项目需求经常会遇到一种场景,需要对远程网站特定页面自动抓取内容保存下来,比如抓取大网站的新闻存到本地作为自己网站的内容发布。本文将介绍使用HtmlAgilityPack组件来手动实现该功能,文章底部有该Demo的源码下载。
HtmlAgilityPack简介:HtmlAgilityPack是一款开源的Html解析类库,可方便地解析Html节点(包括批量节点和单个节点)。
抓取内容比较常见的情形是给定新闻列表页地址,从列表中批量抓取具体内容,比如一次性抓取该列表页20条记录的标题、详情等。
本例解析“国家电网北京市公司”网站新闻动态栏目的内容,地址为http://www.bj.sgcc.com.cn/html/main/col34/column_34_1.html
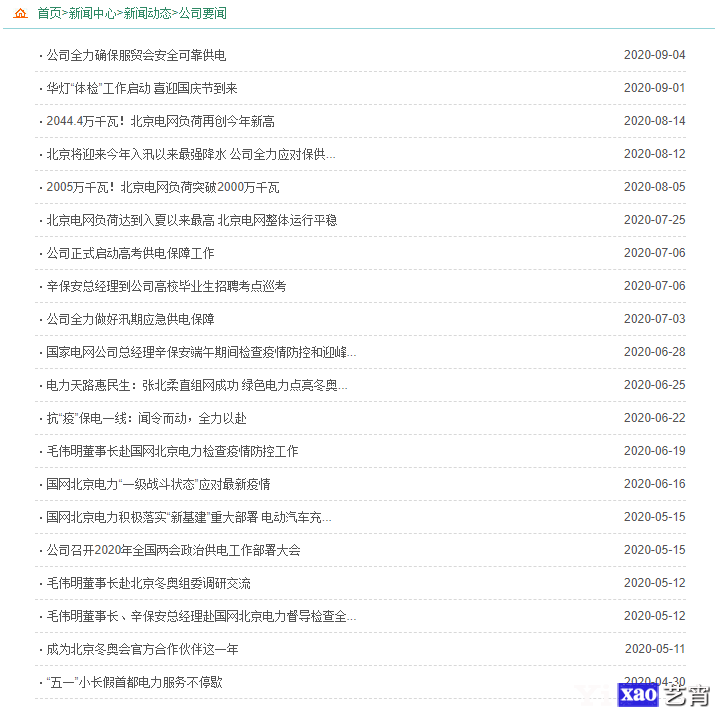

要抓取的新闻列表页
1、实现思路:
1)通过WebRequest获取列表页源码。
2)找到列表位置,找出循环内容的规律。
3)循环从每条记录详情的链接地址获取Html源代码,解析出需要的内容后插入到数据库中。
2、创建.NET项目
创建ASP.NET MVC项目,通过NuGet包管理器引用HtmlAgilityPack,安装到项目中。
VS中引入HtmlAgilityPack
当然也可以采用手动引用dll文件的方式实现对该类库的引用,在此不做细述。
3、解析列表
列表页地址为http://www.bj.sgcc.com.cn/html/main/col34/column_34_1.html,网页源代码找到列表位置的html,是这样的:
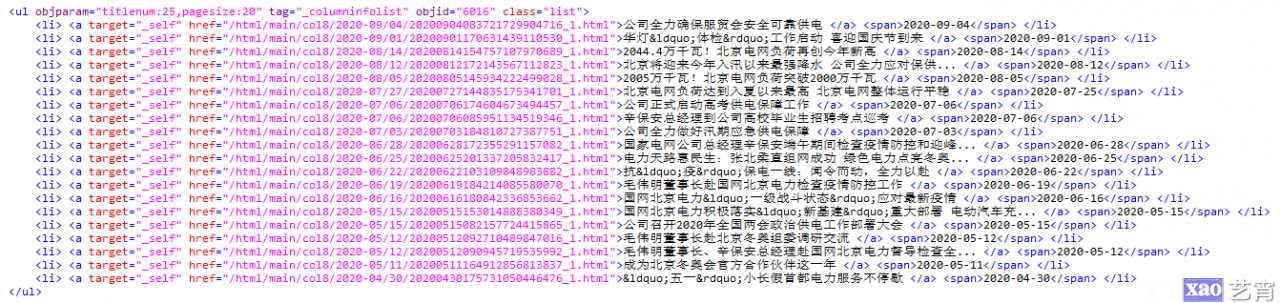
列表页Html结构
在开始解析这段html之前,需要稍微了解下XPath 语法。
XPath(XML Path Language) 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
可以参考https://www.w3school.com.cn/xpath/xpath_syntax.asp来深入了解XPath,本文将通过实际应用来解释其用法。
新闻列表的循环体是个ul,我们通过他的class=”list”来定位到唯一的元素块。
- “titlenum:25,pagesize:20” tag=
“_columninfolist”
- objid=
“6016”class
- =
“list”
- >
<li> <a target=“_self” href=“/html/main/col8/2020-09/04/20200904083721729904716_1.html”>公司全力确保服贸会安全可靠供电 a><span>
- 2020-09-04
span
- >
li
- >
<li> <a target=“_self” href=“/html/main/col8/2020-09/01/20200901170631439110530_1.html”>华灯“体检”工作启动 喜迎国庆节到来 a><span>
- 2020-09-01
span
- >
li
- >
用以下代码获得所有
- 的集合:
string url = "http://www.bj.sgcc.com.cn/html/main/col34/column_34_1.html"; //要抓取页面的地址
//使用WebRequest获取指定网页的源代码
System.Net.WebRequest rGet = System.Net.WebRequest.Create(url);
System.Net.WebResponse rSet = rGet.GetResponse();
System.IO.Stream s = rSet.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(s, System.Text.Encoding.GetEncoding("utf-8")); //注意编码与源网页一致
//sourceHtml为页面返回的html
