RNN已死,注意力万岁?
多年来,我们一直在使用RNN,LSTM和GRU解决顺序问题,您突然希望我们将其全部丢弃吗? 嗯,是!! 所有这三种架构的最大问题是它们进行顺序处理。 而且它们也不擅长处理长期依赖关系(即使使用LSTM和GRU的网络)。 Transformers 提供了一种可并行处理顺序数据的方式,因此,它不仅比以前的体系结构快得多,而且在处理长期依赖性方面也非常出色。


那么什么是 Transformers?
这看起来很恐怖,不是吗? 如果我告诉您所有这些都可以归结为一个公式,是不是就简单一些了?
Attention(Q, K, V) = ∑ᵢ (Similarity (Q, Kᵢ) * Vᵢ)
是的, 上图的复杂体系结构所做的一切,都是为了确保此公式正常运行。 那么这些Q,K和V是什么? 这些不同类型的注意力是什么? 让我们深入研究! 我们将采用自下而上的方法。
输入/输出的嵌入
这些可以是Word2Vec,GloVe,Fastext或任何类型的词嵌入,我们可以在其中将文本转换为某种形式的有意义的向量。 (PS-单词嵌入没有上下文。每个单词只有一个固定的嵌入)
位置编码(PE):
在RNN(LSTM,GRU)中,时间步长的概念按顺序编码,因为输入/输出流一次一个。 对于Transformer,作者将时间编码为正弦波,作为附加的额外输入。 这样的信号被添加到输入和输出以表示时间的流逝。
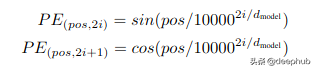
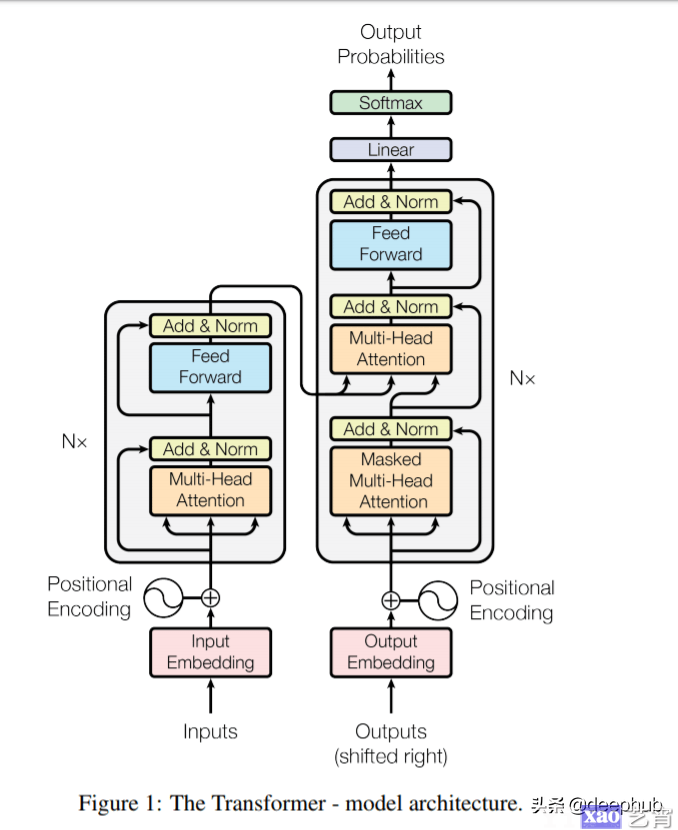
pos是单词的位置i是这个向量的维数。也就是说,PE的每一个维度对应一个正弦曲线。波长以几何级数的形式从2倍级到1万·2倍级。对于偶数(2i)我们使用正弦,对于奇数(2i 1)我们使用余弦。通过这种方式,我们能够为输入序列的每个标记提供不同的编码,因此现在可以并行地传递输入。这个博客(https://kazemnejad.com/blog/transformerarchitecturepositional_encoding/)很好地解释了PE背后的数学原理。
但是,最近的体系结构使用的是”学习的” PE,而不是可以推广到任意长度序列的PE。 而且效果很好。 也就是说,他们不需要将序列推广到比训练中看到的序列更长的序列。 那是因为这些模型的输入大小是固定的(例如BERT的512个令牌)。 因此,在测试期间,他们不会看到更长的序列作为输入。
注意力的类型
编码器自注意力
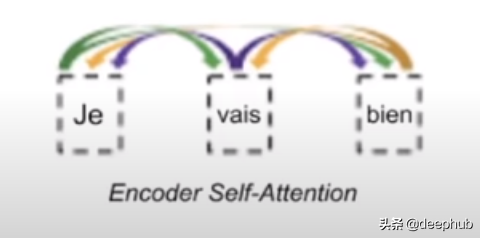
这是一种双向注意(也是唯一一种双向注意力机制,这就是为什么它是BERT中使用的唯一注意力类型),其中每个单词都彼此关联。 它确实捕获了一个句子中的双上下文信息,甚至bi-LSTM也无法捕获(因为bi-LSTM将Forward AR和Backward AR的结果结合在一起,而不是在其核心生成双上下文信息。 这也是从本质上有些人认为ELMo嵌入不是真正的双向的原因。
