动机
某天小仙女翻她微博发照片给我看,我打开她的微博,我的天,2000多条。刚好最近在做NLP相关的工作,需要爬各种数据,于是萌生了把小仙女微博爬下来看看的想法。(坑比微博不开放接口是很菜了)
知乎@路人甲大神每隔一段时间就爬爬豆瓣/知乎等等网站,做了很多有意思的分析,看的难免心痒痒,所以一直想深入爬虫,做做数据分析。本着学习 python, 爬取了小仙女2000 条微博,主要想看看仙女微博最常发的是什么,仙女的日常又是什么。

思路
web端微博通过js渲染和ajax接口读取内容,爬取工作量太大。所以换了一下思路,用chrome爬取微博手机版,极大程度上避免了微博的反爬。
1、用chrome获取cookie。
chrome 进入 微博手机版,F12打开开发者工具,点击Network – Preserve log,使用小号登录微博手机版。(注意一定使用小号!)
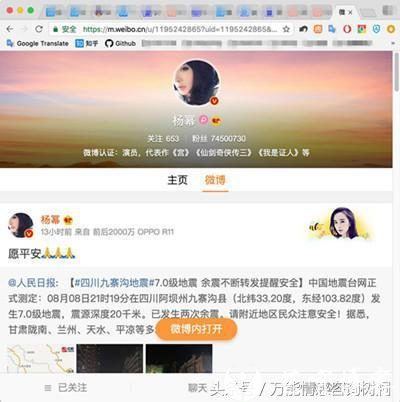
大幂幂微博
m.weibo.cn->Headers->Cookie 复制下自己的cookie,等会儿需要使用,也就是登录信息。
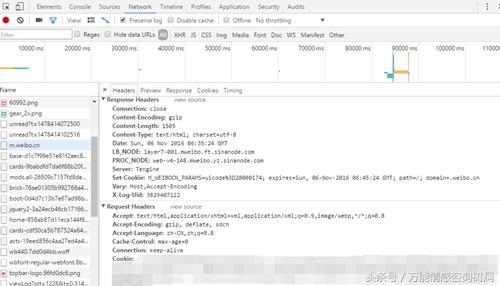
cookie
2、获取你要爬取的仙女的微博uid。
F12打开开发者工具,ctrl F查找uid就ok了。

uid
3、爬取文字和图片。
具体爬取过程有兴趣的可以去文末附带的GitHub项目链接看看啦。
需要使用的话,请注册一个小号登录,大规模爬取的话请注意ip更换。代码中有设置sleep时间,根据实际情况自行调整就好啦。
爬取过程如下:
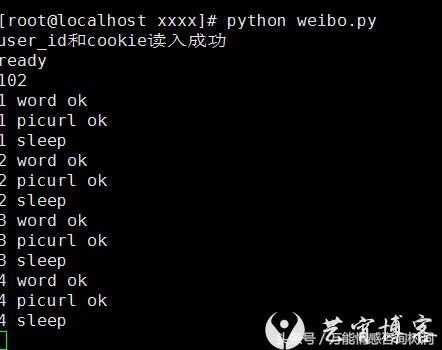
读取uid和cookie
抓取结果如下图所示:

微博文字
微博图片
1426张照片,我是服气的。。
小仙女数据
接下来,就是一些数据清洗、处理、分析的工作。(此处省去1000万字)
直接看处理的结果吧嘻嘻!
- 关键词

