Pulsar官方提供了对Spark Streaming的支持。我看了下Stream Native对Pulsar流处理的支持情况,Pulsar对Flink的扩展做得更全面些。我截下github的支持情况。
- Apache Pulsar与架构
- 产品定位
- Pulsar关键特性
- Pulsar架构
- Pulsar客户端
- Topic Compaction
- Pulsar schema
- Pulsar Functions
- Pular IO Connector
- Pulsar SQL
- 关于Pulsar的读音
- 本地安装Pulsar
- 创建pulsar用户
- 下载并解压pulsar
- 使用Pulsar
- CLI工具
- API
- Routing Mode(路由模式)
- Pulsar SQL
- 关于流式引擎的选择
Apache Pulsar与架构
产品定位
我们Pulsar的产品定位主要是云原生的、分布式消息平台、以及流计算平台。它是来自于Yahoo!的开源项目。Pulsar对于云原生的支持直接体现就在于多租户,我们在后续Pulsar的元数据中总是能看到租户的身影。所以,它更容易和云平台整合在一起。


image-20210724153751586
而Kafka也是一个开源的分布式事件流处理平台。

image-20210724153914400
可以说,它们在很大程度上,会有不少的重叠。这两个项目都是Apache的顶级项目。Kafka流行的时间比较长,2011年 LinkedIn就将它开源了,2012年就已经在Apache孵化器中孵化。而Pulsar要比Kafka晚一些,它是Yahoo!在2016年开源的,并且2018年称为Apache的顶级项目。它们虽然很像,但它们一定会存在不同的特点。我们先来了解下Pulsar。
Pulsar关键特性
部署方式
Pulsar官方宣称是非常容易部署的。我们也可以在官方文档中看到有三种方式的部署:
- Standalone,在做一些开发、测试、示例,可以使用Standalone模式来部署Pulsar,当然,如果我们想要独立部署Pulsar集群,作为企业的消息中间件,也可以将Pulsar单独部署。
- Docker,Docker部署的方式非常简单,只需要拉取指定的镜像启动即可。
- Kubernetes,Pulsar也提供了易于部署在K8s上的部署方式,它包含了众多相关的组件自动部署。
关键特征(key feature)
- 原生支持多个Pulsar集群,在不同Pulsar集群中要进行跨集群复制也是原生支持的。
- 可以支持低延迟的publish和端对端延迟。
- 无缝扩展到上百万个topic。
- 非常简单的客户端API,支持Java、Go、Python、C++语言。
- 支持多种订阅模式,包括:独占、共享、故障转移。
- 通过BookKeeper提供消息持久存储支持,保障消息传递。
- 通过无服务器,轻量级的计算框架,Puslar Functions提供流原生数据处理能力。
- 基于Pulsar Funstions构建了无服务器的connector,可以比较容易地进行数据导入、导出。
- 支持数据冷热分层。
Pulsar架构
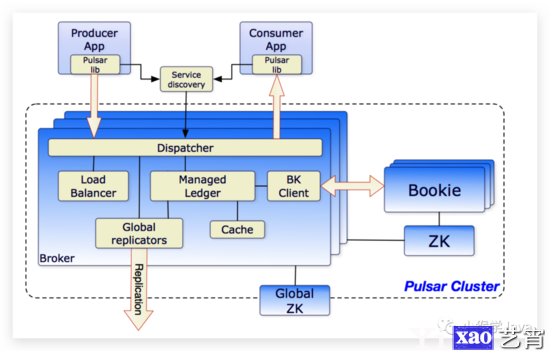
image-20210724162341629
我们前面提到了Pulsar集群可以原生支持多个Pulsar集群。所以,在架构的High Level层面,一个Pulsar实例对应的是多个Pulsar集群,不同的Pulsar集群之间可以相互复制数据。
broker
Kafka中也有broker的概念,broker是一个无状态的组件,状态存储在ZooKeeper中,它其实就是Kafka的服务器。而Pulsar集群也是由一个或者多个Broker组成的,Broker也是无状态的。Pulsar broker主要运行着两个组件:
- 一个HTTP Server,它以REST API方式,对生产者、消费者提供了管理、查找主题的功能。生产者连接到Borker,然后发送消息,消费者连接到Broker然后消费消息。
- 一个Dispatcher(分发器),它是一个异步的TCP服务器,负责将所有数据以二进制协议分发。
Managed Ledger
为了保证Pulsar性能,在生产者发送的消息积压不超过了Managed Ledger Cache(管理账簿缓存,或者我们把它称为写缓存),消息是基于Managed Ledger Cache来分发的。如果消息积压远远大于写缓存,将会从BookKeeper中读取。
Global Replicators
Global Replicators翻译过来为全局复制器,顾名思义,它是用来复制数据的——将一个Topic的数据,复制到另一个Topic。它可以用于将本地的broker中的数据通过Pulsar的Java客户端,发送给远程服务器。
Cluster
一个Pulsar由多个集群组成。而一个Pulsar集群,包含:
- 一个、或者多个Broker
- 一个Cluster-Level的ZooKeeper,用于集群的配置和协调服务。
- 一组用于存储消息的Bookie。