string sourceHtml = reader.ReadToEnd();
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(sourceHtml);
HtmlAgilityPack.HtmlNodeCollection list = doc.DocumentNode.SelectNodes("//ul[@class=\'list\']/li");最后一句doc.DocumentNode.SelectNodes(“//ul[@class=\’list\’]/li”);得到了所有
- 的集合。我们看一下SelectNodes方法里面的参数“//ul[@class=\’list\’]/li”。
首先双斜杠//含义:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
//ul[@class=\’list\’]的含义是,找到文档中class等于list的ul元素。也可以通过元素的id、style等定位,原则就是能得到唯一的元素。
后面紧跟的/li会匹配到上个节点内的所有
- 元素,这样就得到了所有的循环内容集合。
4、通过循环分别解析出新闻详情
在这一步,在循环内分别获取每条新闻的详情页地址,然后WebRequest获取内容页源代码,再解析出标题、发表时间和详情。
先获取一条新闻详情页的源代码,看看Html内容,找到需要的部分:
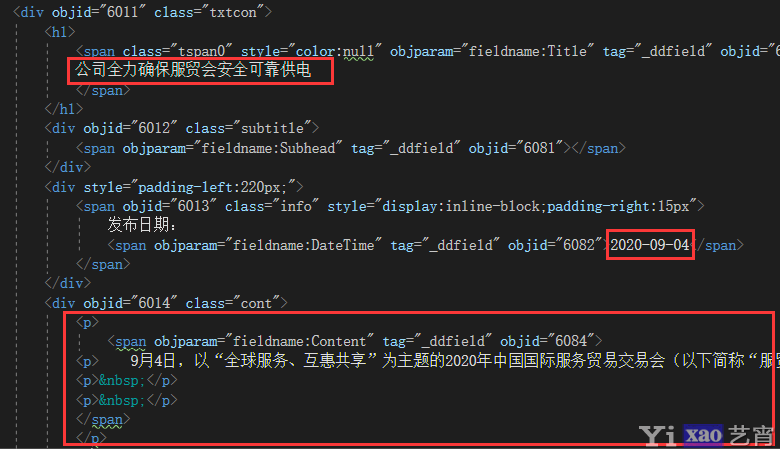
详情页Html结构
看得出,包含它们最近的节点是
HtmlAgilityPack.HtmlNode sectionNode = docContent.DocumentNode.SelectSingleNode("//div[@class=\'txtcon\']");
title = sectionNode.SelectSingleNode("h1/span").InnerText;
dateandtime = sectionNode.SelectSingleNode("div[2]/span/span").InnerText;
detail = sectionNode.SelectSingleNode("div[@class=\'cont\']").InnerText;1)解析标题的内容时,节点内的元素块只有唯一的
,通过h1/span可以得到准确的标题内容。
2)解析发布时间时,div[2]/span/span其中的div[2]表示该节点内的第二个div元素,也就是发表时间所在的
3)解析详情时用了div[@class=\’cont\’],通过class属性来定位,当然也可以用类似解析发布时间时的div[3]。
用一个单独的详情页测试解析没问题后,下一步就可以嵌套到上一步的循环中了。
5、组合列表页和详情页,完成循环解析插入
首先将获取网页源代码的方法提取出来,方便调用。方法为string GetUrlContent(string url),传入参数为页面地址。
HtmlAgilityPack.HtmlNodeCollection list = doc.DocumentNode.SelectNodes("//ul[@class=\'list\']/li");
foreach (HtmlAgilityPack.HtmlNode item in list)
{ HtmlAgilityPack.HtmlNode a = item.SelectSingleNode("a");
href = a.Attributes["href"].Value;
string contentUrl = "http://www.bj.sgcc.com.cn/" href;
string contentDetail = GetUrlContent(contentUrl);
docContent.LoadHtml(contentDetail); HtmlAgilityPack.HtmlNode sectionNode = docContent.DocumentNode.SelectSingleNode("//div[@class=\'txtcon\']");
