前言
如今大型的IT系统中,都会使用分布式的方式,同时会有非常多的中间件,如redis、消息队列、大数据存储等,但是实际核心的数据存储依然是存储在数据库,作为使用最广泛的数据库,如何将mysql的数据与中间件的数据进行同步,既能确保数据的一致性、及时性,也能做到代码无侵入的方式呢?如果有这样的一个需求,数据修改后,需要及时的将mysql中的数据更新到elasticsearch,我们会怎么进行实现呢?
数据同步方案选择
针对上文的需求,经过思考,初步有如下的一些方案:
- 代码实现
- 针对代码中进行数据库的增删改操作时,同时进行elasticsearch的增删改操作。
- mybatis实现
- 通过mybatis plugin进行实现,截取sql语句进行分析, 针对insert、update、delete的语句进行处理。显然,这些操作如果都是单条数据的操作,是很容易处理的。但是,实际开发中,总是会有一些批量的更新或者删除操作,这时候,就很难进行处理了。
- Aop实现
- 不管是通过哪种Aop方式,根据制定的规则,如规范方法名,注解等进行切面处理,但依然还是会出现无法处理批量操作数据的问题。
- logstash
- logstash类似的同步组件提供的文件和数据同步的功能,可以进行数据的同步,只需要简单的配置就能将mysql数据同步到elasticsearch,但是logstash的原理是每秒进行一次增量数据查询,将结果同步到elasticsearch,实时性要求特别高的,可能无法满足要求。且此方案的性能不是很好,造成资源的浪费。
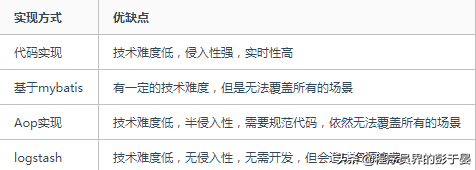

那么是否有什么更好的方式进行处理吗?mysql binlog同步,实时性强,对于应用无任何侵入性,且性能更好,不会造成资源浪费,那么就有了我今天的主角——canal
canal
介绍
canal 是阿里巴巴的一个开源项目,基于java实现,整体已经在很多大型的互联网项目生产环境中使用,包括阿里、美团等都有广泛的应用,是一个非常成熟的数据库同步方案,基础的使用只需要进行简单的配置即可。
canal是通过模拟成为mysql 的slave的方式,监听mysql 的binlog日志来获取数据,binlog设置为row模式以后,不仅能获取到执行的每一个增删改的脚本,同时还能获取到修改前和修改后的数据,基于这个特性,canal就能高性能的获取到mysql数据数据的变更。
使用
canal的介绍在官网有非常详细的说明,如果想了解更多,大家可以移步官网(https://github.com/alibaba/canal)了解。我这里补充下使用中不太容易理解部分。
canal的部署主要分为server端和client端。
server端部署好以后,可以直接监听mysql binlog,因为server端是把自己模拟成了mysql slave,所以,只能接受数据,没有进行任何逻辑的处理,具体的逻辑处理,需要client端进行处理。
client端一般是需要大家进行简单的开发。https://github.com/alibaba/canal/wiki/ClientAPI 有一个简单的示例,很容易理解。
canal Adapter
为了便于大家的使用,官方做了一个独立的组件Adapter,Adapter是可以将canal server端获取的数据转换成几个常用的中间件数据源,现在支持kafka、rocketmq、hbase、elasticsearch,针对这几个中间件的支持,直接配置即可,无需开发。上文中,如果需要将mysql的数据同步到elasticsearch,直接运行 canal Adapter,修改相关的配置即可。
常见问题
- 无法接收到数据,程序也没有报错?
- 一定要确保mysql的binlog模式为row模式,canal原理是解析Binlog文件,并且直接中文件中获取数据的。
- Adapter 使用无法同步数据?