Meta Store
Pulsar的MetaStore负责存储Pulsar集群所有的元数据、schema、以及代理负载。Pulsar使用的是ZooKeeper进行元数据存储、集群配置和协调。
Configuration Store
顾名思义,Configuration Store存储Pulsar实例的所有配置。例如:集群、租户、命名空间、主题、分区等配置。配置存储可以在多个集群间共享。配置存储可以部署在单独的ZooKeeper集群,也可以部署在现有的ZooKeeper集群。
Persistent Storage
Pulsar保证应用程序传递的消息不丢失。如果消息到达Broker,会将消息存储到指定的可靠位置。Pulsar会将未被消费的消息以持久化的方式存储,这种模式也称为持久消息传递。简单来说,不管是否有消费者,都会先将消息持久化。我们之前所了解的Kafka,也会将消息持久化。Pulsar中,所有的消息的副本都会存储下来,并且同步到磁盘上。
Apache BookKeeper

image-20210725171207117
BookKeeper是一个分布式预写日志(WAL)系统。它有一些优势:
- Pulsar可以利用许多独立的日志,称为Ledger(分类账簿)。随着时间推移,可以为主题创建多个Ledger。(没看出来这有什么优势啊?)
- BookKeeper为顺序的数据提供高效的存储。
- 能够保证在系统出现故障时,读取Ledger的数据是一致的。
- BooKeeper可以确保在bookies之间I/O均匀分布。
- BookKeeper的扩展性好,可以在容量、和吞吐量上进行水平扩展。就像HDFS一样,可以往集群中添加更多的bookies来增加容量。
- Bookies可以支持并发读取、和写入处理数千个Legder。通过使用多个磁盘设备,一个用于日志操作,另一个用于一般存储。Bookies能够将读取操作的影响和正在进行的写入操作的延迟隔离出来。
- Pulsar中,消费者订阅消费消息的位置称为cursor(在Kafka中称为offset),cursor也存储在BookKeeper中。
以下这张图,说明了Pulsar和BookKeeper的交互方式。
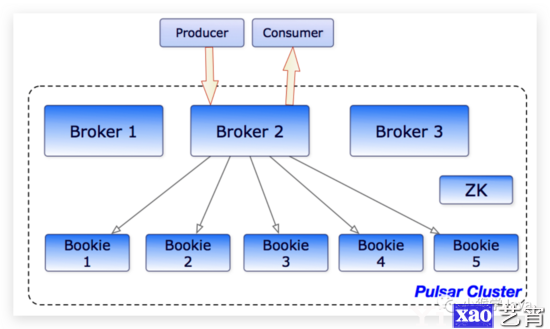
image-20210724224326622
Ledger
Ledger是Append-only的数据结构,它具备一个写入器,并分配给BookKeeper存储节点或者bookies。Ledger中的条目(Entries)被复制到多个Broker。Ledger具备有非常简单的语义:
- Broker可以创建Ledger,将新的Entries添加到Ledger,还可以关闭Ledger。
- 在Ledger关闭后(显示关闭或者crash),Ledger只能以只读的方式打开。
- 当不再需要Ledger中的Entries时,可以从系统中删除整个Ledger。
读一致性保障
BookKeeper可以在出现故障时,保证Ledger读取的数据是一致的(Kafka是通过水位线来保证数据的一致性)。由于Ledger中只有一个写入器,是单进程写入,该进程可以非常高效地写入追加Entries,而不需要考虑并发写入锁的问题。一旦出现故障,Ledger将会执行一个Recovery进程,该进程会确定Ledger的最终状态,将状态设置为预写日志的最新Entries。然后,所有的消费者都能够看到完全一样的数据。
Managed Ledger
Pulsar中提供了一个基于BookKeeper Ledger开发的库,称为Managed Ledger。它代表的是单个主题的存储层。Managed Ledger是对消息流的抽象,其中一个写入器不断在流末尾追加数据,同时,可以由多个游标来消费流中的数据,每个游标对应都有自己的位置。
而在内部,一个Managed Ledger使用多个BookKeeper Ledger来存储数据。使用多个Ledger的原因为:
- 当出现故障时,Ledger不再可写,需要重新创建一个新的Ledger。前面介绍BookKeeper提到过,一旦Ledger closed,不管是正常关闭,或者应用crash,都会创建一个新的Ledger。
- 多个文件可以允许Ledger滚动,方便数据的清理。例如:当一个cursor已经完成了Ledger的消费,那么就可以删除该Ledger了。
Journal Storage
前面,我们提到了BookKeeper是一种基于WAL的存储系统。这些WAL日志就包含了BookKeeper的写入事务日志。在将数据更新到Ledger之前,Broker必须要先确保数据能够将事务日志写入到持久化存储。一旦Bookies启动,或者是就的日志大小到达阈值,就会创建一个新的WAL日志文件。
Pulsar代理
Pulsar代理是一种客户端连接到Pulsar的方式。在某些情况下,例如:生产环境的网络不能被外部访问,只能通过一个跳板机访问。此时,客户端是无法直接连接到Broker的。此时,就可以通过Pulsar代理来访问。它相当于是一个用于访问集群中所有Broker的单一网关。所有的客户端都会与Pulsar Proxy连接,而不是与Broker直连。
