静态网页实战
为大家展现一个完整爬虫的大致过程,此次项目内容为提取猫眼电影TOP100榜中的所有电影信息并存储至CSV文件中,其首页地址为http://maoyan.com/board/4。我们可以编写一个获取每页数据函数,接收参数就是页码数:
import requests
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36\'
}
# 偏移参数,默认为0,即为第一页
params = {
\'offset\': 0
}
def get_html(page):
\'\'\'
获取一页html页面
:param page: 页数
:return: 该页html页面
\'\'\'
params[\'offset\'] = page * 10
url = \'http://maoyan.com/board/4\'
try:
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
html = response.text
return html
else:
return -1
except:
return None当我们获取到html页面后,就可以提取相应的电影信息了,比如榜单张每一项电影都会有的属性:电影名称,主演,上映时间,评分等信息。提取信息有多种方式,下面我们利用正则表达式提取电影信息:
def parse_infor(html):
\'\'\'
提取html页面中的电影信息
:param html: html页面
:return: 电影信息列表
\'\'\'
# 编写正则字符串规则,提取 电影名,主演,上映时间,评分信息
pat = re.compile(\'.*?<div.*?>.*?<p.*?><i.*?>(.*?)<i.*?>(.*?).*?.*?.*?\', re.S)
# 得到一个二重列表
results = re.findall(pat, html)
one_page_film = []
if results:
for result in results:
film_dict = {}
# 获取电影名信息
film_dict[\'name\'] = result[0]
# 获取主演信息
start = result[1]
# 替换字符串中的 \'\n\' 字符,即换行字符
start.replace(\'\n\', \'\')
# 去掉字符串两边的空格,并使用切片去除字符串开头的\'主演:\'三个字符
start = start.strip()[3:]
film_dict[\'start\'] = start
# 获取上映时间信息
releasetime = result[2]
# 使用切片去除字符串开头的\'上映时间:\'五个字符
releasetime = releasetime[5:]
film_dict[\'releasetime\'] = releasetime
# 获取评分信息,由于评分是有两个字符拼接的,这里我们提取后也需要进行拼接操作
left_half =result[3]
right_half = result[4]
score = left_half right_half
film_dict[\'score\'] = score
# 打印该电影信息:
print(film_dict)
# 将该电影信息字典存入一页电影列表中
one_page_film.append(film_dict)
return one_page_film
else:
return None不熟悉正则读者要好好复习下前面的知识,虽然正则写起来可能会麻烦些,当时他的提取效率是最高的,接下来我们就可以将提取好的电影信息进行存储操作,这里我们存储为CSV文件:
def save_infor(one_page_film):
\'\'\'
存储提取好的电影信息
:param html: 电影信息列表
:return: None
\'\'\'
with open(\'top_film.csv\', \'a\', newline=\'\') as f:
csv_file = csv.writer(f)
for one in one_page_film:
csv_file.writerow([one[\'name\'], one[\'start\'], one[\'releasetime\'], one[\'score\']])以上是获取一页html页面并提取电影信息存储至CSV中的过程,接下来我们构造十页的URL便可以完成猫眼电影TOP100榜中的所有电影信息的获取和存储了,以下是完整程序:
import requests
import re
import csv
import time
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36\'
}
params = {
\'offset\': 0
}
def get_html(page):
\'\'\'
获取一页html页面
:param page: 页数
:return: 该页html页面
\'\'\'
params[\'offset\'] = page * 10
url = \'http://maoyan.com/board/4\'
try:
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
html = response.text
return html
else:
return -1
except:
return None
def parse_infor(html):
\'\'\'
提取html页面中的电影信息
:param html: html页面
:return: 电影信息列表
\'\'\'
pat = re.compile(\'.*?<div.*?>.*?<p.*?><i.*?>(.*?)<i.*?>(.*?).*?.*?.*?\', re.S)
results = re.findall(pat, html)
one_page_film = []
if results:
for result in results:
film_dict = {}
# 获取电影名信息
film_dict[\'name\'] = result[0]
# 获取主演信息
start = result[1]
# 替换字符串中的 \'\n\' 字符,即换行字符
start.replace(\'\n\', \'\')
# 去掉字符串两边的空格,并使用切片去除字符串开头的\'主演:\'三个字符
start = start.strip()[3:]
film_dict[\'start\'] = start
# 获取上映时间信息
releasetime = result[2]
# 使用切片去除字符串开头的\'上映时间:\'五个字符
releasetime = releasetime[5:]
film_dict[\'releasetime\'] = releasetime
# 获取评分信息
left_half =result[3]
right_half = result[4]
score = left_half right_half
film_dict[\'score\'] = score
# 打印该电影信息:
print(film_dict)
# 将该电影信息字典存入一页电影列表中
one_page_film.append(film_dict)
return one_page_film
else:
return None
def save_infor(one_page_film):
\'\'\'
存储提取好的电影信息
:param one_page_film: 电影信息列表
:return: None
\'\'\'
with open(\'top_film.csv\', \'a\', newline=\'\', errors=\'ignore\') as f:
csv_file = csv.writer(f)
for one in one_page_film:
csv_file.writerow([one[\'name\'], one[\'start\'], one[\'releasetime\'], one[\'score\']])
if __name__ == "__main__":
# 利用循环构建页码
for page in range(10):
# 请求页面
html = get_html(page)
if html:
# 提取信息
one_page_film = parse_infor(html)
if one_page_film:
# 存储信息
save_infor(one_page_film)
time.sleep(1)动态网页实战
本节我们将爬取猫眼电影实时票房数据,学会在动态网页中获取我们想要的数据,首先打开猫眼专业版-实时票房, 其网址为:https://piaofang.maoyan.com/dashboard,然后我们可以看见现在的实时电影票房数据,可以看见 “今日实时” 的数据在不断地动态增加:
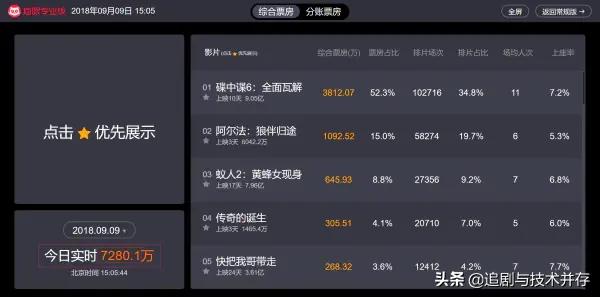