title = sectionNode.SelectSingleNode("h1/span").InnerText;
dateandtime = sectionNode.SelectSingleNode("div[2]/span/span").InnerText;
detail = sectionNode.SelectSingleNode("div[@class=\'cont\']").InnerText;
Response.Write(title "
" dateandtime "
" detail "");
}循环体内简单粗暴的用Response.Write()显示出解析到的内容,此处更换成插入数据操作即可。
看一下运行后的结果:

解析出的内容
本实例完整的代码下载地址(百度网盘):
链接:https://pan.baidu.com/s/1l_ivgv3mKXm8JY-8NIs-iA
提取码:6ipg
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/share/11694.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
ElasticSearch中的中文分词器以及索引基本操作详解
1.ElasticSearch 分词器介绍 1.1 内置分词器 ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。查询分析则主要分为两个步骤: 词条化…
-
Xvue-UI:响应式Vue.js前端组件化框架
今天给小伙伴们推荐一款超不错的Vue轻量级组件框架XVueUI。 xvue-ui 基于vue2.x构建的响应式前端组件化框架。轻量级、易于上手,提供一系列丰富的css和js组件。 …
-
WMS:开源仓库管理系统
一、项目简介 WMS–开源仓库管理系统 二、实现功能 发货管理 库存管理 财务中心 商品管理 基础设置 仓库设置 用户管理 司机管理 三、技术选型 python dja…
-
整合SpringSecurity+JWT实现登录认证
SpringBoot实战电商项目mall(25k star)地址:https://github.com/macrozheng/mall 摘要 学习过我的mall项目的应该知道,ma…
-
Code-Server:在浏览器上运行VScode的工具
Code-Server是一个可以在远程服务器上运行VScode的工具。 通过浏览器访问,它可以在Chromebook、平板电脑和笔记本电脑上都有一致的开发环境。 推荐原因:前段时间…
-
Vue3自定义PC端弹窗组件:V3Layer
今天给大家分享的是Vue3系列之自定义桌面端对话框组件v3layer。 V3Layer 基于vue3.0构建的多功能PC网页端弹窗组件。拥有超过10 种弹窗类型、30 种参数配置,…
-
10个提升web开发人员效率的工具网站
介绍 作为开发人员,我们每天都有很多任务要做,我们迫切地需要一些工具来使我们的工作更轻松并帮助我们提高生产率。在线上有很多专门为开发人员创建的工具,对我们有很多好处。 在本文中,我…
-
五款顶级的Docker容器GUI工具
你是否还在大量控制台窗口中监控容器,还是对使用终端命令充满热情?而使用Docker的图形用户界面(GUI)工具,则可以更简单的对容器进行管理,并提高效率。而且它们都是免费的。 Po…
-
Linode优秀VPS主机使用体验-Linode VPS性能速度评测与使用问题集合
Linode是美国一家非常有名的VPS主机商,2003年创建成立并提供VPS主机,专注提供运行 Linux 的服务器已经十来年了。早年,Linode VPS卖的价格非常高,同类月付…
-
Spring Boot Flyway数据库
Flyway是一个版本控制应用程序,可以在所有实例中轻松可靠地演变数据库模式。 许多软件项目使用关系数据库。 这需要处理数据库迁移,通常也称为模式迁移。 在本章中,将详细了解如何在…