前言
如今的京东、淘宝、天猫等等已经不同往日了, 在用户不登录的情况下, 很难通过技术手段来大规模获取到我们关注的商品信息. 关于京东等购物网站的自动登录也有很多人在做, 但是大厂的反爬能力确实很强, 目前能查阅到的自动登录技术基本都过时了. 本文干脆跳过这一过程, 换一个思路.
在不登录的情况下获取商品的编号
我们登录京东的网址jd.com后可以在不登录的情况下直接搜索商品, 比如搜索手机
安装与使用
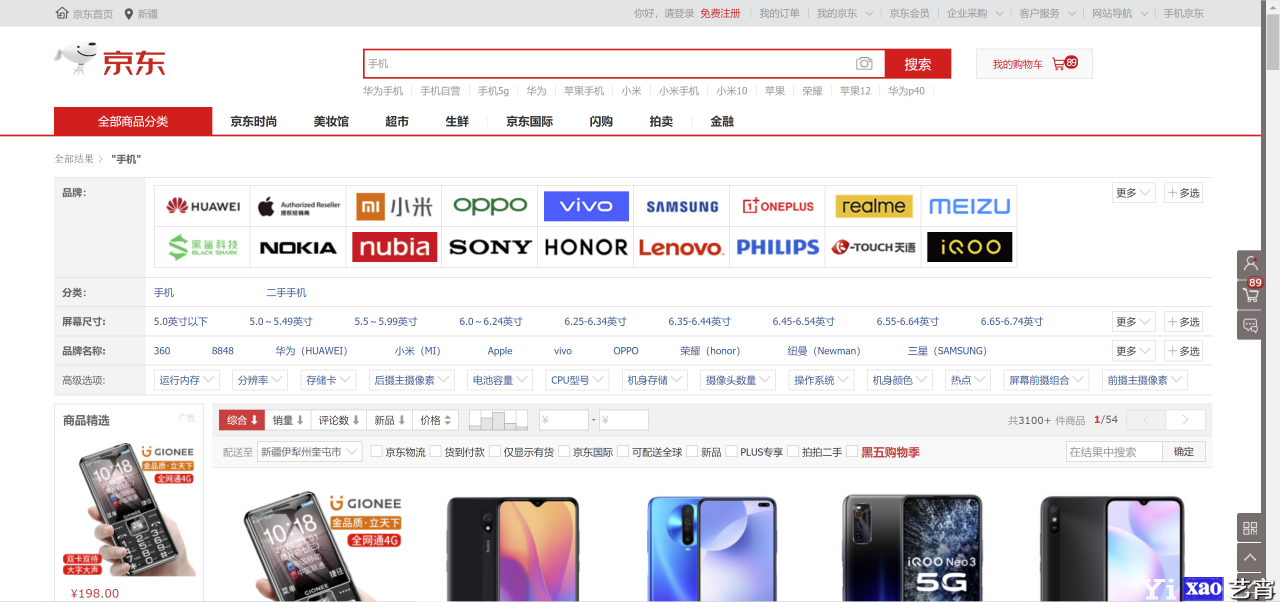

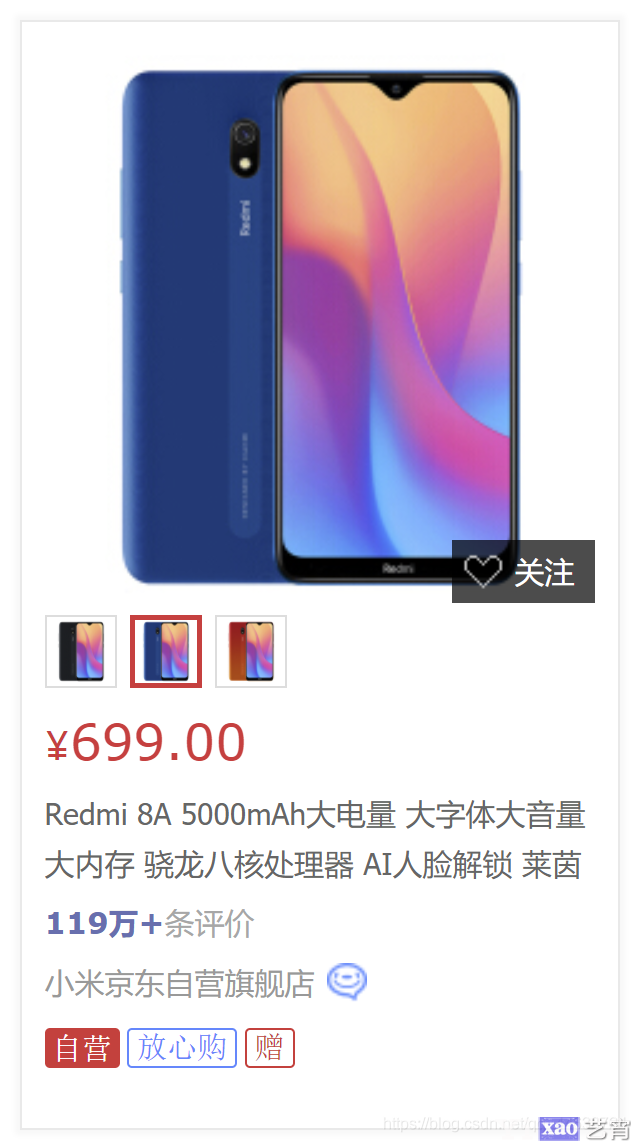
可以看到, 其实这一页面就已经列出商品的名称, 售价, 评价量等等. 遗憾的是这个页面的内容不能直接爬取, 但是我们点开其中一个商品, 并找到它的商品介绍

不难发现, 不同的设备在型号、参数、性能上可能会存在着重复,但是在京东商城的商品编号是唯一的, 更方便的一点是, 商品编号就是这一商品的url. 例如上述小米手机的地址为https://item.jd.com/100009082500.html. 那么我们一旦获取了足够多的商品编号后就可以对手机的信息进行爬取了. 接下来我们分析商品列表页面中是否保存着商品编号信息.
