在写爬虫的时候,为了效率我们通常会选择解析网页api来获取数据,但是有时候解析方式比较困难,或者我们纯粹是为了快速实现爬虫,会使用浏览器自动化操作,说起这一点,肯定第一个想到的就是selenium,但很多时候其实selenium使用起来是不太方便的,例如环境配置,要安装浏览器、下载对应的驱动、安装对应的Python selenium库,而且各个工具的版本还要匹配,大规模部署时就比较麻烦。
下面我们介绍另一个工具-pyppeteer
Pyppeteer简介
pyppeteer是puppeteer的Python版本,而puppeteer是什么呢?puppeteer是Google基于Node.js开发的一个工具,它可以使我们通过JavaScript来控制Chrome浏览器执行一些操作,拥有丰富的API,功能非常强大,因此也可以用于网络爬虫。pyppeteer是一位日本的程序员根据Puppeteer开发的非官方Python版本。
在Pyppeteer中,它操作的是一个类似Chrome的Chromium浏览器,Chromium是相当于Chrome的开发版,是完全开源的,Chrome的所有新功能都会先在Chromium上实现,稳定后才会移植到Chrome上,因此Chromium会包含很多新功能。Pyppeteer就是依赖于Chromium来运行的,当我们第一次运行Pyppeteer的时候,如果Chromium没有安装,那么程序会自动帮我们安装和配置,省去了环境配置这一步。
下面我们详细了解一下Pyppeteer的用法。
安装
因为Pyppeteer采用了async机制,所以必须使用Python 3.5及以上版本。
使用pip安装非常简单:
pip install pyppeteer使用时直接导入:
import pyppeteer使用
接下来我们使用豆瓣电影排行榜https://movie.douban.com/chart来作为测试

下面我们用Pyppeteer来试一下,代码如下:
import asyncio
from pyppeteer import launch
from lxml import etree
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto(\'https://movie.douban.com/chart\')
await page.waitForXPath(\'//table//a[@title]\')
doc = etree.HTML(await page.content())
names = [element.attrib[\'title\'] for element in doc.xpath(\'//table//a[@title]\')]
print(\'Names: \', names)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())运行结果:
Names: [\'誓血五人组\', \'给我翅膀\', \'黑帮大佬和我的365日\', \'爱情人偶\', \'忠贞\', \'鲁邦三世 The First\', \'大饿\', \'火口的两人\', \'知晓天空之蓝的人啊\', \'野性的呼唤\']代码的大体意思是访问网站,然后等待//table//a[@title]的节点加载出来,再通过xpath从网页源码中解析出电影名并输出,最后关闭Pyppeteer。具体过程如下:
- launch 方法新建一个Browser对象,赋值给browser变量,这一步就相当于启动了浏览器
- 然后browser调用newPage方法相当于新建一个选项卡,并且返回一个Page对象,这一步还是一个空白的页面,并未访问任何页面
- 然后Page调用goto方法,就相当于访问此页面
- Page对象调用waitForXpath方法,那么页面就会等待选择器所对应的节点信息加载出来,如果加载出来就立即返回,否则就会持续等待直到超时。这里就比selenium的等待元素加载完毕要清晰的多了。
- 页面加载完成后再调用content方法,获取渲染出来的页面源代码
- 最后从页面源码中提取出电影名称
另外当中还用到了asyncio的相关知识,因为Pyppeteer是基于asyncio实现的异步,所以这块知识需要先了解一下。
通过上面这个示例,我们看到Pyppeteer比Selenium要简洁的多,而且环境配置也方便,直接自动帮我们实现了环境配置。接下来我们再尝试设定浏览器窗口大小,并进行网页截图,然后执行一段自定义的JavaScript脚本,代码如下:
import asyncio
from pyppeteer import launch
async def main():
width, height = 1366, 768
browser = await launch()