服务发现
Pulsar提供了一个内置的服务发现机制,客户端可以通过连接单一的URL来与整个Pulsar示例通信。当然,我们也可以配置自己的服务发现系统。要实现自己的服务发现,只需要保证:当客户端访问http://host:8080执行HTTP请求时,客户端需要重定向到活动的broker即可,不管是通过DNS、HTTP或者IP重定向。
Pulsar客户端
Pulsar的客户端支持多种语言,Client实现的背后,还支持透明的重新连接、failover、消息排队、以及试探法,例如:带有退避的连接重试。
Pulsar客户端连接步骤
在应用程序创建Producer或者是Consumer之前,Pulsar客户端需要进行两个步骤:
- 客户端会尝试向Proxy发送HTTP请求,以确定topic的对应的broker。该请求最终会被一个broker响应,并通过查看zookeeper,已确定谁为topic提供服务,如果没有broker为topic提供服务,它会尝试将请求分配给负载最少的broker。
- 一旦客户端拥有了Broker的有效地址,就会创建一个TCP连接(或者重用池中的连接),并进行身份验证。
而每当TCP连接终端时,客户端会立即重新启动连接,并尝试重新创建生产者或者消费者,直到操作成功。
读取接口
在Pulsar中,标准的消费者会监听主题、处理传入的消息,并在处理消息后确认消息。而每当创建新的消费者时,默认都会从Topic的尾部开始消费。而当消费者使用之前的订阅信息消费topic的数据时,会从未被确认的最早消息开始读取。通过消费者接口,订阅游标由Pulsar自己管理。
当然,读取接口也允许应用程序自己管理Cursor。当使用Reader读取Topic中的数据时,我们可以指定Reader从何处开始读取。例如:我们可以指定从earliest、latest开始消费,或者我们可以直接指定Message ID开始消费。通过Reader接口,可以实现一次性语义。
与Subscription/Consumer不同,Reader是非持久的,也不会组织topic中的数据被删除,官方推荐我们配置数据保留。如果topic的数据保留时间没有配置足够长的时间,那么Reader未读取的消息可能会被删除。这就有可能会导致数据丢失。而配置了保留一定的时间,就可以保证Reader有足够的时间来处理消息。
在Pulsar中,有两套读取topic数据的接口。一套是Consumer Interface、一套是Reader Interface。
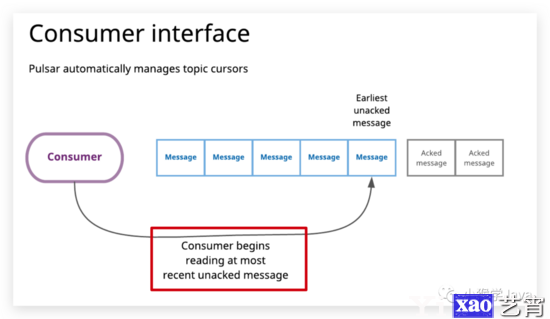
image-20210725002851482
这两套接口非常类似于Kafka的High-level API和Low-level API。其中Consumer API会自动管理Topic的cursor(游标),而Reader API是手动控制Topic的cursor。

image-20210725003110587
大家看到了吗?Reader是由应用程序指定,从哪个位置读取数据。
Topic Compaction
Pulsar主题可以根据需要持久化尽可能多的未确认消息,同时保留消息的顺序。默认情况,Pulsar会存储一个主题上产生的所有未确认、未处理的消息。这和Kafka不一样,Kafka一旦到达配置的阈值(时间、或者大小)就会开始清理数据。如果消费者数据存在严重积压,就会出现数据丢失,造成应用程序退出。Pulsar也提供了topic compation功能,会减少相同key存储的最新消息。这个操作和Kafka类似。
Pulsar schema
Schema注册表
我们之前接触的大部分消息队列都是无Schema的。例如:很多时候,我们会将消息以JSON文本的方式写入到Kafka分区中,然后我们通过流处理程序解析schema。这个过程中,如果数据中出现问题,我们只有到流程序中才能发现,所以Kafka的schema非常简单,就是key-value。Pulsar将类型安全引入了进来。在Pulsar中,可以基于客户端、或者服务端来注册schema。
客户端方法
生产者和消费者不仅仅是负责序列化和反序列化消息,还需要指定哪个主题需要传输什么样类型的消息。客户端方法就是将schema注册交给应用程序。应用程序在创建消息的时候,就将类型信息直接写入到消息中。这样,当消费消息时,就可以根据消息中的schema来解析数据了。这种方式是比较灵活的,是约定式的,而不是强制的。
服务端方法
服务端方法就是schema是在服务器端定义的。生产者和消费者可以告诉Pulsar,某个主题应该使用什么样的类型。这种方式,Pulsar会强制执行schema检查,可以确保生产者和消费者的schema是保持同步的。Pulsar有个内置的模式注册表。客户端在主题的基础上上传数据的schema,这些schema决定了,哪些数据类型对于Pulsar是有效的。
Pulsar Functions
我们知道Kafka有一个不太流行的Kafka Streaming。而,Pulsar也推出了自己的流处理疫情——Pulsar Functions,它是一个轻量级的计算框架。它做的事情非常简单:
- 从一个或者多个Pulsar topic中消费消息。
- 对于每条消息执行用户自定义的逻辑。
- 将执行结果发布到另一个主题。
其实,现在对于我们来说,一般开发一些流应用,一般会选择像Strucutred Streaming、Flink这样的流计算平台。基于这些框架开发出来的应用,我们也会单独部署。而和Kafka Streaming一样,Pulsar Functions是不需要额外部署的。
Pular IO Connector
Pulsar IO Connector可以让我们很容易实现与外部系统的导入导出。Pulsar主要有两种连接器,一种是source,另一种是sink。

image-20210725104017682
Pulsar SQL
前面,我们看到了Pulsar可以指定topic的schema。我们可以在Pulsar中存储有schema的数据,然后使用Trino来查询数据(通过Presto SQL)来实现。
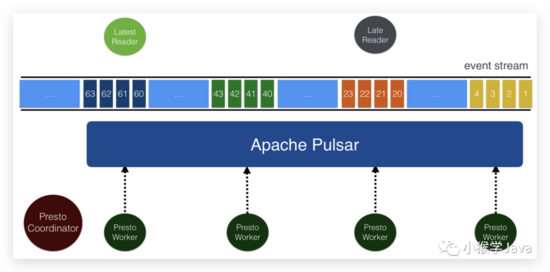
image-20210725104337409
Presto SQL连接器可以直接从BookKeeper中读取数据。
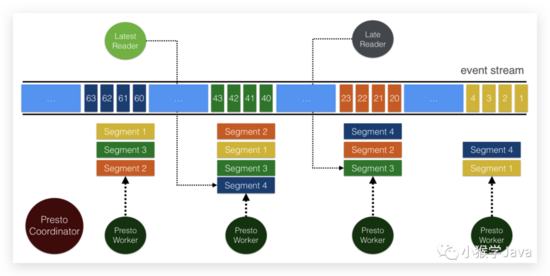
image-20210725104532756
关于Pulsar的读音
国内有不少人读音是:帕萨。但看标准读音不应该发这个音,因为 / l / 这个字母是要发音的。所以,正确的发音应该是:剖萨。大家也可以听一下国外的伙伴是怎么读的。
https://www.youtube.com/watch?v=JzExXJYiGvY&t=15s

image-20210724121834121
本地安装Pulsar
如果要进行本地开发、测试,我们可以在我们本机上以Standalone方式来运行Pulsar。Standalone模式的Pulsar需要部署以下几个组件:
- Pulsar Broker
- ZooKeeper
- BookKeeper
这几个组件都需要运行在JVM之上。
创建pulsar用户
useradd pulsar
usermod pulsar -G hadoop
下载并解压pulsar
当前,我们基于Pulsar的2.8版本。
wget https://archive.apache.org/dist/pulsar/pulsar-2.8.0/apache-pulsar-2.8.0-bin.tar.gz
[pulsar@ha-node1 ~]$ ll
总用量 323052
-rw-r--r-- 1 root root 330804999 7月 25 11:15 apache-pulsar-2.8.0-bin.tar.gz
[pulsar@ha-node1 ~]$ tar -xvzf apache-pulsar-2.8.0-bin.tar.gz -C /opt/
[pulsar@ha-node1 ~]$ ln -s /opt/apache-pulsar-2.8.0/ /opt/pulsar
安装目录结构
[pulsar@ha-node1 pulsar]$ ll
总用量 72
drwxr-xr-x 3 pulsar pulsar 225 1月 22 2020 bin
drwxr-xr-x 5 pulsar pulsar 4096 1月 22 2020 conf
drwxrwxr-x 3 pulsar pulsar 132 7月 25 11:16 examples
drwxrwxr-x 4 pulsar pulsar 66 7月 25 11:16 instances
drwxrwxr-x 3 pulsar pulsar 16384 7月 25 11:16 lib
-rw-r--r-- 1 pulsar pulsar 31639 1月 22 2020 LICENSE
drwxr-xr-x 2 pulsar pulsar 4096 1月 22 2020 licenses
-rw-r--r-- 1 pulsar pulsar 6612 1月 22 2020 NOTICE
-rw-r--r-- 1 pulsar pulsar 1269 1月 22 2020 README
解压完后,我们可以在Pulsar的安装目录中看到以下结构:
- bin:包含了Pulsar的命令行工具。
- conf:包含了Pulsar的配置文件,包括了broker配置、zk配置以及其他。
- examples:包含了Pulsar Functions的示例。
- lib:Pulsar使用的JAR包。
而我们一旦启动了Pulsar,会自动创建以下几个目录:
- data:用于存储bk和zk的数据。
- instances:供Pulsar Functions使用。
- logs:日志文件。
启动与关闭
以应用程序方式启动
# 启动standalone pulsar
bin/pulsar standalone
当我们在控制台中看到以下输出,表示启动成功。
