

在过去的几年中,GraphQL已经成为一种非常流行的API规范,该规范专注于使客户端(无论客户端是前端还是第三方)的数据获取更加容易。
在传统的基于REST的API方法中,客户端发出请求,而服务器决定响应:
curl https://api.heroku.space/users/1
{ "id": 1,
"name": "Luke",
"email": "luke@heroku.space",
"addresses": [
{ "street": "1234 Rodeo Drive",
"city": "Los Angeles",
"country": "USA"
} ]}但是,在GraphQL中,客户端可以精确地确定其从服务器获取的数据。例如,客户端可能只需要用户名和电子邮件,而不需要任何地址信息:
curl -X POST https://api.heroku.space/graphql -d \'
query { user(id: 1) { name email }}{ "data":
{ "name": "Luke",
"email": "luke@heroku.space"
}}通过这种新的模式,客户可以通过缩减响应来满足他们的需求,从而向服务器进行更高效的查询。对于单页应用(SPA)或其他前端重度客户端应用,可以通过减少有效载荷大小来加快渲染时间。但是,与任何框架或语言一样,GraphQL也需要权衡取舍。在本文中,我们将探讨使用GraphQL作为API的查询语言的利弊,以及如何开始构建实现。
为什么选择GraphQL?
与任何技术决策一样,了解GraphQL为你的项目提供了哪些优势是很重要的,而不是简单地因为它是一个流行词而选择它。
考虑一个使用API连接到远程数据库的SaaS应用程序。你想要呈现用户的个人资料页面,你可能需要进行一次API GET 调用,以获取有关用户的信息,例如用户名或电子邮件。然后,你可能需要进行另一个API调用以获取有关地址的信息,该信息存储在另一个表中。随着应用程序的发展,由于其构建方式的原因,你可能需要继续对不同位置进行更多的API调用。虽然每一个API调用都可以异步完成,但你也必须处理它们的响应,无论是错误、网络超时,甚至暂停页面渲染,直到收到所有数据。如上所述,这些响应的有效载荷可能超过了渲染你当前页面的需要,而且每个API调用都有网络延迟,总的延迟加起来可能很可观。
使用GraphQL,你无需进行多个API调用(例如 GET /user/:id 和 GET /user/:id/addresses ),而是进行一次API调用并将查询提交到单个端点:
query {
user(id: 1) {
name
email
addresses {
street
city
country
} }}然后,GraphQL仅提供一个端点来查询所需的所有域逻辑。如果你的应用程序不断增长,你会发现自己在你的架构中添加了更多的数据存储——PostgreSQL可能是存储用户信息的好地方,而Redis可能是存储其他种类信息的好地方——对GraphQL端点的一次调用将解决所有这些不同的位置,并以他们所请求的数据响应客户端。
如果你不确定应用程序的需求以及将来如何存储数据,则GraphQL在这里也很有用。要修改查询,你只需添加所需字段的名称:
addresses {
street apartmentNumber # new information
city
country
}这极大地简化了随着时间的推移而发展你的应用程序的过程。

定义一个GraphQL schema
有各种编程语言的GraphQL服务器实现,但在你开始之前,你需要识别你的业务域中的对象,就像任何API一样。就像REST API可能会使用JSON模式一样,GraphQL使用SDL或Schema定义语言来定义它的模式,这是一种描述GraphQL API可用的所有对象和字段的幂等方式。SDL条目的一般格式如下:
type $OBJECT_TYPE {
$FIELD_NAME($ARGUMENTS): $FIELD_TYPE
}让我们以前面的例子为基础,定义一下user和address的条目是什么样子的。
type User {
name: String
email: String
addresses: [Address]}type Address {
street: String
city: String
country: String
}user 定义了两个 String 字段,分别是 name 和 email ,它还包括一个称为 addresses 的字段,它是 Addresses 对象的数组。 Addresses 还定义了它自己的几个字段。 (顺便说一下,GraphQL模式不仅有对象,字段和标量类型,还有更多,你也可以合并接口,联合和参数,以构建更复杂的模型,但本文中不会介绍。)
我们还需要定义一个类型,这是我们GraphQL API的入口点。你还记得,前面我们说过,GraphQL查询是这样的:
query {
user(id: 1) {
name
email
}}该 query 字段属于一种特殊的保留类型,称为 Query ,这指定了获取对象的主要入口点。(还有用于修改对象的 Mutation 类型。)在这里,我们定义了一个 user 字段,该字段返回一个 User 对象,因此我们的架构也需要定义此字段:
type Query {
user(id: Int!): User}type User { ... }
type Address { ... }字段中的参数是逗号分隔的列表,格式为 $NAME: $TYPE。! 是GraphQL表示该参数是必需的方式,省略表示它是可选的。
根据你选择的语言,将此模式合并到服务器中的过程会有所不同,但通常,将信息用作字符串就足够了。Node.js有 graphql 包来准备GraphQL模式,但我们将使用 graphql-tools 包来代替,因为它提供了一些更多的好处。让我们导入该软件包并阅读我们的类型定义,以为将来的开发做准备:
const fs = require(\'fs\')
const { makeExecutableSchema } = require("graphql-tools");
let typeDefs = fs.readFileSync("schema.graphql", {
encoding: "utf8",
flag: "r",
});设置解析器
schema设置了构建查询的方式,但建立schema来定义数据模型只是GraphQL规范的一部分。另一部分涉及实际获取数据,这是通过使用解析器完成的,解析器是一个返回字段基础值的函数。
让我们看一下如何在Node.js中实现解析器。我们的目的是围绕着解析器如何与模式一起操作来巩固概念,所以我们不会围绕着如何设置数据存储来做太详细的介绍。在“现实世界”中,我们可能会使用诸如knex之类的东西建立数据库连接。现在,让我们设置一些虚拟数据:
const users = {
1: {
name: "Luke",
email: "luke@heroku.space",
addresses: [
{
street: "1234 Rodeo Drive",
city: "Los Angeles",
country: "USA",
},
],
},
2: {
name: "Jane",
email: "jane@heroku.space",
addresses: [
{
street: "1234 Lincoln Place",
city: "Brooklyn",
country: "USA",
},
],
},
};Node.js中的GraphQL解析器相当于一个Object,key是要检索的字段名,value是返回数据的函数。让我们从初始 user 按id查找的一个简单示例开始:
const resolvers = {
Query: {
user: function (parent, { id }) {
// 用户查找逻辑
},
},
}这个解析器需要两个参数:一个代表父的对象(在最初的根查询中,这个对象通常是未使用的),一个包含传递给你的字段的参数的JSON对象。并非每个字段都具有参数,但是在这种情况下,我们将拥有参数,因为我们需要通过用户ID来检索其用户。该函数的其余部分很简单:
const resolvers = {
Query: {
user: function (_, { id }) {
return users[id];
}, }}你会注意到,我们没有明确定义 User 或 Addresses 的解析器,graphql-tools 包足够智能,可以自动为我们映射这些。如果我们选择的话,我们可以覆盖这些,但是现在我们已经定义了我们的类型定义和解析器,我们可以建立我们完整的模式:
const schema = makeExecutableSchema({ typeDefs, resolvers });运行服务器
最后,让我们来运行这个demo吧!因为我们使用的是Express,所以我们可以使用 express-graphql 包来暴露我们的模式作为端点。该程序包需要两个参数:schema和根value,它有一个可选参数 graphiql,我们将稍后讨论。
使用GraphQL中间件在你喜欢的端口上设置Express服务器,如下所示:
const express = require("express");
const express_graphql = require("express-graphql");
const app = express();
app.use( "/graphql",
express_graphql({ schema: schema, graphiql: true,
}));app.listen(5000, () => console.log("Express is now live at localhost:5000"));将浏览器导航到 http://localhost:5000/graphql,你应该会看到一种IDE界面。在左侧窗格中,你可以输入所需的任何有效GraphQL查询,而在右侧你将获得结果。
这就是 graphiql: true 所提供的:一种方便的方式来测试你的查询,你可能不想在生产环境中公开它,但是它使测试变得容易得多。
尝试输入上面展示的查询:
query {
user(id: 1) {
name
email
}}要探索GraphQL的类型化功能,请尝试为ID参数传递一个字符串而不是一个整数。
# 这不起作用
query {
user(id: "1") {
name