这种关注的主要目的是在输入中所有其他单词的基础上,根据每个单词在其上下文中的重要性加权,提供按比例表示。
解码器自注意力
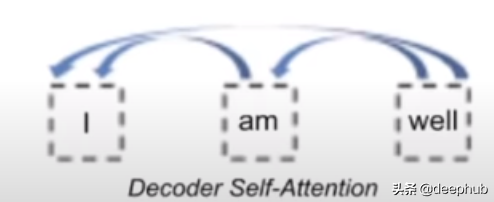
Transformer中的解码器本质上是自回归的,也就是说,输出中的每个单词都与其所有先前的单词相关联,但在进行预测时不与任何将来的单词相关联(AR也可以相反,也就是说,给定将来的单词 ,预测前一个字)。 如果将其与将来的单词联系起来,最终将导致数据泄漏,并且该模型将无法学到任何东西。
编码器-解码器注意:(交叉注意而不是自注意)
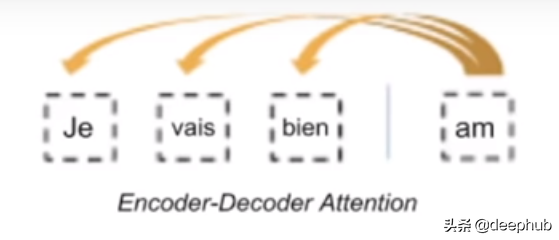
使用注意力的目的是找到输入中所有单词的当前输出单词的链接。 基本上,我们试图在这里找到的是每个输入字对当前输出字的影响。
通过仅使用最后一个解码器层中的”查询”部分以及使用编码器中的”键和值”部分,可以做到这一点。 (因为Query用作所考虑单词的表示形式,Key是所有单词的表示形式,并且用于查找所有单词相对于所考虑单词的权重,Value也是所有单词的表示形式,但 用于找到最终的加权和)
下面的GIF很好地总结了所有三种类型的注意力。

查询(Q),键(K)和值(V)
查询,键和值的概念来自检索系统。例如,当您键入查询以在YouTube上搜索某些视频时,搜索引擎将针对数据库中与候选视频相关的一组键(视频标题,说明等)映射您的查询,然后向您显示最匹配的视频(值)。
Q,K和V基本上是原始单词嵌入之上的线性层,可减小原始单词嵌入的尺寸(为什么要缩减?我稍后会讨论原因)。我们已经将原始单词嵌入投影到了三个不同的(也许是相同的)低维空间中。
基本上,这样想。每当您需要查找两个向量之间的相似性时,我们只需获取它们的点积即可。为了找到第一个单词的输出,我们只考虑第一个单词的表示形式Q,并将其点积与输入中每个单词的表示形式K取乘积。这样,我们就可以知道输入中每个单词相对于第一个单词的关系。
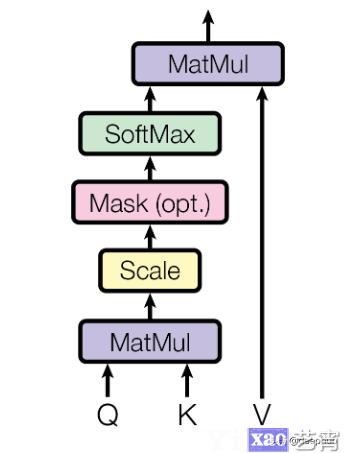
取点积后,我们将结果除以sqrt(dᵏ),其中dᵏ是向量K的维数。这样做是为了稳定梯度,因为点积可能非常大。
我们将上述值的softmax归一化。这样做是因为现在将这些术语视为每个单词相对于第一个单词的权重。
还记得我在帖子开头所说的话吗?那个Transformers就是关于∑ᵢ(相似度(Q,Kᵢ)*Vᵢ)的。好了,我们现在已经完成了方程的∑ᵢ相似度(Q,Kᵢ)部分。现在,我们有了一个分布,该分布描述了输入中每个单词相对于第一个单词的重要性。