1:18:57.475 [main] INFO org.apache.pulsar.websocket.WebSocketService - Pulsar WebSocket Service started
如果要关闭pulsar standalone,直接ctrl + c即可。
以守护进程方式启动
# 启动
bin/pulsar-daemon start standalone
# 关闭
bin/pulsar-daemon stop standalone
生产和消费消息
Pulsar提供了一个CLI工具,让我们生产和消费Pulsar集群中的消息。
消费消息
# -s表示指定消费者的名字
bin/pulsar-client consume test-topic -s "consumer1"
如果Pulsar中没有test-topic,会自动创建一个。
生产消息
# 往pulsar中的test-topic主题,发送一条消息
bin/pulsar-client produce test-topic --messages "hello-pulsar"
当我们生产数据后,可以看到消费者中打印了以下消息。
----- got message -----
key:[null], properties:[], content:hello-pulsar
11:28:59.965 [main] INFO org.apache.pulsar.client.impl.PulsarClientImpl - Client closing. URL: pulsar://localhost:6650/
11:28:59.997 [pulsar-client-io-1-1] INFO org.apache.pulsar.client.impl.ConsumerImpl - [test-topic] [consumer1] Closed consumer
11:29:00.003 [pulsar-client-io-1-1] INFO org.apache.pulsar.client.impl.ClientCnx - [id: 0x79b909a6, L:/127.0.0.1:22369 ! R:localhost/127.0.0.1:6650] Disconnected
11:29:02.017 [main] INFO org.apache.pulsar.client.cli.PulsarClientTool - 1 messages successfully consumed
好了,我们看到了,这个Standalone模式,我们没有配置任何组件,它自动帮助我们启动了内置的ZooKeeper、以及BookKeeper。然后我们就可以使用它了。这种方式显然不能用于生产环境。在生产环境中,我们一般都会提供独立的ZooKeeper集群、以及BookKeeper集群。
使用Pulsar
CLI工具
CLI工具是最基本的工具,我们经常会使用到。
pulsar命令
我们前面启动、关闭pulsar,都是使用pulsar命令。它就是专门用来在前台启动pulsar的各种组件的。例如:bookies和zookeeper,如果要启动在后台,则可以使用pulsar-daemon。更多命令请参考:
https://pulsar.apache.org/docs/en/reference-cli-tools/
pulsar-client
前面我们就是用pulsar-client来启动生产者和消费者的。
pulsar-admin
我们可以通过pulsar-admin来管理pulsar集群。
查看pulsar集群列表
bin/pulsar-admin clusters list
[pulsar@ha-node1 pulsar]$ bin/pulsar-admin clusters list
"standalone"
可以看到,当前就启动了一个名为standalone的集群。通过clusters子命令,我们可以创建、删除pulsar集群。
查看租户
bin/pulsar-admin tenants list
[pulsar@ha-node1 pulsar]$ bin/pulsar-admin tenants list
"public"
"pulsar"
"sample"
当前有三个租户。我们也自己来创建、删除租户。
查看brokers
# 查看当前活动的broker
[pulsar@ha-node1 pulsar]$ bin/pulsar-admin brokers list use
"localhost:8080"
# 查看当前的Leader broker
[pulsar@ha-node1 pulsar]$ bin/pulsar-admin brokers leader-broker
{
"serviceUrl" : "http://localhost:8080"
}
查看指定broker的Namespace
bin/pulsar-admin brokers namespaces use
--url localhost:8080
> --url localhost:8080
"public/default/0x00000000_0x40000000 [broker_assignment=shared is_controlled=false is_active=true]"
