之前在家里的老电脑中,发现一个加密zip压缩包,由于时隔太久忘记密码了,依稀记得密码是6位字母加数字,网上下载了很多破解密码的软件都没有效果,于是想到自己用Python写一个暴力破解密码的脚本。
今天的文章来自 盏茶作酒 同学。他在老电脑中发现了一个加密的 zip 文件,于是用 Python 破解了文件密码。在破解的过程中出现了内存爆炸的问题,通过阅读 Python 源代码找到了解决方案。
下面就来给大家分享一下他的操作。
之前在家里的老电脑中,发现一个加密zip压缩包,由于时隔太久忘记密码了,依稀记得密码是6位字母加数字,网上下载了很多破解密码的软件都没有效果,于是想到自己用Python写一个暴力破解密码的脚本。
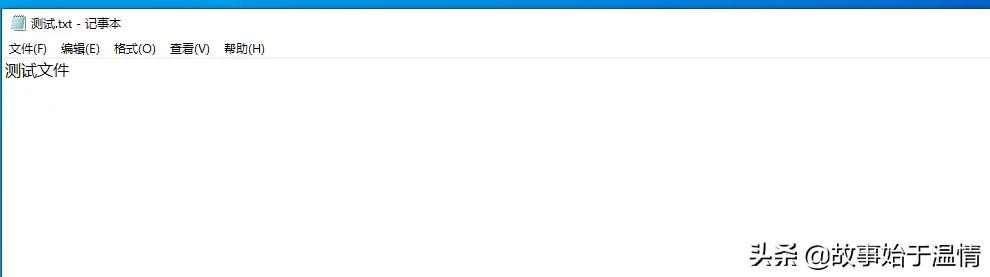
Python 有一个内置模块 zipfile 可以解压 zip 压缩包。先来测试一波:创建一个测试文件,压缩,设置解压密码为123。

importzipfile
# 创建文件句柄
file = zipfile.ZipFile(“测试.zip”,’r’)
# 提取压缩文件中的内容,注意密码必须是bytes格式,path表示提取到哪
file.extractall(path=’.’, pwd=’123′.encode(‘utf-8’))
运行效果如下图所示,提取成功。

既然如此,那我不停尝试所有可能的密码组合去解压缩不就行了嘛~
好了,开始破解老文件的密码。
为了提高速度,我还加了多线程的代码:
importzipfile
importitertools
fromconcurrent.futuresimportThreadPoolExecutor
defextract(file, password):
ifnotflag:return
file.extractall(path=’.’, pwd=”.join(password).encode(‘utf-8’))
defresult(f):
exception = f.exception()
ifnotexception:
# 如果获取不到异常说明破解成功
print(‘密码为:’, f.pwd)
globalflag
flag =False
if__name__ ==’__main__’:
# 创建一个标志用于判断密码是否破解成功
flag =True
# 创建一个线程池
pool = ThreadPoolExecutor(100)
nums = [str(i)foriinrange(10)]
chrs = [chr(i)foriinrange(65,91)]
# 生成数字+字母的6位数密码
password_lst = itertools.permutations(nums + chrs,6)
# 创建文件句柄
zfile = zipfile.ZipFile(“加密文件.zip”,’r’)
forpwdinpassword_lst:
ifnotflag:break
f = pool.submit(extract, zfile, pwd)
f.pwd = pwd
f.pool = pool
f.add_done_callback(result)
然而,事情并没有那简单……
代码跑一会儿,内存爆了!
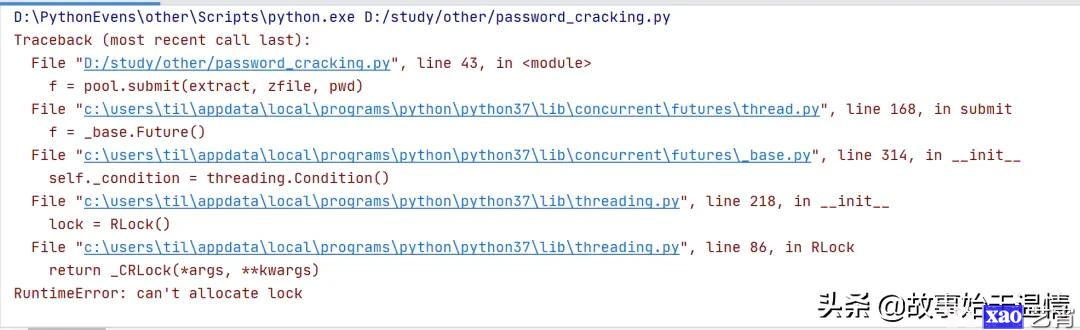
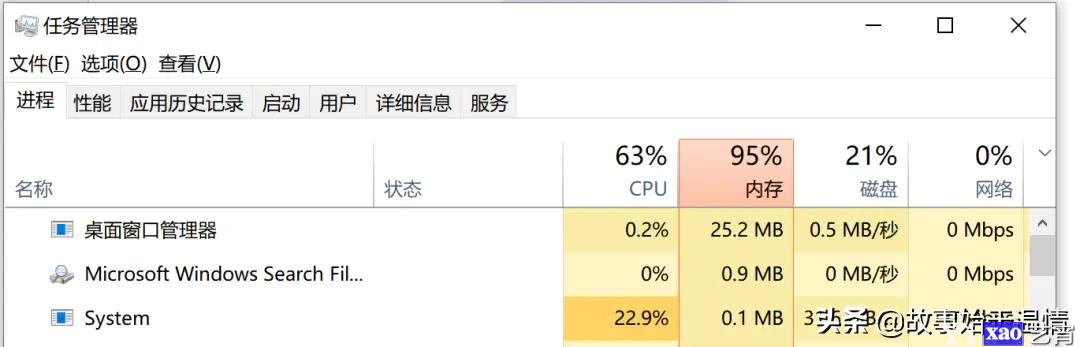
于是,为了找寻问题所在,我就去查看了一下源码,发现ThreadPoolExecutor默认使用的是无界队列。而程序中尝试密码的速度跟不上生产密码的速度,就会把生产任务无限添加到队列中。导致内存被占满。内存直接飙到95:
找到病根儿,剩下的就是对症下药了。
继承并重写了ThreadPoolExecutor类中的_work_queue属性,将无界队列改成有界队列,这样就不会出现内存爆满的问题,看代码:
importqueue
fromconcurrent.futuresimportThreadPoolExecutor
classBoundedThreadPoolExecutor(ThreadPoolExecutor):
def__init__(self, max_workers=None, thread_name_prefix=”):
super().__init__(max_workers, thread_name_prefix)
self._work_queue = queue.Queue(self._max_workers *2)# 设置队列大小
用自定义的BoundedThreadPoolExecutor类替代前面代码中的ThreadPoolExecutor。
再次执行……
程序输入如下图内容:

Bingo!破解成功!(原来密码如此简单……
)
话说回来,毕竟这个压缩包我是隐约知道它的位数和范围(字母和数字),所以破解出来需要的时间是可以忍受的。如果有天你在网上找了一个无人认领的加密压缩包,想要一窥究竟但又并不知道它有多少位密码,那我只能祝你好运啦~
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/24447.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
springboot+thymeleaf+nginx实现页面静态化
适用场景 在高并发的情况下,为了缓解服务器动态解析的压力,利用nginx处理静态文件的优点,可将系统中修改次数较少的页面进行静态化处理。 自定义工具类 import org.thy…
-
写出高性能SQL语句的35条方法
当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况) 而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息。
-
使用React Native开发Window桌面应用
众所周知,React 是一个由 Facebook 编写的免费开源 JavaScript 库,用于创建高度动态的 Web UI。 Facebook 后来创建了 React Nativ…
-
php在线打包工具源代码
一哥们要实现 php 的在线打包工具,随手在网上搜索了一个,但跟哥们的要求不一样,他的要求是在页面进行的变量传递过来的文件进行打包并在浏览器进行下载,但从网上找来的这个测试了下感觉…
-
为django admin搜索search_fields添加搜索框提示文字
如上图所示django admin在ModelAdmin中添加search_fields即可显示一个搜索框,但是不能设置搜索框的提示文字,在实际开发中要让使用的人知道输入什么可以进…
-
在Node.js中创建安全的REST API
应用程序编程接口(API)能够让各种软件在内部和外部实现流畅交互,这是可扩展性和可重用性的基础。如今,提供公共API的在线帮助已是流行趋势。它方便了其他开发人员,快速地接入已有的社…
-
tracking.js浏览器端实时人脸检测、颜色跟踪技术
tracking.js将不同的计算机视觉算法和技术引入到浏览器环境中。通过使用现代的HTML5规范,我们使你能够做实时的颜色跟踪,人脸检测等。 github上该项目目前已经有8.6…
-
支付宝支付前后端实现Vue+Spring Boot
本文主要总结基于Vue/Spring Boot的支付宝支付实现,兼容H5与电脑端。 1. 应用创建与配置 第一步:登录支付宝开放平台创建应用; 并视情况需要添加“手机网站支付”和“…