而当我们查看该网页源代码时,却并没有电影相关的票房等信息,那么可以判断该页面可能使用了Ajax(即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML))技术,即动态网页(是指跟静态网页相对的一种网页编程技术。静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变)。我们可以利用浏览器的开发者工具进行分析:
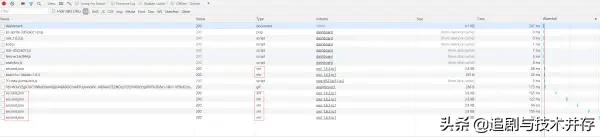
我们可以发现每隔一段时间都会有一个新的请求,其请求类型都为xhr,而Ajax的请求类型就是xhr,这请求可能就是实时更新的票房信息,而我们需要的数据可能就在这些文件里,于是我们选择一个进行分析:
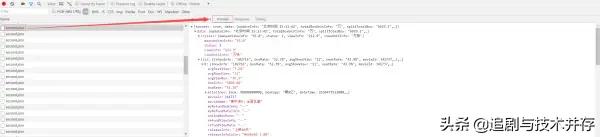
在Preview中,我们可以看见大量的电影相关的信息,即我们想要获取的实时电影票房数据,而这些内容是JSON格式的,浏览器开发者工具自动做了解析方便我们查看,接下来我们只需要用Python模拟这些Ajax请求,拿下这些数据然后解析即可,而这些Ajax无非依然是HTTP请求,所以只要拿到对应URL然后使用Python模拟该请求即可,我们可以直接复制,如下图:

获取到该请求的链接,接下来我们就用Python模拟该请求:
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36\'
}
def get_html():
\'\'\'
获取JSON文件
:return: JSON格式的数据
\'\'\'
# 请求second.json的URL
url = \'https://box.maoyan.com/promovie/api/box/second.json\'
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 由于是JSON文件,我们可以返回JSON格式的数据便于后续提取
return response.json()
else:
return -1
except:
return None获取对应的JSON数据后,我们就可以利用进行提取操作了。
def parse_infor(json):
\'\'\'
从JSON数据中提取电影票房数据,包括:电影名,上映信息,综合票房,票房占比,累计票房
:param json: JSON格式的数据
:return: 每次循环返回一次字典类型的电影数据
\'\'\'
if json:
# 利用json中的get()方法层层获取对应的信息
items = json.get(\'data\').get(\'list\')
for item in items:
piaofang = {}
piaofang[\'电影名\'] = item.get(\'movieName\')
piaofang[\'上映信息\'] = item.get(\'releaseInfo\')
piaofang[\'综合票房\'] = item.get(\'boxInfo\')
piaofang[\'票房占比\'] = item.get(\'boxRate\')
piaofang[\'累计票房\'] = item.get(\'sumBoxInfo\')
# 利用生成器每次循环都返回一个数据
yield piaofang
else:
return None读者可能看见我们没有使用常规的return进行函数返回,而是使用了生成器,这样就能每次循环都返回一次数据,具体读者可以生成器 | 廖雪峰的官方网站进一步了解学习,接下来我们就将提取好的票房信息存储为格式化的HTML文件:
def save_infor(results):
\'\'\'
存储格式化的电影票房数据HTML文件
:param results: 电影票房数据的生成器
:return: None
\'\'\'
rows = \'\'
for piaofang in results:
# 利用Python中的format字符串填充html表格中的内容
row = \'<tr><td>{}td><td>{}td><td>{}td><td>{}td><td>{}td>tr>\'.format(piaofang[\'电影名\'],
piaofang[\'上映信息\'],
piaofang[\'综合票房\'],
piaofang[\'票房占比\'],
piaofang[\'累计票房\'])
# 利用字符串拼接循环存储每个格式化的电影票房信息
rows = rows \'\n\' row