"public/functions/0x40000000_0x80000000 [broker_assignment=shared is_controlled=false is_active=true]"
"pulsar/standalone/localhost:8080/0x00000000_0xffffffff [broker_assignment=shared is_controlled=false is_active=true]"
Pulsar中的namespace是组织topic的逻辑分组。我们看到,上述命令的输出中,我们看到localhost:8080的broker中有三个namespace。注意,namespace是必须包含在租户下的。
namespace
查看pulsar租户下的所有namespace。
bin/pulsar-admin namespaces list pulsar
"pulsar/system"
bin/pulsar-admin namespaces list public
"public/default"
"public/functions"
可以看到,pulsar租户只有一个system命名空间,而public租户有default和functions命名空间。我们还可以通过namepsaces其他操作来创建、删除命名空间,还可以配置命名空间的积压策略、持久化策略、TTL、保留策略、限流策略等。
topics
Pulsar中topic可以分为:持久化的、和非持久化的。我们先来查看下当前pulsar实例下的system名称空间的所有topic:
bin/pulsar-admin topics list public/default
"persistent://public/default/test-topic"
我们看到了,我们之前创建的test-topic是一个持久化topic,并且我们当时没有指定命名空间,所以它在public/default名称空间下。如果
删除topic:
bin/pulsar-admin topics delete "persistent://public/default/test-topic"
创建topic:
bin/pulsar-admin topics create persistent://public/default/my-topic
获取topic信息:
bin/pulsar-admin topics stats persistent://public/default/my-topic
{
"count" : 0,
"msgRateIn" : 0.0,
"msgThroughputIn" : 0.0,
"msgRateOut" : 0.0,
"msgThroughputOut" : 0.0,
"bytesInCounter" : 0,
"msgInCounter" : 0,
"bytesOutCounter" : 0,
"msgOutCounter" : 0,
"averageMsgSize" : 0.0,
"msgChunkPublished" : false,
"storageSize" : 0,
"backlogSize" : 0,
"offloadedStorageSize" : 0,
"publishers" : [ ],
"waitingPublishers" : 0,
"subscriptions" : { },
"replication" : { },
"deduplicationStatus" : "Disabled",
"nonContiguousDeletedMessagesRanges" : 0,
"nonContiguousDeletedMessagesRangesSerializedSize" : 0
}
当前创建出来的topic是一个单分区的topic。
创建多分区的topic:
# 创建一个带有3个分区的topic
bin/pulsar-admin topics create-partitioned-topic persistent://public/default/partitioned-topic --partitions 3
# 获取topic的分区数量
bin/pulsar-admin topics get-partitioned-topic-metadata persistent://public/default/partitioned-topic
{
"partitions" : 3
}
# 查看分区状态
bin/pulsar-admin topics partitioned-stats persistent://public/default/partitioned-topic
API
接下来,我通过Scala来编写代码操作Pulsar,其实就是通过代码往Pulsar中生产、和消费消息。API文档,请参考:
https://pulsar.apache.org/docs/en/client-libraries-java/。