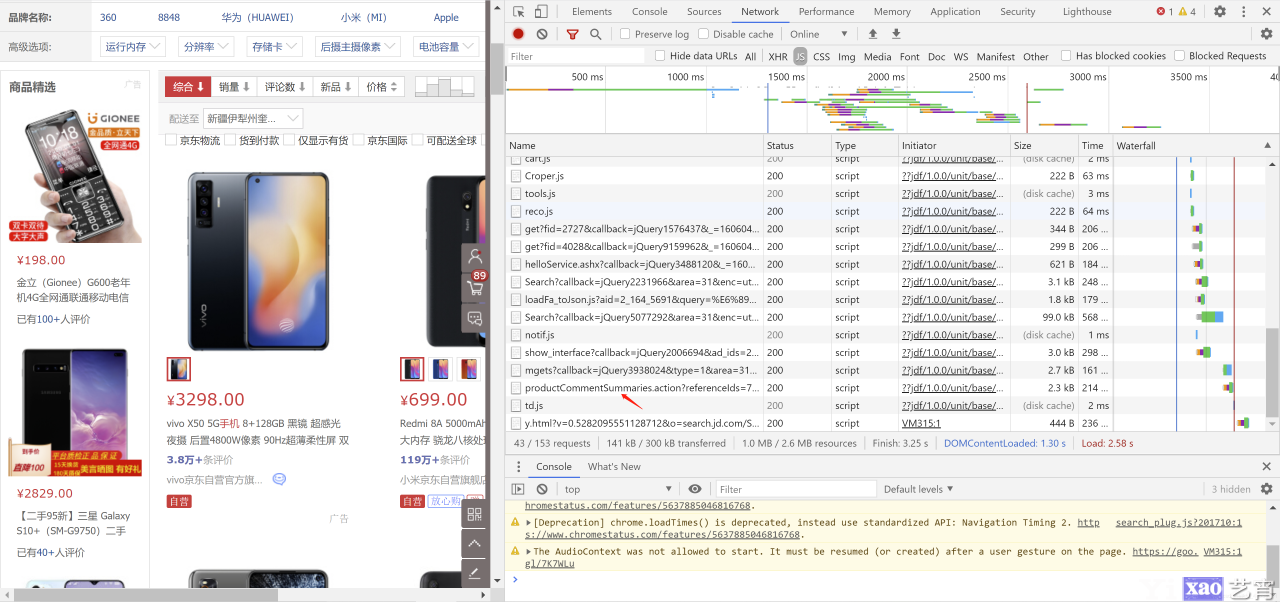
我们打开开发者工具, 选择Network, 可以很容易的发现一条信息, productcommentsummaries, 那么它很有可能会包含商品的编号.
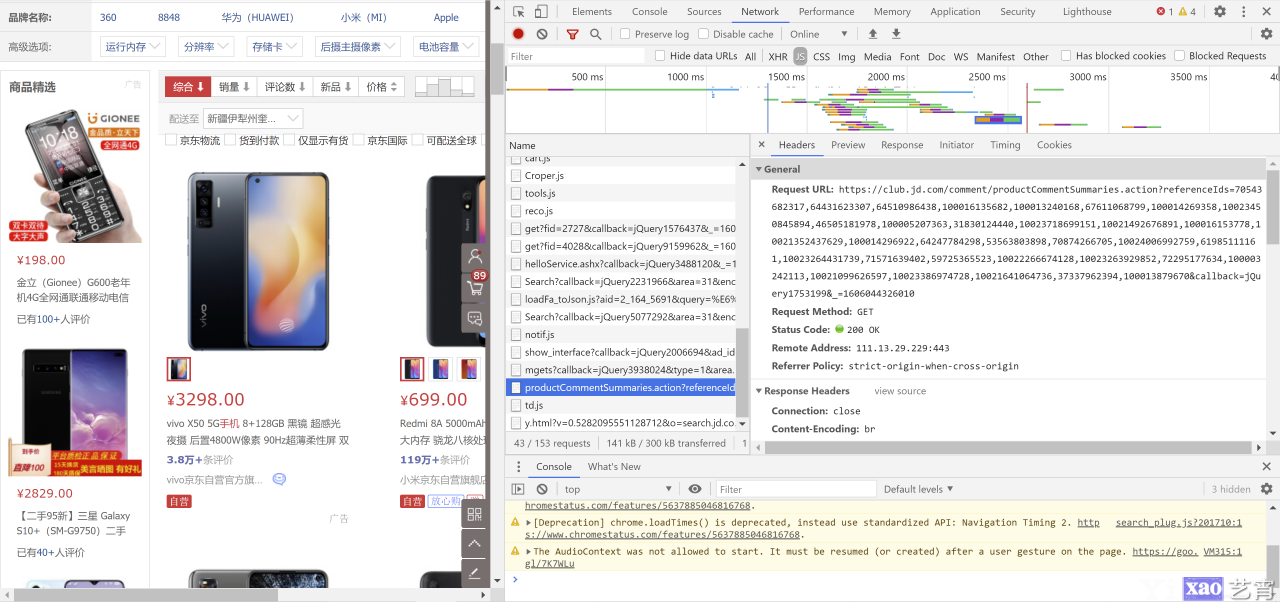
进一步打开它可以发现有很多数字串, 其实这些就是在keyword=手机条件下的商品编号, 如果我们需要大规模爬取, 可以手动多点几页, 就获取很多这样的内容. 为进行测试, 本文截取了少量编号
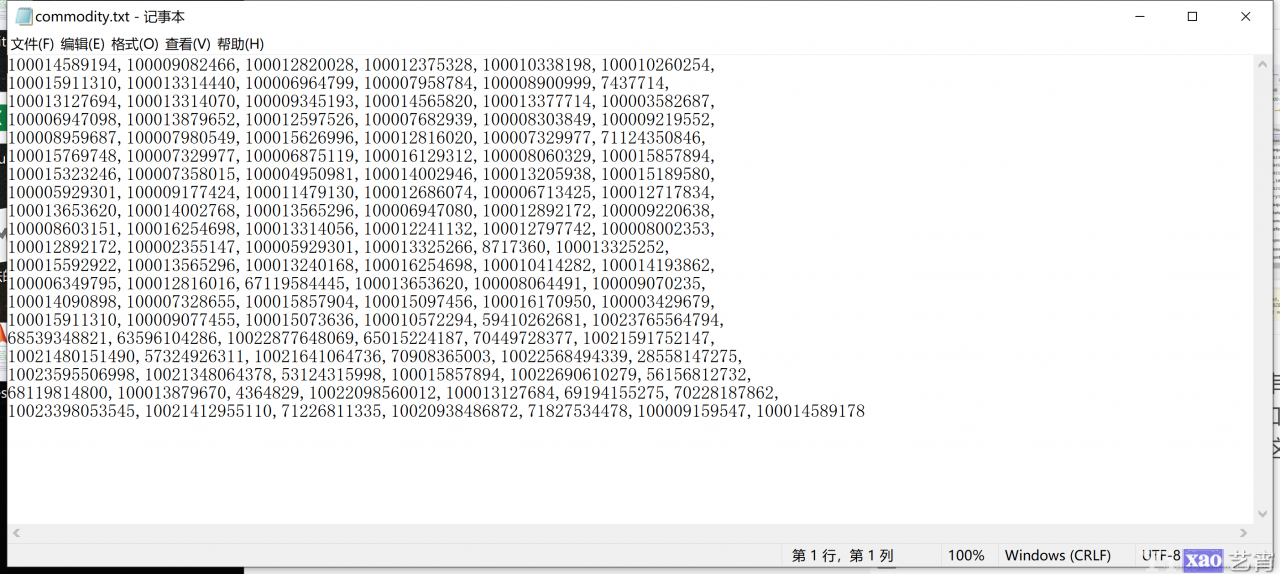
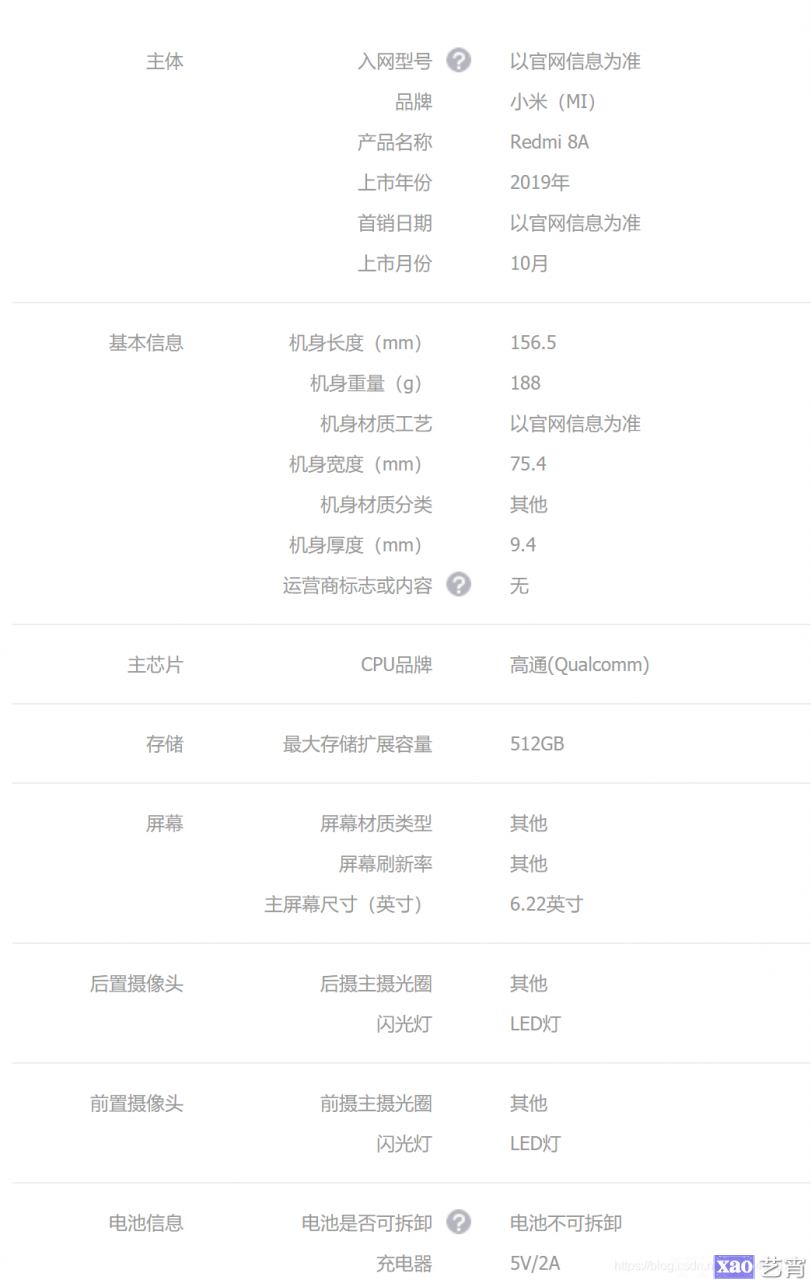
一旦获取了商品编号, 那么商品的信息就很好获取了, 假如我们想要获取某一款手机的详细配置, 如下图
可以尝试如下的代码, 先通过简单的读取txt文件将单一的商品编号转变为可访问的url
import csv
import pandas as pd
import time
import os
import requests
from bs4 import BeautifulSoup
def get_url(dir):
commo_list = []
List = []
col = 0
with open(dir,"r") as f:
for line in f.readlines():
