团队更多强调个性化推荐产品,但其实在个性化推荐产品之外,智能引擎也在分析和营销等领域发挥着重要价值,无论是基于数据做决策,还是基于决策做出更好的经营和营销动作,算法与数据智能都有其用武之地。目前,在包括预测、预警、LookAlike个性化等方面,神策整个算法团队已在很多不同的功能组件中尝试去探索算法的作用。神策的产品功能也逐渐开始与智能引擎进行结合,希望能够完成从“人用数据”到“人