为了使方程完整,我们将权重(softmax)与相应的表示V相乘,然后将它们加起来。因此,我们对第一个单词的最终表示将是所有输入的加权总和,每个输入单词均通过相对于第一个单词的相似性(重要性)加权。
我们对所有单词重复此过程。以矢量形式,我们可以用下面给出的方程式来表示它。
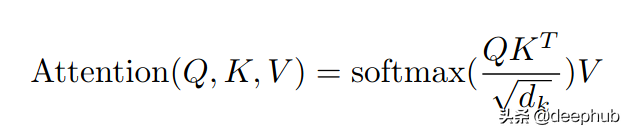
下图很好地总结了整个过程。(稍后我会讲到mask遮罩,它只出现在解码器部分)
多头注意力
直到现在,我们的谈话都是关于单头的注意力的。单头注意力能够将注意力集中在特定的一组单词上。如果我们想拥有多个集合,每个集合对不同的单词集合给予不同的关注呢?(有点类似于我们所做的集合体,有多个类似的模型,但他们每个人都学习不同的东西)一旦我们有多个扩展点积的注意,我们连接结果,多个权重矩阵(因此每个头可以基于其重要性加权)来产生最终的输出Self-Attention层。
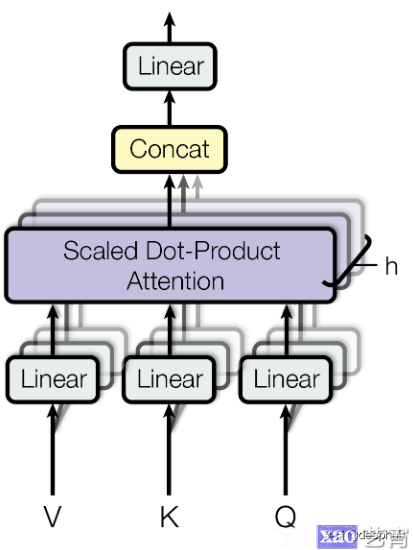
有一个问题仍然没有得到回答。为什么Q、V和K需要被降维向量,即使这样可能会导致原始单词的信息丢失?答案就是多头的自我注意力。假设来自Word2Vec的嵌入输入是(1 x 512),并且我们有8个头注意力。然后我们保持Q K V的维数是1x(512/8)也就是1×64。这样,我们就可以在不增加任何计算能力的情况下使用多头注意力。现在,它学习了24种不同的权重,而不是仅仅3种。
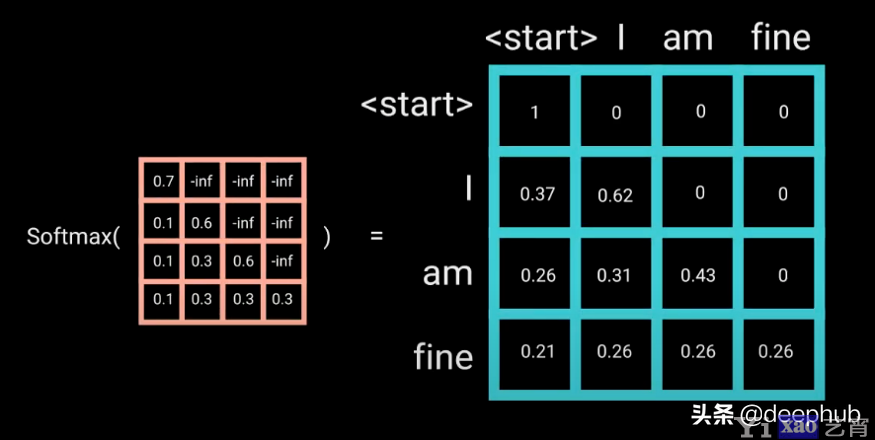
自我注意力的mask遮罩(仅适用于解码器):
Transformers解码器本质上是自回归的,因为如果我们让它在自我注意的过程中看所有的单词,它就学不到任何东西。为了避免这种情况,我们在计算自我注意的同时,在序列中隐藏未来词。
一旦我们计算出序列中所有单词的缩放分数,我们就应用”向前看”遮罩来获得遮罩分数。

现在当我们计算隐藏分数的softmax时,负无穷被归零,留下零的注意力分数给序列中所有未来的记号。
总结一下(6个简单要点):
通过刚才的介绍,我们对Transformer的所有构建块都非常熟悉,那么现在该对它们进行总结了!到现在为止做得很好。 🙂
1、将输入序列中所有单词的单词嵌入添加到它们各自的位置编码中,以获取我们的Transformer的最终输入。
2、Transformer是一个Seq2Seq模型,因此它由编码器和解码器两部分组成。 编码器由N个相同的层组成(原论文中N = 6)。 每层包含以下组件:
· 多头自我注意力层(编码器):获取每个单词的输入向量,并将其转换为表示形式,其中包含有关每个单词应如何与序列中所有其他单词相伴的信息。
· 加法和归一化:多头自我关注层和位置前馈网络的输出均由该层处理。它包含一个残差连接(以确保渐变不会被卡住并保持流动)和归一化层(以防止值变化太大,从而可以更快地进行训练并充当正则化功能)。