page = await browser.newPage()
await page.setViewport({\'width\': width, \'height\': height})
await page.goto(\'https://movie.douban.com/chart\')
await page.waitForXPath(\'//table//a[@title]\')
await asyncio.sleep(2)
await page.screenshot(path=\'example.png\')
dimensions = await page.evaluate(\'\'\'() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}\'\'\')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())执行结果:
{\'width\': 1366, \'height\': 768, \'deviceScaleFactor\': 1}这里我们完成了页面窗口大小的设置、网页截图保存、执行了JavaScript并返回了对应的数据。图片如下:
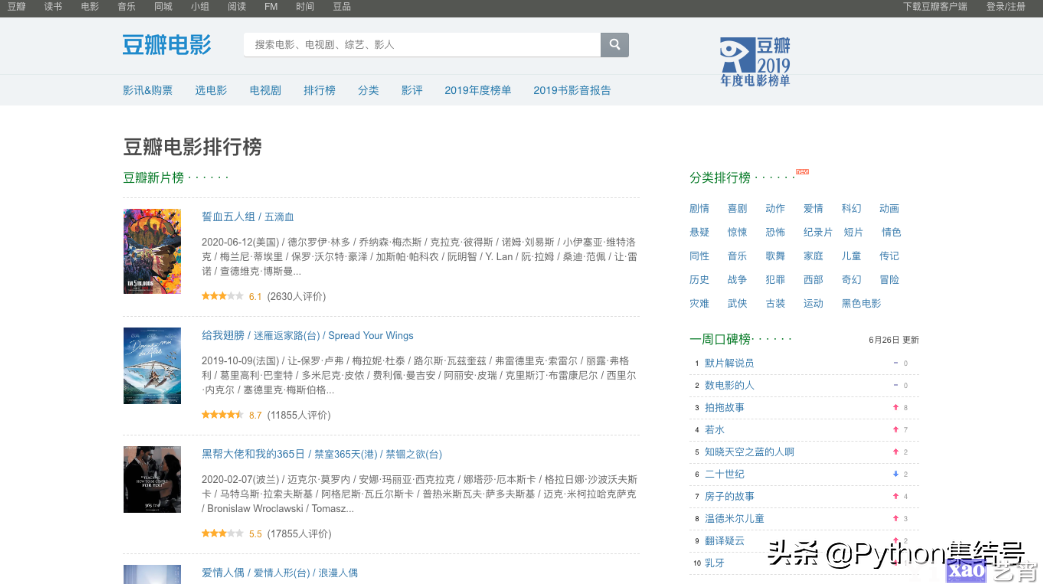
我们这里是全屏截图,screenshot方法还可以指定保存格式、清晰度、是否全屏、裁剪等。从截图我们可以看到和我们在浏览器中看到的一样,并且在evaluate方法中执行的JavaScript返回了网页的宽高、像素大小比率的值。
今天我们简单介绍Pyppeteer的使用,更加详细的介绍可以在Pyppeteer的官方文档https://miyakogi.github.io/pyppeteer/reference.html中进行查找,不必死记硬背。下一篇我们介绍一些常用的Pyppeteer对象和使用模式。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/share/13187.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
下载软件时老司机也会湿鞋!推荐几个良心的下载网站!
现在的下载网站鱼龙混杂,原本是为了给用户提供下载便利而存在的下载网站,反而常常成为侵害用户权益的源头之一。 不少软件下载站存在的用户侵权行为你一定遇到过: (1)诱导安装——一个页…
-
DoraCMS–高质量Vue+Egg.js后台内容管理
今天给大家推荐一款超不错的CMS内容管理系统DoraCMS-Admin。 dora-cms 基于vue.js eggjs express mongodb构建的一套后台CMS管理系统…
-
你想下载的所有win10版本全在这里,微软官方原版ISO
Windows 10是Windows操作系统的一个里程碑,微软公司在2015年7月发布了第一版,至今已经发布了11个版本,基本上每年发布二次更新,上半年、下半年各一次,这些不断更新…
-
新媒体运营需要的100款工具软件,持续更新中!
大家好,晚上睡不着,总结总结新媒体,自媒体运营都需要哪些软件,本来打算给大家一一列举出来,感觉有点麻烦,这里直接搞了个思维导图! 想当年,我月薪才刚刚2000多,经过两年,哥也算是…
-
Semgrep:GitHub标星4.2K的轻量化代码扫描工具
Semgrep,是一个快速、开源的静态代码扫描工具,能够自动检测代码中的 Bug,同时能够在编辑器、Commit、Ci 的过程中规范项目中的代码。Semgrep 在本地分析你的项目代码,不会上传任何的代码。
-
微软系列MAK激活密钥分享
剩余次数为0的适用于电话激活,有次数显示的才可以直接在线激活。密钥检测工具在此! PS:微软每周会更新一批密钥,本站也会跟进!没有密钥的时候也可以暂时使用HEU_KMS工具激活。 …
-
Sa-Token:一款功能强大的权限认证框架,用起来够优雅
在我们做SpringBoot项目的时候,认证授权是必不可少的功能!我们经常会选择Shiro、Spring Security这类权限认证框架来实现,但这些框架使用起来有点繁琐,而且功…
-
Ruffle:开源的Flash Player模拟器
Ruffle 除了支持在 Chrome、Edge、Firefox、Safari 浏览器上 安装插件 进行使用以外,还提供 Windows、macOS、Linux 桌面平台上 加载本地文件 进行播放,除此之外还提供 JavaScript 给 开发者 使用。
-
高精度IP定位网站 根据IP查找真实地理位置
以前的IP定位只能定位到某个城市,或者是你所在的区,反正就是一个大概的位置,定位准确度不是很高。 而最近这一两年,网上出现了不少高精度IP定位网站,所谓的高精度定位,就是指定位的精…