Pulsar原生API
导入依赖
<properties>
<pulsar.version>2.8.0</pulsar.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>${pulsar.version}</version>
</dependency>
</dependencies>
配置对象
object PulsarConf {
// Pulsar的连接URL,如果有多个broker使用逗号分隔
val pulsarConnectionUrl = "pulsar://ha-node1:6650"
// Topic名称
val topicName = "persistent://public/default/partitioned-topic"
}
消费者
object PulsarConsumerDemo {
def main(args: Array[String]): Unit = {
import PulsarConf._
// 创建客户端对象
val client = PulsarClient.builder()
.serviceUrl(pulsarConnectionUrl)
.build();
// 创建消费者并订阅主题
val consumer = client.newConsumer()
.topic(topicName)
.subscriptionName("subscription-1")
.subscribe()
// 消费消息
while(true) {
val message = consumer.receive()
val key = new String(message.getKey)
val value = new String(message.getValue)
// 打印并确认消息
println(s"收到消息:key = ${key}, value = ${value}")
consumer.acknowledge(message)
}
}
}
生产者
object PulsarProducerDemo {
def main(args: Array[String]): Unit = {
import PulsarConf._
// 创建客户端对象
val client = PulsarClient.builder()
.serviceUrl(pulsarConnectionUrl)
.build();
// 创建生产者
val producer = client.newProducer(Schema.STRING)
.topic(topicName)
.create()
// 发送消息
(1 to 10).foreach { id =>
producer.newMessage()
.key(s"$id")
.value(s"[${new Date()} MSG:${id}] This is a test!")
.send()
}
// 关闭生产者、客户端连接
producer.close()
client.close()
}
}
先启动消费者,然后再启动生产者,就可以看到打印出来了消费到的消息了。
Kafka API Wrapper
看到这个,大家应该明白啥意思了。Pulsar可以说是很贴心了,为了方便迁移Kafka应用,Pulsar专门设计了这样一套API。也就是说,我们可以使用之前的Kafka API来操作Pulsar。文档在:
https://pulsar.apache.org/docs/en/adaptors-kafka/,大家可自行参考。
Routing Mode(路由模式)
前面我们使用了生产者来发送消息到topic。我们原先在使用Kafka的时候,Kafka发送消息有几种策略,例如:可以使用轮询方式、也可以使用hash方式分区、或者指定到分区等。同样,在Pulsar中也有对应的概念,它叫Routing Mode。一共有三种:
- RoundRobinPartition:这种是默认的方式,如果没有提供key,那么生产者会轮询发送消息到不同的分区。而如果设置了key,就会按照key的hash值将消费分布到不同的分区中。
- SinglePartition:如果没有提供key值,生产者会随机选择分区,然后将消息发送到分区中。
- CustomPartition:自定义分区,实现MessageRouter来进行分区。
代码如下:
Producer<byte[]> producer = pulsarClient.newProducer()
.topic(topic)
.messageRoutingMode(MessageRoutingMode.SinglePartition)
.create();
Pulsar SQL
我们可以直接使用Pulsar中内嵌的Presto直接查询Pulsar中的数据。
启动Pulsar SQL
nohup ./bin/pulsar sql-worker run 1>/dev/null 2>&1 &
./bin/pulsar sql
presto>
执行SQL查询
# 查看pulsar中的catalog
show catalogs;
