1 说明:
=====
1.1 python的数据管理的库有很多,我还是觉得tablib库简单好用。
1.2 Tablib 是一个与表格格式数据有关的Python库,允许导入、导出、管理表格格式数据。
1.3 适合多种格式:
Excel (Sets Books)
JSON (Sets Books)
YAML (Sets Books)
HTML (Sets)
TSV (Sets)
CSV (Sets)

好好学习,进入大数据时代了,如何管理数据很重要!
2 官网:
=====
https://github.com/jazzband/tablib
https://tablib.readthedocs.io/en/stable/
https://pypi.org/project/tablib/3 安装:
=====
pip install tablib
#本机安装
#sudo pip3.8 install tablib4 xls格式:
=======
4.1 代码:
#---数据导出xls:方法一---
import tablib
#表头,支持中文
headers = (\'序号\', \'用户\', \'年龄\')
#数据
data = [
(\'1\', \'Rooney\', 20),
(\'2\', \'John\', 30),
]
#数据集合
data = tablib.Dataset(*data, headers=headers)
#打开或者新建一个1.xls,wb方式
table = open("/home/xgj/Desktop/tablib/1.xls", "wb")
#写入
table.write(data.xls)
#关闭
table.close()4.2 操作示意和效果图:
4.3 上述代码还可以这样修改,推荐这种,效果一样:
#---数据导出xls:方法二:推荐这种---
import tablib
#表头,支持中文
headers = (\'序号\', \'用户\', \'年龄\')
#数据
data = [
(\'1\', \'Rooney\', 20),
(\'2\', \'John\', 30),
]
#数据集合
data = tablib.Dataset(*data, headers=headers)
with open(\'/home/xgj/Desktop/tablib/2.xls\',\'wb\') as f:
#f.write(data.xls)
f.write(data.export(\'xls\')) #与上面相同4.4 增加行和列;删除行和列
#---数据导出xls:增加行和列---
import tablib
#表头,支持中文
headers = (\'序号\', \'用户\', \'年龄\')
#数据
data = [
(\'1\', \'Rooney\', 20),
(\'2\', \'John\', 30),
]
#数据集合
data = tablib.Dataset(*data, headers=headers)