email
}}你甚至可以尝试请求不存在的字段:
# 这不起作用
query {
user(id: 1) {
name
zodiac
}}只需用schema表达几行清晰的代码,就可以在客户机和服务器之间建立强类型的契约。这样可以防止你的服务接收虚假数据,并向请求者清楚地表明错误。
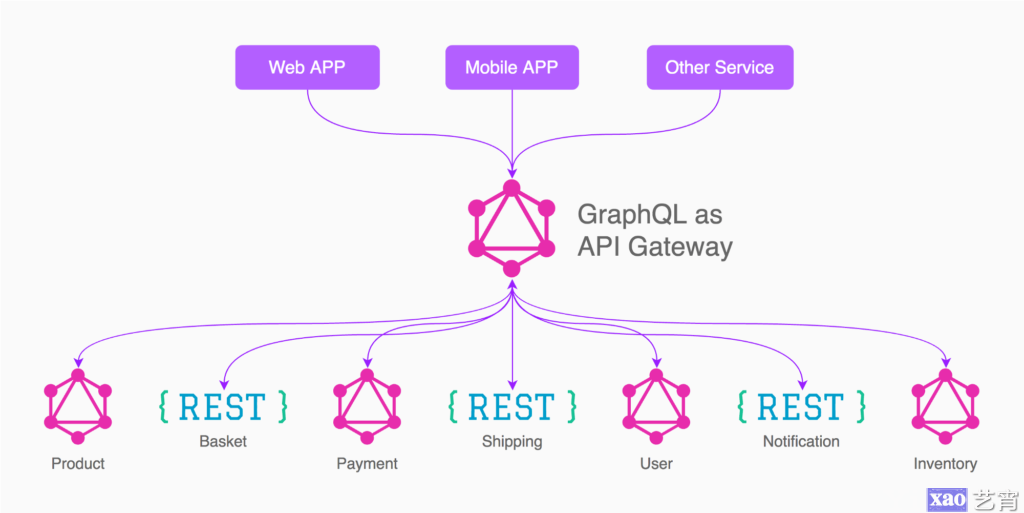
性能考量
尽管GraphQL为你解决了很多问题,但它并不能解决构建API的所有固有问题。特别是缓存和授权这两个方面,只是需要一些预案来防止性能问题。GraphQL规范并没有为实现这两种方法提供任何指导,这意味着构建它们的责任落在了你身上。
/ 缓存 /
基于REST的API在缓存时不需要过度关注,因为它们可以构建在web的其他部分使用的现有HTTP头策略之上。GraphQL不具有这些缓存机制,这会对重复请求造成不必要的处理负担。考虑以下两个查询:
query {
user(id: 1) {
name
}}query {
user(id: 1) {
email
}}在没有某种缓存的情况下,只是为了检索两个不同的列,会导致两个数据库查询来获取ID为 1 的 User。实际上,由于GraphQL还允许使用别名,因此以下查询有效,并且还执行两次查找:
query {
one: user(id: 1) {
name } two: user(id: 2) {
name }}第二个示例暴露了如何批处理查询的问题。为了快速高效,我们希望GraphQL以尽可能少的往返次数访问相同的数据库行。
dataloader程序包旨在解决这两个问题。给定一个ID数组,我们将一次性从数据库中获取所有这些ID;同样,后续对同一ID的调用也将从缓存中获取该项目。要使用 dataloader 来构建这个,我们需要两样东西。首先,我们需要一个函数来加载所有请求的对象。在我们的示例中,看起来像这样:
const DataLoader = require(\'dataloader\');
const batchGetUserById = async (ids) => {
// 在现实生活中,这将是数据库调用
return ids.map(id => users[id]);
};
// userLoader现在是我们的“批量加载功能”
const userLoader = new DataLoader(batchGetUserById);这样可以解决批处理的问题。要加载数据并使用缓存,我们将使用对 load 方法的调用来替换之前的数据查找,并传入我们的用户ID:
const resolvers = {
Query: {
user: function (_, { id }) {
return userLoader.load(id);
}, },}/ 授权 /
对于GraphQL来说,授权是一个完全不同的问题。简而言之,它是识别给定用户是否有权查看某些数据的过程。我们可以想象一下这样的场景:经过认证的用户可以执行查询来获取自己的地址信息,但应该无法获取其他用户的地址。
为了解决这个问题,我们需要修改解析器函数。 除了字段的参数外,解析器还可以访问它的父节点,以及传入的特殊上下文值,这些值可以提供有关当前已认证用户的信息。因为我们知道地址是一个敏感字段,所以我们需要修改我们的代码,使对用户的调用不只是返回一个地址列表,而是实际调用一些业务逻辑来验证请求:
const getAddresses = function(currUser, user) {
if (currUser.id == user.id) {
return user.addresses
} return [];
}const resolvers = {
Query: {
user: function (_, { id }) {
return users[id];
}, }, User: {
addresses: function (parentObj, {}, context) {
return getAddresses(context.currUser, parentObj);
}, },};同样,我们不需要为每个 User 字段显式定义一个解析程序,只需定义一个我们要修改的解析程序即可。
默认情况下,express-graphql 会将当前的HTTP请求作为上下文的值来传递,但在设置服务器时可以更改:
app.use(
"/graphql",
express_graphql({ schema: schema,
graphiql: true,
context: {
currUser: user // 当前经过身份验证的用户
} }));Schema最佳实践
GraphQL规范中缺少的一个方面是缺乏对版本控制模式的指导。随着应用程序的成长和变化,它们的API也会随之变化,很可能需要删除或修改GraphQL字段和对象。但这个缺点也是积极的:通过仔细设计你的GraphQL schema,你可以避免在更容易实现(也更容易破坏)的REST端点中明显的陷阱,如命名的不一致和混乱的关系。
此外,你应该尽量将业务逻辑与解析器逻辑分开。你的业务逻辑应该是整个应用程序的单一事实来源。在解析器中执行验证检查是很有诱惑力的,但随着模式的增长,这将成为一种难以维持的策略。
GraphQL什么时候不合适?