line = line.strip("\n")
List = list(eval(line))
col = col 1
print("第{0}行".format(col))
for i in range(len(List)):
commo_list.append(List[i])
print(line)
print("---商品编号总计:{0}个---".format(len(commo_list)))
return commo_list
dir = \'D:/Desktop/commodity.txt\'
commodity_list = get_url(dir)
123456789101112131415161718192021222324252627结果如下
通过request库来获取url
def get_page(commo):
page_list = []
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36\'
} #定义头部
#https://item.jd.com/100014589194.html http example
#for i in range(len(commo)): #设定爬取量
for i in range(10): #为提高效率, 本示例中仅爬取10个商品
url = "https://item.jd.com/" str(commo[i]) ".html"
page = requests.get(url,headers=headers)
print("第{0}个页面状态码:{1}".format(i,page.status_code))
time.sleep(1.5) #程序挂起, 防止反爬虫
#page = requests.get()
page_list.append(page)
print("获取完毕")
return page_list
#Page = get_page(commodity_list)
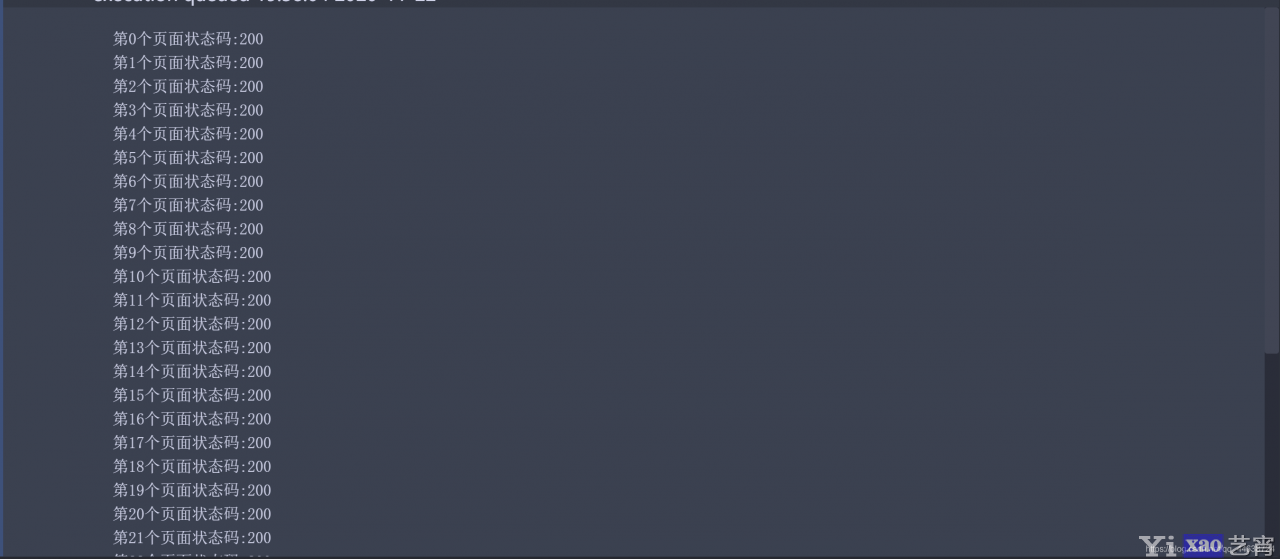
123456789101112131415161718192021在代码运行的过程中加入页面的状态码, 这样可以很快的向我们反映哪些地址被成功访问了, 而哪些没有. 同时引入time.sleep()函数能够有效的防止因访问过快而被封ip. 运行结果如下
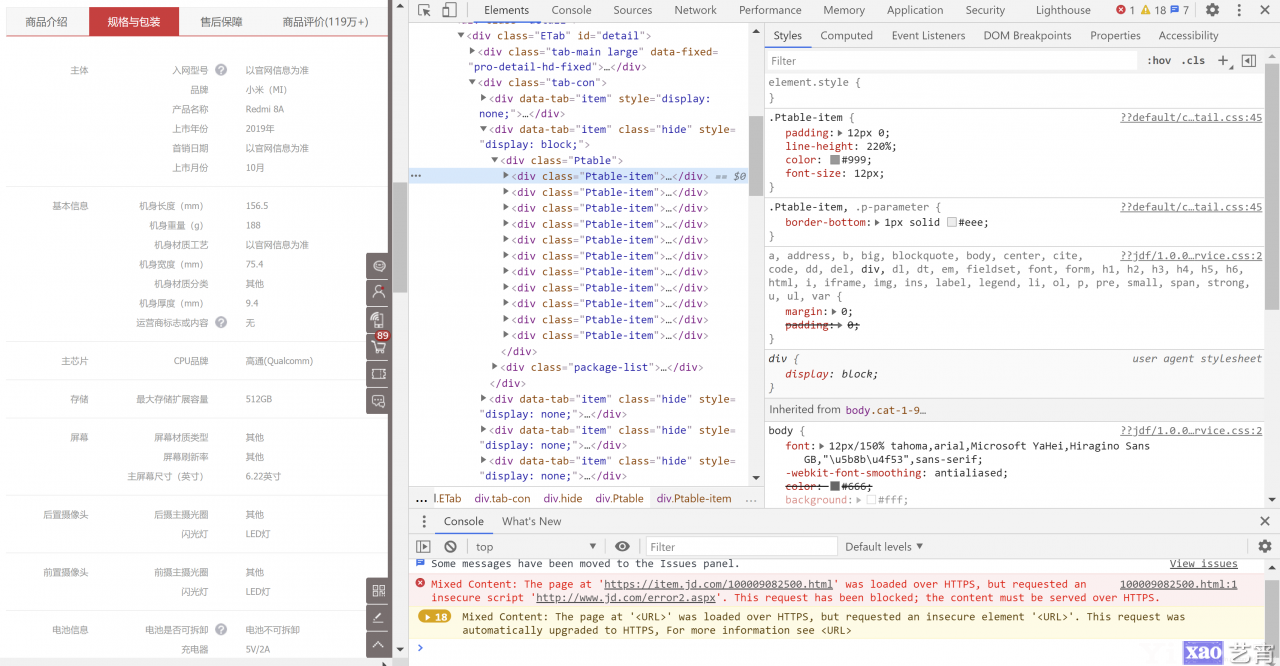
通过简单的查看手机相信相信页的标签结果, 很容易能发现这些有价值的信息都被存在div:class=Ptable-item标签中
用BeautifulSoup库解析页面
def analysis_page(analysis, head):
Soup = []
Dt = []
Dd = []
Div = []
Dl = []
DD = []
DT = []
pro = 1
for i in range(len(analysis)):