词云图
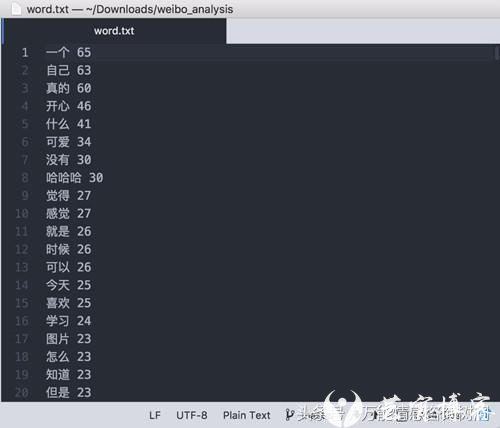
关键词词频
“一个”、“自己”、“真的” 占据了首位。哇,自己一个人开心?我是不信的,自己一个人只会哭哭吧。
“可爱”、“哈哈哈”、“开心”,这波可以的,仙女形象呼之欲出了。
“守望” “游戏” “英雄”,嗯哼 这是个电竞网瘾少女了。
现在到造句环节了,我先来一个仙女的freestyle:“觉得自己真的很可爱了哈哈哈开心”。
- 微博分类
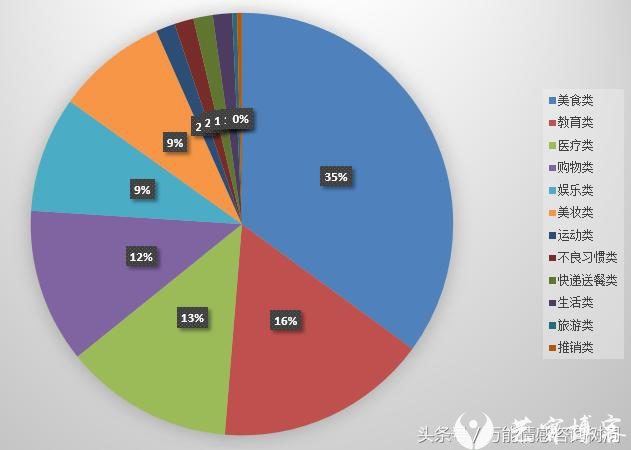
微博分类
果然还是以 美食 为主的, 毕竟是没事雍和会,日常安野牧场的小公主。
购物 / 娱乐 / 美妆都不少,好了很符合小仙女的日常了。可是真的没有互联网类吗,难怪今年要拿不到奖学金了。
快递送餐类是十分可爱了哈哈哈。一个人带4份猪食回宿舍喂猪的美少女。。。
- 常用表情
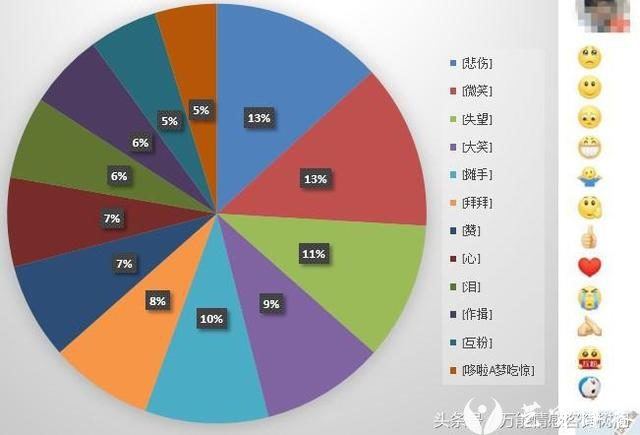
微博表情
为了让大家更清晰看出每个表情,用微博直接显示出来文字和表情的对应。
哭哭占了最多是什么鬼,还有神秘的微笑和神秘的拜拜。
真是有故事的女同学嘻嘻。
- 常用人名
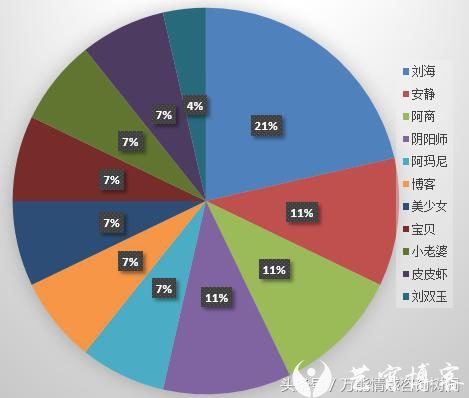
仙女使用的名字
好吧,这个词语识别和人名识别是很不完善啦。有空再改进。
国际惯例,附上源码:[GitHub CayleyMongo] :
https://github.com/CayleyMongo/weibo_spider
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/4667.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
通过javascript将图片延迟加载实现方法及代码
什么是图片延迟加载 图片延迟加载(Lazy Load)是一种优化网页性能的技术,它可以延迟加载页面中的图片,使网页的加载速度更快,提升用户的体验。具体实现就是在网页中,把页面中的图…
-
JeecgBoot手机端安装配置流程
jeecgBoot前端UI项目,可以打成app安装手机上,采用HBuilder工具,详细步骤如下 第一步: 在vue.config.js中加入 baseUrl: \’….
-
Niushop开源商城系统表单搭建
表单搭建,是商城系统触发按钮的重要模块之一,有工整详细的表单,不仅能让页面更加美观大气,还可以让后台代码更加规整与规范,方便及时查漏或者商家再次二开! 表单label宽度 layu…
-
网站开发新手学习PHP计划
我的这套线路可能跟许多学习PHP的爱好者不谋而合,这也算是一个循序渐进的学习过程,不过新手不要看到上面的概括就以为学习蛮简单的,默默在此不得不对您稍微泼一下冷水,任何东西其实都不简单,即使是小吃部的烧饼也不是一下子就会做成的。
-
autojs优秀UI-自定义控件教程
教程目的 本篇教程是一个自定义控件的教学演示, 无任何实际功能, 更没有提现功能, 那只是一个自定义按钮 主要演示自动义控件和动画, 除此之外没有其他任何功能 再次强调, 本脚本只…
-
vue+element-ui项目搭建实战
1.使用vue ui创建vue工程 利用vue-cli提供的图形化工具快速搭建vue工程:命令行运行:vue ui 工程结构说明 build:项目构建webpack(打包器)相关代…
-
ASP.NET Core Blazor未来的Web开发框架
如果你是一名.NET程序员,并且之前使用过Vue、Angular或者React,而没有了解过Blazor或者没有了解过WebAssembly,现在看到下面这段代码,我估计你一定会被…
-
HTML5获取地理位置定位信息
使用HTML5获取地理位置定位信息 如何使用HTML5地理位置定位功能 定位功能(Geolocation)是HTML5的新特性,因此只有在支持HTML5的现代浏览器上运行,特别是手…
-
Web设计师开发项目一定不要一棵树上吊死
时间过的飞快,转眼间,7月份就过完了。这段时间,因为某些原因,项目delay了。所以这个很多时间都是在学习技术。当然主要还是前端这一块。然后前段时间,公司来了4个实习生,我负责带其中的2个。以自己的角度去分析Web开发,然后再次和大家聊聊兴趣和工作的问题。
-
当前最流行的十大编程语言都有哪些用途和优缺点?
当前最流行的十大编程语言都有哪些用途和优缺点? 我们先来说说最流行的都是哪些语言, 首先声明下面的排名不分先后: C , C#, Java, Javascript, Python,…