# 利用字符串拼接处格式化的HTML页面
piaofang_html = \'\'\'html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>电影票房title>
head>
<body>
<style>
.table1_5 table {
width:100%;
margin:15px 0
}
.table1_5 th {
background-color:#00BFFF;
color:#FFFFFF
}
.table1_5,.table1_5 th,.table1_5 td
{
font-size:0.95em;
text-align:center;
padding:4px;
border:1px solid #dddddd;
border-collapse:collapse
}
.table1_5 tr:nth-child(odd){
background-color:#aae9fe;
}
.table1_5 tr:nth-child(even){
background-color:#fdfdfd;
}
style>
<table class=\'table1_5\'>
<tr>
<th>电影名th>
<th>上映信息th>
<th>综合票房th>
<th>票房占比th>
<th>累计票房th>
tr>
\'\'\' rows \'\'\'
table>
body>
html>
\'\'\'
# 存储已经格式化的html页面
with open(\'piaofang.html\', \'w\', encoding=\'utf-8\') as f:
f.write(piaofang_html)我们将以上过程整合,即可得到完整的票房数据获取的代码实例:
import requests
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36\'
}
def get_html():
\'\'\'
获取JSON文件
:return: JSON格式的数据
\'\'\'
# 请求second.json的URL
url = \'https://box.maoyan.com/promovie/api/box/second.json\'
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 由于是JSON文件,我们可以返回JSON格式的数据便于后续提取
return response.json()
else:
return -1
except:
return None
def parse_infor(json):
\'\'\'
从JSON数据中提取电影票房数据,包括:电影名,上映信息,综合票房,票房占比,累计票房
:param json: JSON格式的数据
:return: 每次循环返回一次字典类型的电影数据
\'\'\'
if json:
# 利用json中的get()方法层层获取对应的信息
items = json.get(\'data\').get(\'list\')
for item in items:
piaofang = {}
piaofang[\'电影名\'] = item.get(\'movieName\')
piaofang[\'上映信息\'] = item.get(\'releaseInfo\')
piaofang[\'综合票房\'] = item.get(\'boxInfo\')
piaofang[\'票房占比\'] = item.get(\'boxRate\')
piaofang[\'累计票房\'] = item.get(\'sumBoxInfo\')
# 利用生成器每次循环都返回一个数据
yield piaofang
else:
return None
def save_infor(results):
\'\'\'
存储格式化的电影票房数据HTML文件
:param results: 电影票房数据的生成器
:return: None
\'\'\'
rows = \'\'
for piaofang in results:
# 利用Python中的format字符串填充html表格中的内容
row = \'{}{}{}{}{}\'.format(piaofang[\'电影名\'],
piaofang[\'上映信息\'],
piaofang[\'综合票房\'],
piaofang[\'票房占比\'],
piaofang[\'累计票房\'])
# 利用字符串拼接循环存储每个格式化的电影票房信息
rows = rows \'\n\' row