· 逐点完全连接层:此层分别且相同地应用于每个单词向量。它由两个线性变换组成,两个线性变换之间使用ReLU激活。
3、计算完所有N层编码器的输出后,最终(键,值)对将传递到解码器的每个”编码器-解码器注意”块。这样就完成了我们的Transformer的编码器部分。
4、由于解码器本质上是自回归的,因此它将先前输出的列表作为输入。然后将令牌转换为词嵌入,然后将其添加到它们各自的位置编码中,以获取解码器的最终输入。
5.解码器还包含N个相同的层(原始论文中N = 6)。每层包含以下组件:
· 多头自我注意力层(解码器):为解码器中的每个位置生成表示形式,以对解码器中的所有位置进行编码,直到该位置为止。我们需要阻止解码器中的向左信息流,以保留自回归属性。
· 多头交叉注意力层(编码器-解码器):这是Transformer的一部分,其中输入和输出字之间发生映射。 (K,V)对来自Encoder,Q值来自Decoder的上一层,然后计算交叉注意力。
· 加法和归一化:类似于编码器。
· 逐点完全连接层:类似于编码器。
6.计算完解码器所有N层的输出后,该输出将通过一个用作分类器的线性层。分类器的大小与vocab大小一样大。然后将其馈入softmax层,以在解码器的所有输出上获得概率分布。然后,我们采用概率最高的索引,该索引处的单词就是我们的预测单词。
Transformer的缺点:
所有的好事都有不好的一面。 Transformer也是如此。
不用说,Transformer是非常大的模型,因此它们需要大量的计算能力和大量的数据进行训练。 (与Transformers相比,reformer的存储效率更高且速度更快。它们基本上已经用局部敏感哈希(LSH)代替了点积的关注。而且,他们使用了可逆残差层而不是标准残差。)
对于用于诸如解析之类的任务的分层数据,RNN似乎要优于Transformers。 一些相关的工作可以在本文(https://www.aclweb.org/anthology/D18-1503/)中找到。
Transformer处理图片
图像不是序列。 但是可以将图像解释为一系列区块,然后通过Transformer编码器对其进行处理。 只需将图像划分为小块,并提供这些小块的线性嵌入序列即可作为Transformer Encoder的输入。 图像区块与NLP下游任务中的标记(单词)的处理方式相同。 此方法可以用来替代当前广泛使用的基于CNN的图像处理管道中的特征提取方法。 视觉处理的Transformer基于此概念。
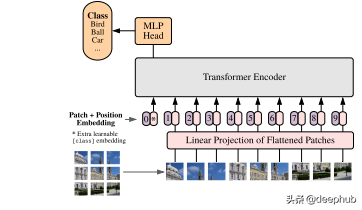
我个人认为本文的设计非常漂亮。https://arxiv.org/pdf/1706.03762.pdf