#增加行
data.append([\'3\', \'Keven\',18])
data.append([\'4\', \'tom\',22])
#增加列
data.append_col([2200, 2000,1300], header=\'收入\')
#删除行
#del data[1:3] #删除2和3行的数据,列表截取data的索引0,1,2,3,4,1对应第2行数据序号2的数据
#删除列
#del data[\'Age\']
with open(\'/home/xgj/Desktop/tablib/2.xls\',\'wb\') as f:
f.write(data.xls)4.5 读取上述删除行和列的数据,并打印:
import tablib
data = tablib.Dataset()
#读取数据
with open(\'/home/xgj/Desktop/tablib/2.xls\', \'rb\') as f:
data.load(f, \'xls\')
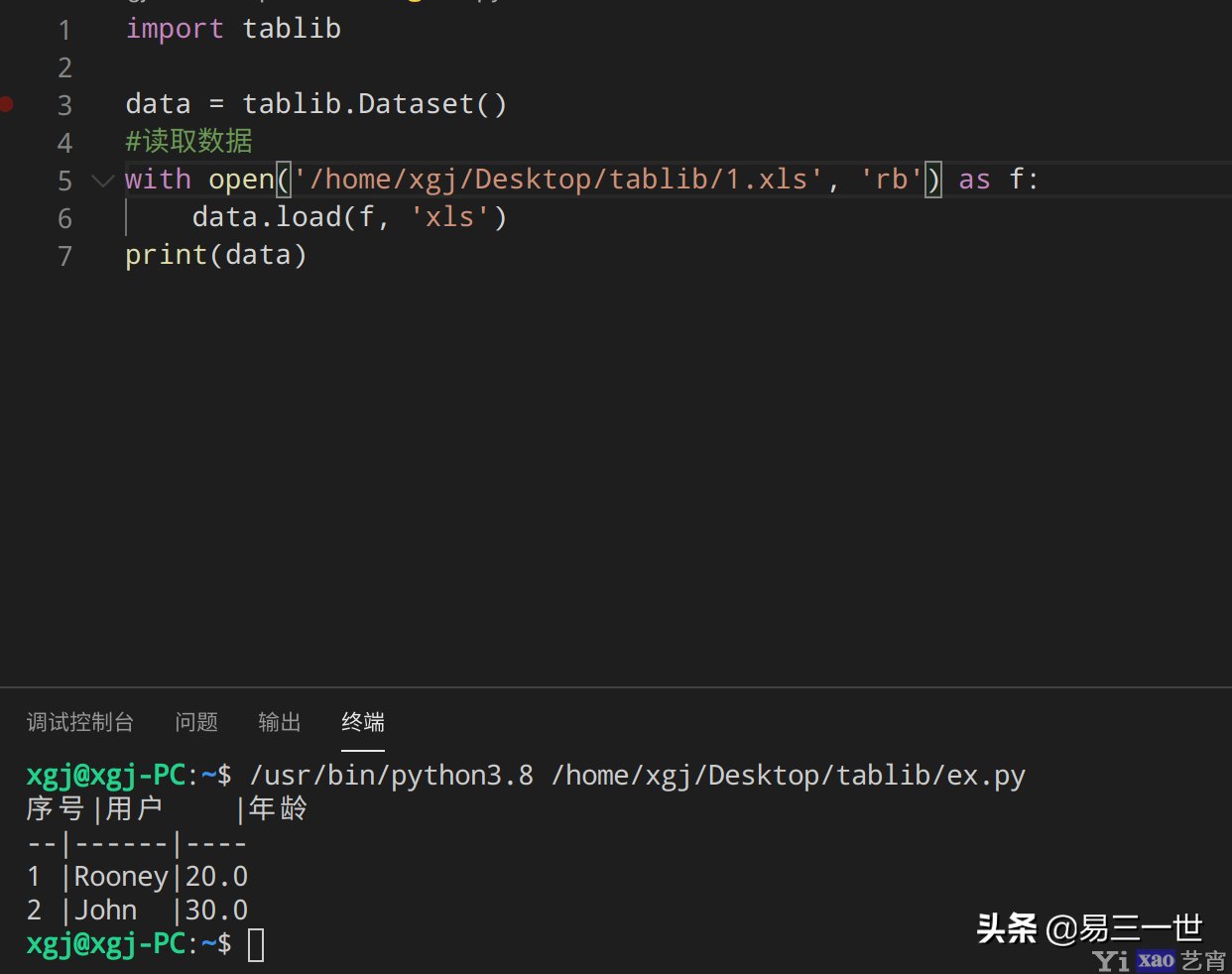
print(data)序号|用户 |年龄
--|------|----
1 |Rooney|20.0
4 |tom |22.05 csv格式:
========
5.1 代码:
#---数据导出csv
import tablib
#表头,支持中文
headers = (\'序号\', \'用户\', \'年龄\')
#数据
data = [
(\'1\', \'Rooney\', 20),
(\'2\', \'John\', 30),
]
#数据集合
#dialect=\'unix\'
#data=tablib.Dataset(*data, format=\'csv\', headers=False) #表头隐藏
data=tablib.Dataset(*data, format=\'csv\', headers=headers) #表头显示,注意这里不是True
#csv的特色
data.export(\'csv\', delimiter=\' \', quotechar=\'|\')
#指定路径和文件名
with open(\'/home/xgj/Desktop/tablib/3.csv\', \'w\', newline=\'\') as f:
f.write(data.export(\'csv\'))5.2 效果图:
6 json格式:
========
6.1 代码:
import tablib
#表头
headers = (\'序号\', \'用户\', \'年龄\')
#数据
data = [
(\'1\', \'Rooney\', 20),
(\'2\', \'John\', 30),
]
dst = tablib.Dataset(*data, headers=headers)
print(dst) #终端输出表格格式
#encoding=\'utf8\'