# 利用字符串拼接处格式化的HTML页面
piaofang_html =\'\'\'
电影票房
\'\'\'| 电影名 | 上映信息 | 综合票房 | 票房占比 | 累计票房 |
|---|
rows \'\'\' \'\'\' # 存储已经格式化的html页面 with open(\'piaofang.html\', \'w\', encoding=\'utf-8\') as f: f.write(piaofang_html) if __name__ == "__main__": # 获取信息 json = get_html() # 提取信息 results = parse_infor(json) # 存储信息 save_infor(results)HTML文件存储效果如下图所示:
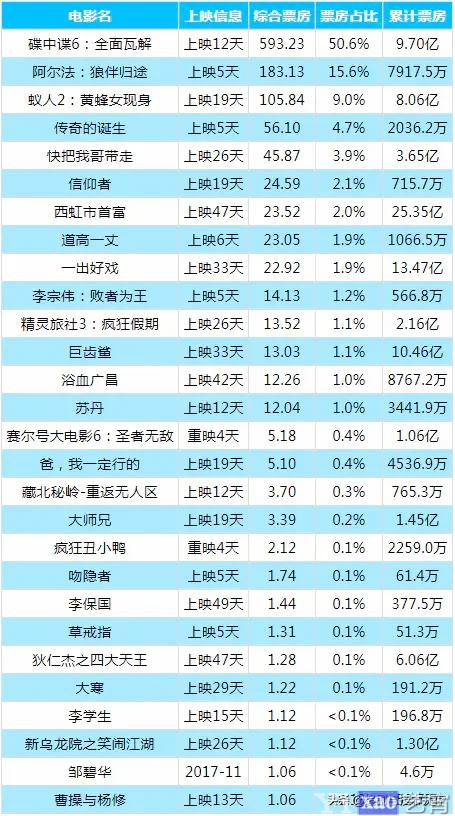
可以看见,动态网页的爬虫可能会更加简单些,关键就在于找到对应的XHR格式的请求,而一般这种格式的文件都是JSON格式的,提取相对也会更加简单方便,而读者可能会问为何要把这个信息存储为HTML文件格式的呢,喜欢电影的读者可能会经常打开猫眼电影查看每天的电影票房数据,何不尝试将我们所学的爬虫知识运用起来制作一个定时爬取电影票房数据并推送至个人邮箱的爬虫小程序呢,这样就省得我们每天打开网页查看,让数据主动为我们服务,也算是学习致用了吧,感兴趣的读者可以自己尝试下,下图笔者根据这个爬虫程序扩展每天收到的实时票房信息邮件,每天定时爬取推送给笔者,列表内容如下图所示:
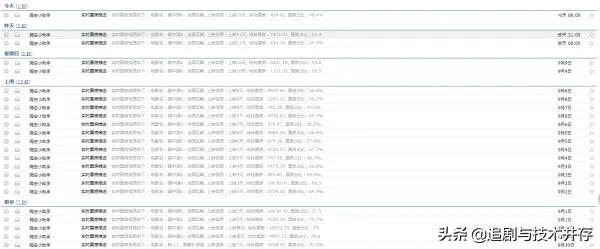
推动内容如下图所示:
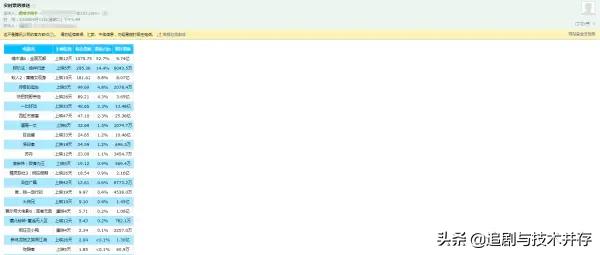
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/20610.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
python快速开发一个MP3播放器示例
全部代码如上已经贴到图片 安装开发依赖 上述软件只需要两个python包 pip install python-vlc -i https://pypi.douban.com/sim…
-
使用js防止页面iframe调用代码
我时我们发会现自己的网站给别要调用并且一模一样的,这个其实就是简单的iframe调用了,下面我来给大家介绍js防止页面iframe调用的方法总结吧,有需要的朋友可参考,防止自己的网…
-
Vue事件总线(EventBus)使用详细介绍
前言 vue组件非常常见的有父子组件通信,兄弟组件通信。而父子组件通信就很简单,父组件会通过 props 向下传数据给子组件,当子组件有事情要告诉父组件时会通过 $emit 事件告…
-
PHP Curl的简单使用
本文写给刚入PHP坑不久的新手们,作为工具文档,方便用时查阅。 CURL是一个非常强大的开源库,它支持很多种协议,例如,HTTP、HTTPS、FTP、TELENT等。日常开发中,我…
-
Chrome下修复元素fixed后几率触发元素偏移1或2像素的解决方案
存在的问题 chrome浏览器下为元素使用position fixed之后 ,触发其他动画转换 滑块或者元素缩放 旋转,被绝对/相对/固定定位的元素有几率发生偏移1或2像素让块级元…
-
字节跳动小程序如何接入腾讯云CloudBase?
由于字节跳动小程序没有提供getAccountInfoSync()接口,无法通过接口获取appId 所以需要将appId设置到字节跳动小程序app对象上。
-
如何使用docker高效部署Node应用
前言 ❝ 如何在生产环境部署一个 Node 应用?[1] ❞ 一个合理并且高效的部署方案,不仅能够实现快速升级,平滑切换,负载均衡,应用隔离等部署特性,而且配有一套成熟稳定的监控。…
-
2017年8个最流行的Web编程趋势
互联网一直在不断的发展,这意味着开发人员必须及时了解当前的所有变化。人们在新闻、社交、购物到银行等各大方面都与互联网有着千丝万缕的联系。因此,为了满足全球数百万网络用户的需求,We…
-
MYSQL批量修改替换文章标题内容SQL语句集合
下面以DEDECMS 为例: 文章标题字段的替换: update dede_archives set title=replace(title,”被替换的内容”…
-
Shell脚本进阶的经典用法
Shell 脚本进阶的经典用法 一、条件选择、判断 1、条件选择if (1)用法格式 if 判断条件 1 ; then 条件为真的分支代码 elif 判断条件 2 ; then 条…