许多人将”Transformer”视为NLP的ImageNet,现在GPT-3出来的时候也是这么说的,其实这么比较不太恰当,因为毕竟视觉和文本的任务从根本上就是不同的,所以这么比较还是不太恰当,但是Transformer相比于RNN的进步还是有目共睹的。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/12955.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
国产银河麒麟服务器操作系统之Django连接达梦DM8数据库
本文旨在记录作者在银河麒麟服务器操作系统+dm8-rh6+python3.8.11+django-3.1.13+django_dmPython环境下,实现django连接达梦数据库…
-
AppCode2020.3.1 发布,支持Apple Silicon
AppCode 2020.3.1 现已发布,并且用户可以在下载时选择支持 Apple Silicon 的版本。 具体更新内容 1、Swift:OptionSet 成员未在数组中解析…
-
小程序里页面跳转的两种方式
我们在小程序里做页面跳转有两种方式 •1,借助navigator组件•2,借助wx.自带方法,在点击的时候做页面跳转 如下图所示的几个wx.方法 19-1,navigator实现页…
-
SQL优化必备:并行执行框架和执行计划
GaussDB(for openGauss)作为自主研发的新一代金融级分布式关系型数据库,采用可横向扩展的分布式架构,通过 SQL 优化器生成分布式算子以及分布式执行计划,提供了三种 stream 流(广播流、聚合流和重分布流)来降低数据在 DN 节点间的流动
-
DFINITY互联网计算机5月7日正式上线,重塑传统互联网体系
DFINITY团队一直专注于构建互联网计算机,愿景是打造一个以无限制的网络速度运行的区块链计算机。5月7日,DFINITY主网将正式上线,这标志着Internet计算机时代正式开启…
-
工信部组织下架90款APP:天涯社区、大麦、途牛旅游、脉脉等在列
工业和信息化部信息通信管理局发布《关于下架侵害用户权益APP名单的通报》(文末附件为下架名单)对天涯社区、大麦等90款APP进行下架处理,所涉及的问题大多为“违规收集个人信息”“A…
-
如何编译构建spring-framework源码
最近呀,有小伙伴提出 自己在学习 Spring 的时候,这个源码环境有些搞不定。 那这怎么能行,不能因为这点小困难就让小伙伴放弃呀。 这里咱就不在赘述读Spring源码的好处了吧,…
-
Java on Visual Studio Code的更新 – 2021年6月
自从我们开始在Visual Studio Code上发布Java相关的工具后,我们的产品已经经过了大量的迭代以及更新,这当中开发者和社区对我们的支持和反馈功不可没,所以我们非常感谢所有开发者的声音和建议,并请继续提供你们宝贵的意见。