soup = BeautifulSoup(analysis[i].text,"html.parser")
#print(soup)
div = soup.find_all(\'div\',attrs={"class":[\'Ptable-item\']}) #返回div为列表
print(div)
Dt = []
Dd = []
for ll in div:
dl = ll.find_all(\'dl\',{\'class\':[\'clearfix\']})
for i in range(len(dl)):
if dl[i].dd.attrs == {\'class\': [\'Ptable-tips\']}:
#print(dl[i].dt.text, ":", dl[i].dd.next_sibling.next_sibling.string)
Dt.append(dl[i].dt.text)
Dd.append(dl[i].dd.next_sibling.next_sibling.string)
else:
#print(dl[i].dt.string, ":", dl[i].dd.string)
Dt.append(dl[i].dt.string)
Dd.append(dl[i].dd.string)
DT.append(Dt)
DD.append(Dd)
print("\r" "{0:.2f}".format(pro/len(analysis)),end = "")
pro = pro 1
return Dl, DT, DD
result = analysis_page(Page, 2)
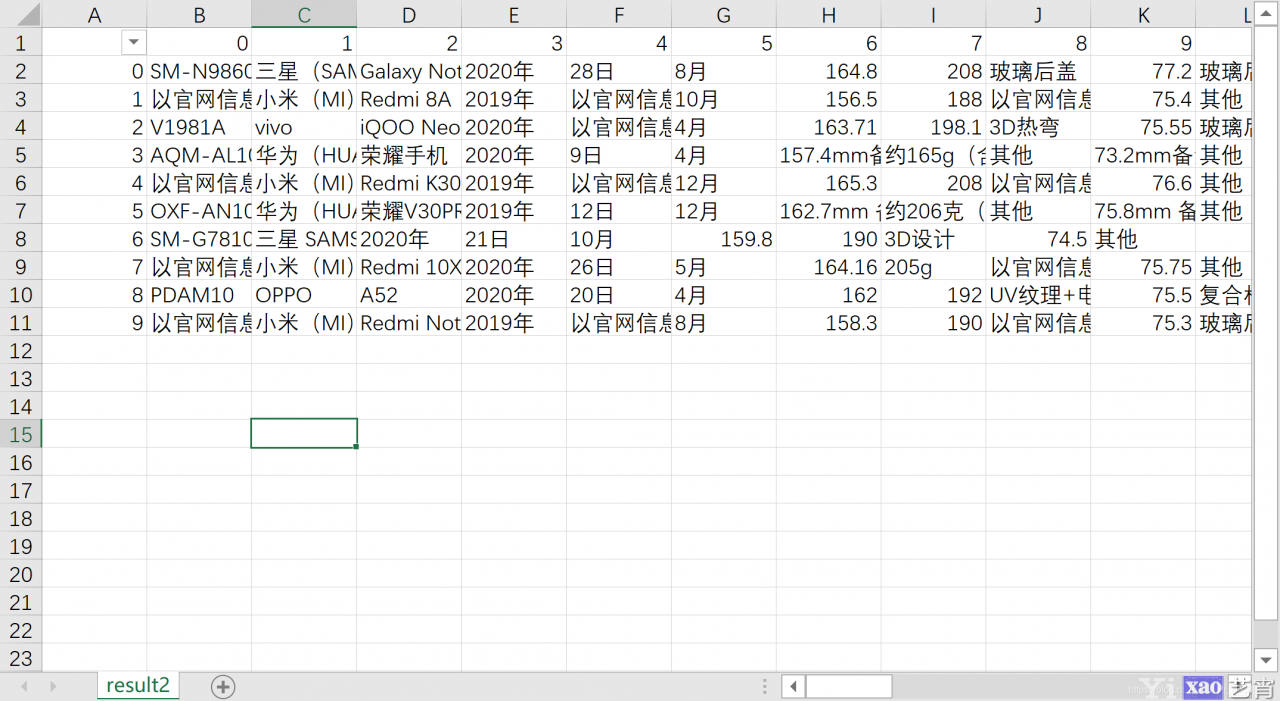
123456789101112131415161718192021222324252627282930313233343536373839这样, div标签中的信息就被保存到result中了, 我们来查看一下
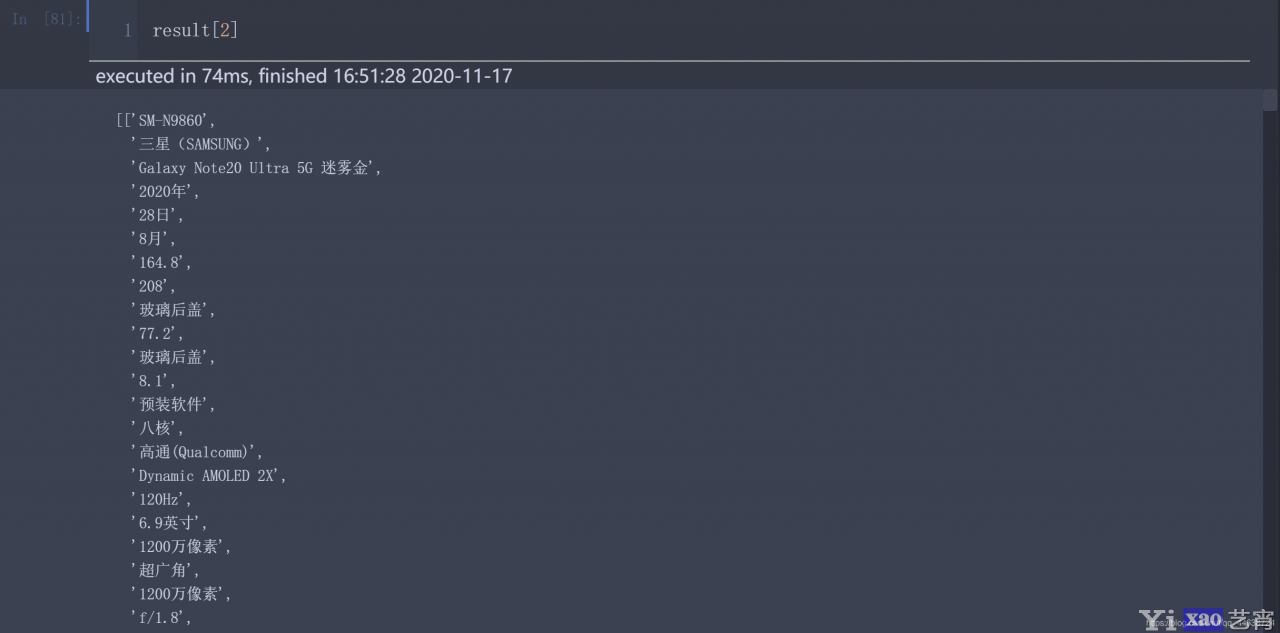
商品信息显示正常没有乱码, 也没有冗余信息
保存为CSV格式
df = pd.DataFrame(result[2])
df.replace("\n",\'\',inplace=True,regex=True)
df.to_csv("D://Desktop/result2.csv")
123但从保存的结果来看, 似乎程序的输出是正常的, 但csv文件却显示不正常

可以通过如下办法解决:
1.用记事本打开

2.另存为带有BOM的UTF-8文件
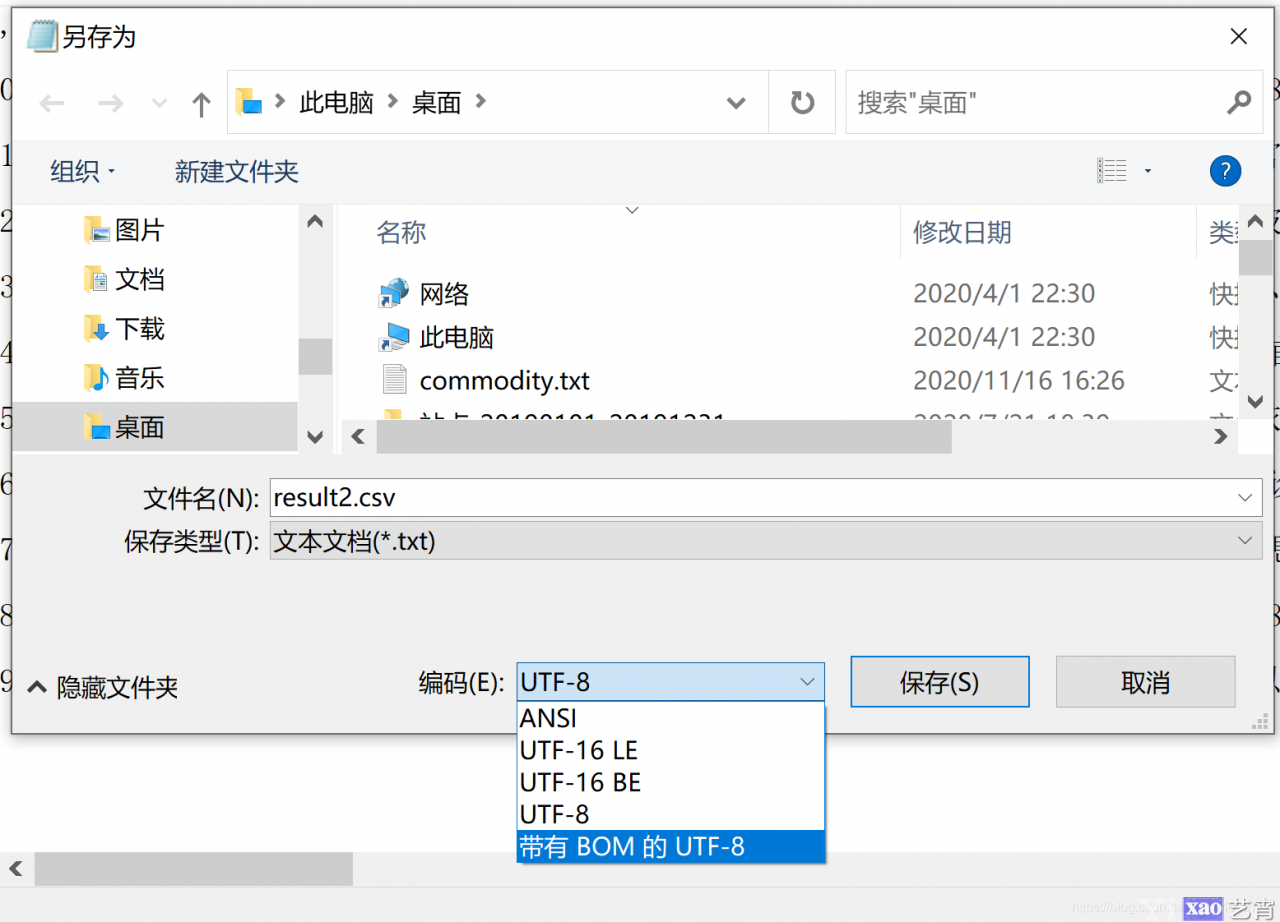
3. 再次打开csv文件

可以看到中文显示正常了, 但其中穿插着很多的空行. 解决办法:选中第一列后点击筛选
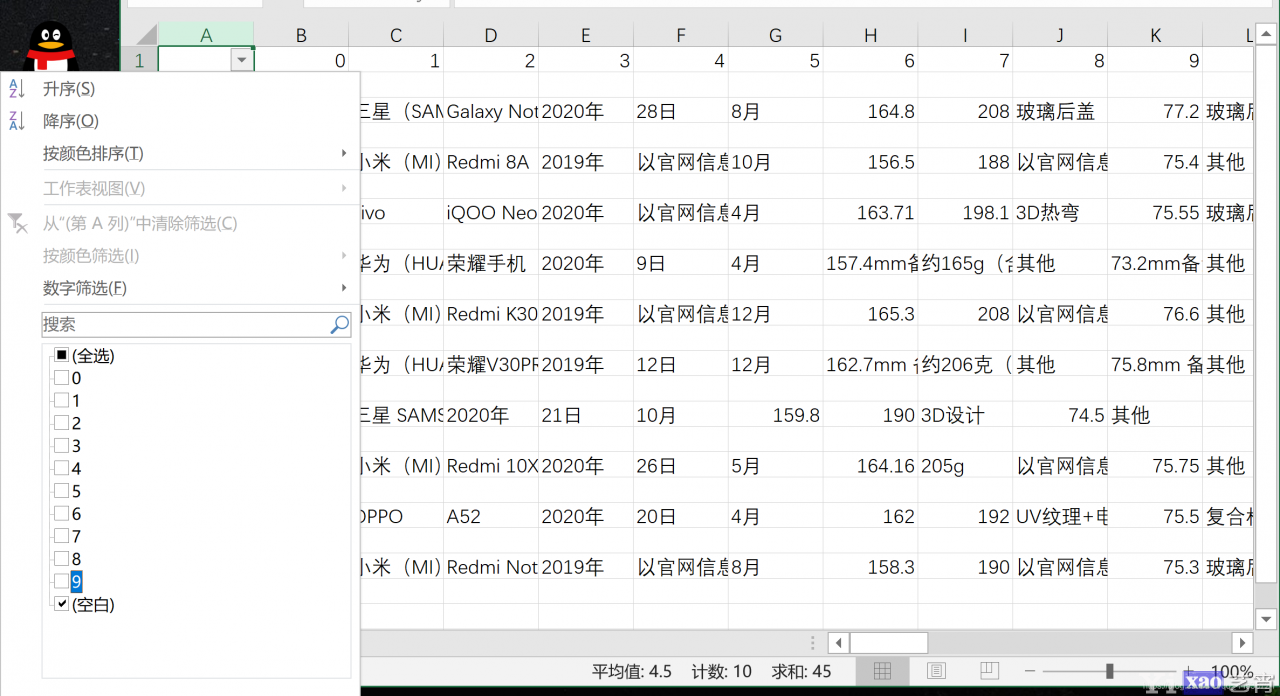
只选中空白行
此时可以看到空白行已经用蓝色标识出, 将其删除即可