with open(\'/home/xgj/Desktop/tablib/4.json\', mode=\'w\',encoding=\'utf8\') as f:
#f.write(dst.json)
f.write(dst.export(\'json\')) #与上面相同
#ensure_ascii=False
print(dst.json) #终端输出json格式
#已经被转换成Unicode码,如:"\u5e8f\u53f7"=\'序号\'#终端输出效果
序号|用户 |年龄
--|------|--
1 |Rooney|20
2 |John |30
[{"\u5e8f\u53f7": "1", "\u7528\u6237": "Rooney", "\u5e74\u9f84": 20}, {"\u5e8f\u53f7": "2", "\u7528\u6237": "John", "\u5e74\u9f84": 30}]6.2 解决这个问题:#已经被转换成Unicode码,如:”\u5e8f\u53f7″=\’序号\’
#解决办法用python的 json模块,顺带复习
import json
with open("/home/xgj/Desktop/tablib/4.json", "r", encoding=\'utf-8\') as f:
aa = json.loads(f.read())
f.seek(0)
bb = json.load(f) # 与 json.loads(f.read())
print(aa)
print(bb)#终端输出效果图
[{\'序号\': \'1\', \'用户\': \'Rooney\', \'年龄\': 20}, {\'序号\': \'2\', \'用户\': \'John\', \'年龄\': 30}]
[{\'序号\': \'1\', \'用户\': \'Rooney\', \'年龄\': 20}, {\'序号\': \'2\', \'用户\': \'John\', \'年龄\': 30}]7 读取数据:
7.1 图


7.2 读取xls
7.2.1 代码:
import tablib
data = tablib.Dataset()
#读取数据
with open(\'/home/xgj/Desktop/tablib/1.xls\', \'rb\') as f:
data.load(f, \'xls\')
print(data)7.2.2 图:
csv省略
7.3 读取json
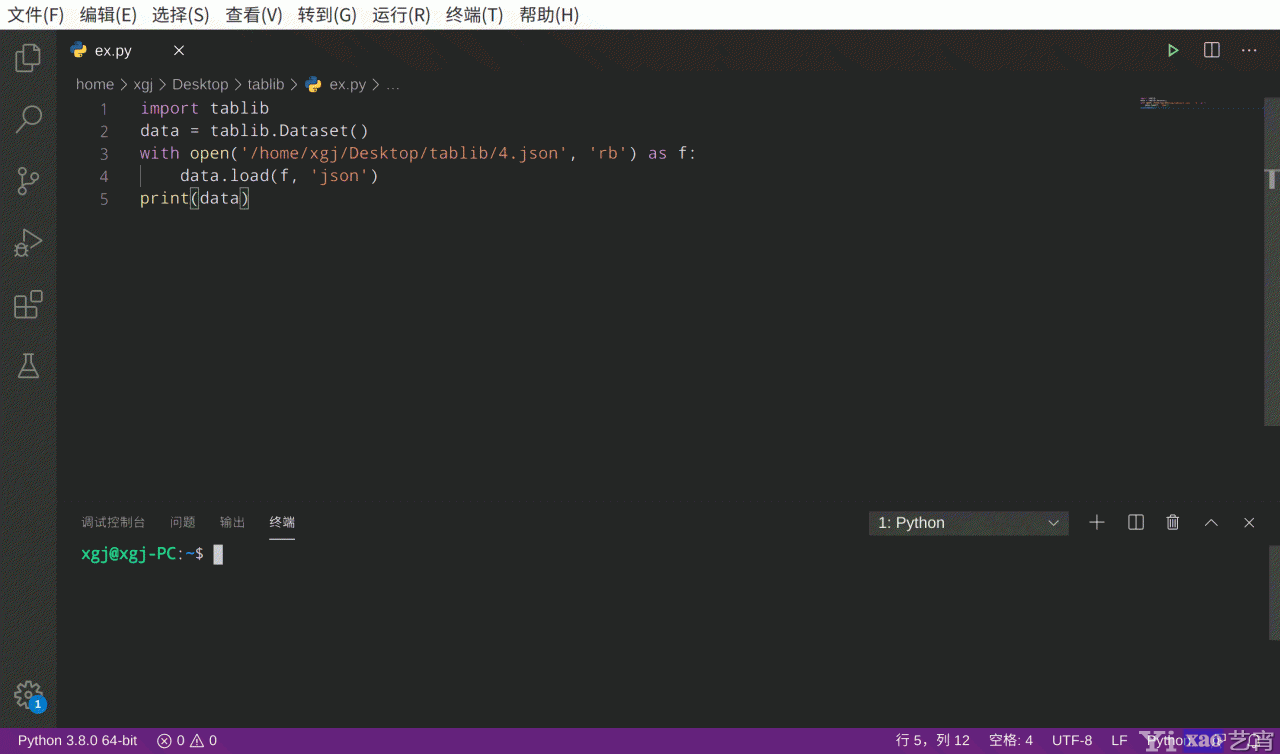
7.3.1 代码:比6.2代码简单吧,跳过json模块的load和loads的知识。
import tablib
data = tablib.Dataset()
with open(\'/home/xgj/Desktop/tablib/4.json\', \'rb\') as f:
data.load(f, \'json\')
print(data)7.3.2 效果图:
8 df格式和yaml格式:了解一下。