GraphQL不能像REST一样精确地满足HTTP通信的需求。例如,无论查询成功与否,GraphQL仅指定一个状态码——200 OK。在这个响应中会返回一个特殊的错误键,供客户端解析和识别出错的地方,因此,错误处理可能会有些棘手。
同样,GraphQL只是一个规范,它不会自动解决你的应用程序面临的每个问题。性能问题不会消失,数据库查询不会变得更快,总的来说,你需要重新思考关于你的API的一切:授权、日志、监控、缓存。版本化你的GraphQL API也可能是一个挑战,因为官方规范目前不支持处理中断的变化,这是构建任何软件不可避免的一部分。如果你有兴趣探索GraphQL,你需要投入一些时间来学习如何将其与你的需求进行最佳整合。
了解更多
社区围绕这个新范例聚集,并为前端和后端工程师提供了很棒的GraphQL资源列表。前端和后端工程师都可以使用。你也可以通过在官方的游乐场上提出真实的请求来查看查询和类型是什么样子的。
我们还有一个Code[ish]播客集,专门介绍GraphQL的好处和成本。
很棒的GraphQL资源列表:https://github.com/chentsulin/awesome-graphql
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/11491.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
用python把linux命令写一遍的人处于编程的什么水平?
如何提升自己的 python 能力呢?直接找项目写,但是作为零基础 / 小白 / 入门 的你来说做一个博客还要学 web 框架、html、css、js,又成为了阻碍你写实际项目的阻…
-
HashOver免费开源PHP评论系统安装使用-自建评论系统替代第三方
说到国内的社会化评论系统,就不得不提多说、灯鹭、友言、评论啦、网易云跟贴、搜狐畅言这几个有代表性的服务了。几年前正是社会化评论流行的时候,放着Wordpress等程序自带的评论系统…
-
JavaScript,ES5,ES6,ES7,ES8及ES6(ES2015)的基本语法
ECMAScript JavaScript语言的下一代标准,已于2015年6月正式发布,其目标,是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。 …
-
使用uniapp从构建到上线开发微信小程序
前言: 本文主要介绍 uniapp 的基础使用,以及使用 uniapp 在企业开发的过程中的一个详细流程,比较适合第一次使用uniapp 开发微信小程序的伙伴,或者没有过实战经验的…
-
Day.js:轻量化的 Javascript 时间日期库
近日,Moment.js 宣布项目正式进入维护阶段。这意味着,这个最受欢迎的 Javascript 时间日期库,已经不会再添加新功能,也不会进行任何重大更改,并可能选择不修复项目中…
-
PHP框架选Laravel还是Codeigniter?
Laravel大而全,什么都有,也正因为如此,反而会显得笨重,而且代码执行效率会低一点,Codeigniter相较于Laravel来说,就很轻量了,同时一些常用的功能也都有。 La…
-
JavaScript程序员必须搞明白的伪类
什么是伪类? 伪类对元素进行分类是基于特征(characteristics)而不是它们的名字、属性或者内容;原则上特征是不可以从文档树上推断得到的。 伪类有::first-chil…
-
Vue前端开发之表单封装
效果图片 动态表单和子表单 upholdjx/tao-form 简介: 基于 Vue 和 ElementUI 构建的form表单和子表单动态构建,具有动态渲染,参数校验,数据双向绑…