- 按照官方文档,检查配置项,如sql的大小写,字段的大小写可能都会有影响,如果还无法搞定,可以自己获取代码调试下,Adapter的代码还是比较容易看懂的。
canal Adapter elasticsearch 改造
因为有了canal和canal Adapter这个神器,同步到elasticsearch、hbase等问题都解决了,但是自己的开发的过程中发现,Adapter使用还是有些问题,因为先使用的是elasticsearch同步功能,所以对elasticsearch进行了一些改造:
elasticsearch初始化
一个全新的elasticsearch无法使用,因为没有创建elasticsearch index和mapping,增加了对应的功能。
elasticsearch配置文件mapping节点增加两个参数:
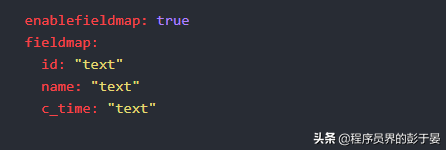
enablefieldmap 是否需要自动生成fieldmap,默认为false,如果需要启动的时候就生成这设置为true,并且设置
fieldmap,类似elasticsearch mapping中每个字段的类型。
esconfig bug处理
代码中获取binlog的日志处理时,必须要获取数据库名,但是当获取binlog为type query时,是无法获取
数据库名的,此处有bug,导致出现 “Outer adapter write failed” ,且未输出错误日志,修复此bug.
后续计划
- 增加rabbit MQ的支持
- 增加redis的支持
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/soft/10287.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
央视影音–官方推出的观看电视直播软件
央视影音 是一款可以 官方推出 的观看 电视直播 软件,由于 移动端 已推出更优质的 央视频 应用,因此仅推荐需要在 Windows 或 macOS 系统上 安装使用 的用户选择它…
-
自腾讯工程师分享:程序员必备工具软件清单
来自鹅厂程序员GG们常用的效率工具分享 一. 开发工具 1)sql2go用于将 sql 语句转换为 golang 的 struct. 使用 ddl 语句即可。例如对于创建表的语句:…
-
免费开源压缩工具7-Zip v17.00 beta
国内外热门免费开源解压缩软件7-Zip更新至 v17.00 beta版,修复了一些错误。7-Zip是一款开源免费的号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而…
-
酷狗无损音乐(.flac格式)下载器
大家都知道现在很多音乐不开会员是很难下载到无损的了 这个小软件非常的简洁,可以搜索,结果只会显示有无损的。下载只能单个下载,用的是迅雷线路下载。软件用C#写的,开源,源码放在Git…
-
swagger-admin v1.3.5 发布
swagger-admin 这是一个Swagger文档管理后台,可统一管理多个项目的Swagger文档,只需要一个Java8环境,下载后即可运行使用。 支持导入json,非Java…
-
Krita 4.4.1正式版发布,开源数字绘画软件
Krita 4.4.1 正式版发布,它是一款自由开源的数字绘画软件,主要针对手绘用途设计,具备高度可定制的笔刷系统和完善的图层功能,可通过透明度和变形蒙版来实现非破坏性编辑。它能够…
-
LNMP1.4环境nginx无法启动的解决方法
之前一台装了LNMP1.4的VPS宕机了,重启后就发现nginx无法启动了。lnmp restart无效,仍然提示nginx(pid) already running。请教小伙伴后…
-
Elasticsearch7.10.0发布
日前Elastic发布了Elasticsearch 7.10.0。该版本基于Apache Lucene 8.7.0开发,支持在Elasticsearch 在线弹性云和自建实例使用,…
-
2021年首个Windows10预览版Build 21286发布:任务栏新增新闻热点功能
面向 Dev 频道的 Windows Insider 用户,微软今天发布了 2021 年首个 Windows 10 预览版 — Build 21286。该版本隶属于 R…
-
只有200M的Win7系统,老爷机电脑的狂喜
说到老爷机适合装什么样系统这个话题,雷锋哥之前给大家推荐过好几个系统了,包括有 Manjaro、Windows Thin PC、Win10 LTSC 等等! 很多人都是希望在老爷机…