超级简单。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/share/19706.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
Plupload–web编辑器TinyMCE团队开发的上传组件
Plupload是一款由web编辑器TinyMCE团队开发的上传组件。 Plupload拥有多种上传方式:HTML5、flash、silverlight以及传统的<input…
-
Resynth,用「推箱子」的方式玩音乐节奏游戏丨App+1
自 Planet Quest 之后,iOS 就没有让我印象深刻的音乐节奏游戏了。魔性、动感、又不需要过多的音乐细胞,是我喜爱的音游应该具备的一些元素,近日上架的 Resynth,可…
-
微软Windows10 21H1正式版官方 ISO 镜像下载大全
微软开始推送 2021 年 Windows 10 更新五月版(21H1)系统更新,现在包括微软 Windows 10 官网工具、MSDN 订阅网站都已经发布了 Windows 10…
-
tmaic:一套简洁、优雅的Golang Web开发框架
tmaic 是一套简洁、优雅的Golang Web开发框架(GoLang Web Framework)。支持mysql,mssql等多类型数据库,它可以让你从面条一样杂乱的代码中解…
-
50+款手机端H5框架炸裂推荐
现如今移动端开发领域H5势头越来越猛,不管是H5小应用、小游戏,还是hybrid混合开发都有不少市场。原生端APP开发越来越不能满足快速迭代的诉求。而随着手机硬件配置的不断增强。以…
-
查看显示器拖影的网站
有的朋友买到笔记本感觉屏幕有拖影,其实可以上这个网站测试一下。这个网站可以让你比较不同帧数下的画面,有30帧/60帧等对比,包括游戏画面和文本浏览等对比。右上角Chase Squa…
-
各大共享单车月卡活动领取地址分享!
下面给大家带来了目前全网最全的各大共享单车月卡活动领取地址,目前包含ofo小黄车、优拜单车、哈罗单车! ofo小黄车:http://common.ofo.so/campaign/m…
-
通过制作原创视频做视频营销赚钱,可赚钱的视频工具【附AE模板、AE教程等素材】
都是一些小套路,但却是赚钱做项目必备技巧和工具。 举牌图 微商、广告、成交文案、装逼等各个领域,均能用到。 制作方法: A.网上有很多举牌照PSD源文件,搜索并下载,用Photos…
-
Viewer.js–优秀的Web图片预览+图片裁剪插件
介绍 Viewer.js 是一款强大的图片预览查看器,之前在做项目的时候遇到的是无法给网页中的图片添加一个强大的预览功能,而Viewer.js刚好满足了我的需求。本文就简单的介绍一…
-
Rust语言编写的免费开源的远程控制软件
RustDesk是一款免费开源的远程控制软件,采用Rust语言编写。它具有以下特点:– 自动适应可用带宽:能够根据用户的网络条件自动调整数据传输速度,以适应不同的网络环…