Catalog
---------
pulsar
system
# 查看catalog中的schema
presto> show schemas in pulsar;
Schema
--------------------
information_schema
public/default
public/functions
pulsar/system
sample/ns1
(5 rows)
# 查看schema中的表
show tables in pulsar."public/default";
presto> show tables in pulsar."public/default";
Table
-------------------
partitioned-topic
(1 row)
查看数据:
select * from pulsar."public/default"."partitioned-topic" limit 10;

image-20210725165447354
按照时间排序:
select * from pulsar."public/default"."partitioned-topic" order by __publish_time__ desc limit 10;
查询指定分区的数据:
select * from pulsar."public/default"."partitioned-topic" where __partition__ = 0 limit 10;
获取分区的数据量:
select __partition__, count(1) from pulsar."public/default"."partitioned-topic" group by __partition__;
__partition__ | _col1
---------------+-------
2 | 11
1 | 15
0 | 11
(3 rows)
很方便。
关于流式引擎的选择
Pulsar官方提供了对Spark Streaming的支持。我看了下Stream Native对Pulsar流处理的支持情况,Pulsar对Flink的扩展做得更全面些。我截下github的支持情况。
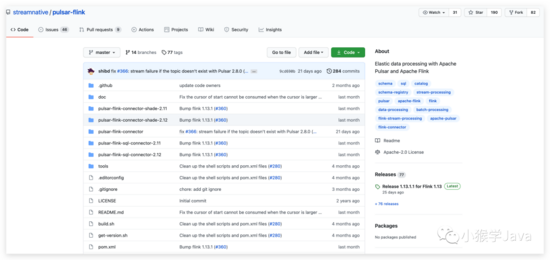
image-20210725182719975
对于Spark的支持,我们需要对scala 2.12、spark 3.x进行重新编译。
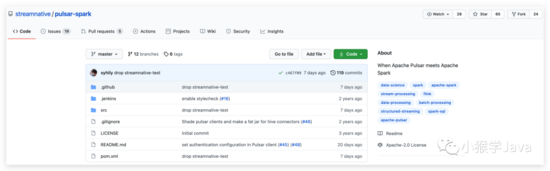
image-20210725182750135
后续,如果用到了再来测试吧,先mark。
好了,本次是Pulsar的基本体验。我们后续如果要使用Pulsar,不一定会将现有的Kafka替换掉,因为影响面积太大了,我们也很难在短时间内完成如此庞大的工作。但对于大数据应用来说,Pulsar可以作为一个很好的管道来使用。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/26303.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
Vue3后台管理系统
系统简介 此管理系统是基于Vite2和Vue3.0构建生成的后台管理系统。目的在于学习vite和vue3等新技术,以便于后续用于实际开发工作中; 本文章将从管理系统页面布局、vue…
-
MySQL读写分离的方法
前言 这篇我们来说说基于Mycat实现读写分离,实现的相关技术还有sharding-sphere、TDDL等,技术解决的问题都是一致的,技术之间思想基本相同,所以我们只需要发现…
-
Vue+element-ui 可视化表单设计生成器
今天给大家推荐一款超逼格的Vue可拖拽表单设计器组件FormGenerator。 form-generator 基于 Vue.js ElementUI 高效表单设计组件,star高…
-
WordPress 4.8正式发布 新功能更人性化
WordPress是一种使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站,也可以把WordPress当作一个内容管理系统(CMS)来…
-
通过WasmEdge嵌入WebAssembly函数扩展Golang应用
GO 编程语言(Golang)是一种易于使用且安全的编程语言,可编译为高性能的原生应用程序。Golang 是编写软件基础设施和框架的非常流行的选择。
-
WxJava3.9.0–微信开发最新Java SDK
引言 哈喽,各位小伙伴们,大家好!很高兴又跟大家见面了,今天是周一,继续为大家分享科技资讯。 前言 今天我们来说一说微信开发,随着微信生态圈的逐步建立和发展,如今,微信的活跃用户体…
-
Django框架:表关系的实现(简单版本教务系统)
一.常用的字段类型 1. IntegerField(int): 整型,映射到数据库中的int类型。 2. CharField(varchar) : 字符类型,映射到数据库中的var…