一些思考
实际上, 本文的代码效率并不高, 再加上反爬虫需要对程序挂起就更消耗时间和内存, 还需要进一步考虑多线程爬虫和提高代码效率.
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/15516.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
11段好用的CSS代码
本文分享一些非常好用的CSS代码片段,它们很短但功能强大。使用这些代码,我们可以立即提高网站的体验。下面是11个非常好用的CSS代码片段: 1. Scroll behavior平滑…
-
JavaScript,ES5,ES6,ES7,ES8及ES6(ES2015)的基本语法
ECMAScript JavaScript语言的下一代标准,已于2015年6月正式发布,其目标,是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。 …
-
网站开发新手学习PHP计划
我的这套线路可能跟许多学习PHP的爱好者不谋而合,这也算是一个循序渐进的学习过程,不过新手不要看到上面的概括就以为学习蛮简单的,默默在此不得不对您稍微泼一下冷水,任何东西其实都不简单,即使是小吃部的烧饼也不是一下子就会做成的。
-
MySQL全文索引、联合索引、like查询、json查询速度大比拼
查询背景 有一个表tmp_test_course大概有10万条记录,然后有个json字段叫outline,存了一对多关系(保存了多个编码,例如jy1577683381775) 我们…
-
Niushop开源商城系统表单搭建
表单搭建,是商城系统触发按钮的重要模块之一,有工整详细的表单,不仅能让页面更加美观大气,还可以让后台代码更加规整与规范,方便及时查漏或者商家再次二开! 表单label宽度 layu…
-
前端设计人员如何提高写前端的效率?
我们在写前端的时候,面对重复代码的时候,很多时候就会复制粘贴,实际上可以通过技巧来提高写前端的效率。接下来将介绍几个常用的提高效率的技巧注释 输入以下代码 Ctrl / 另外,取消…
-
vuex里面的四大金刚:State,Mutations,Actions,Getters
vuex里面的四大金刚:State, Mutations,Actions,Getters 1.State—–声明一个state:vuex的状态管理,需要依赖…
-
解决 wordpress 发布时间显示提前8小时的办法
刚刚发了一篇文章,瞅了一眼,时间显示是8小时前,什么鬼?我穿越到过去了?以前就遇到过了,不过一直懒得处理,今天就处理下吧,顺便记录下。 第一检查了仪表盘 – 设置 -常规,时区设置…
-
用python抓取小仙女2000+条微博后做的简单分析
动机 某天小仙女翻她微博发照片给我看,我打开她的微博,我的天,2000多条。刚好最近在做NLP相关的工作,需要爬各种数据,于是萌生了把小仙女微博爬下来看看的想法。(坑比微博不开放接…