一、简介
关于Java Web的开发周边技术,搜索引擎也是经常被用到的,其中solr和es是被当作技术选型经常出现的,他们都是基于lucene,但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。而今天所讲的es,它是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。


二、安装
首先就是要安装es,它是需要jdk的一个环境,这个想必大家都准备好了,然后去下载es的压缩包,或者用docker去启动一个es的容器,这里下载它的压缩包:
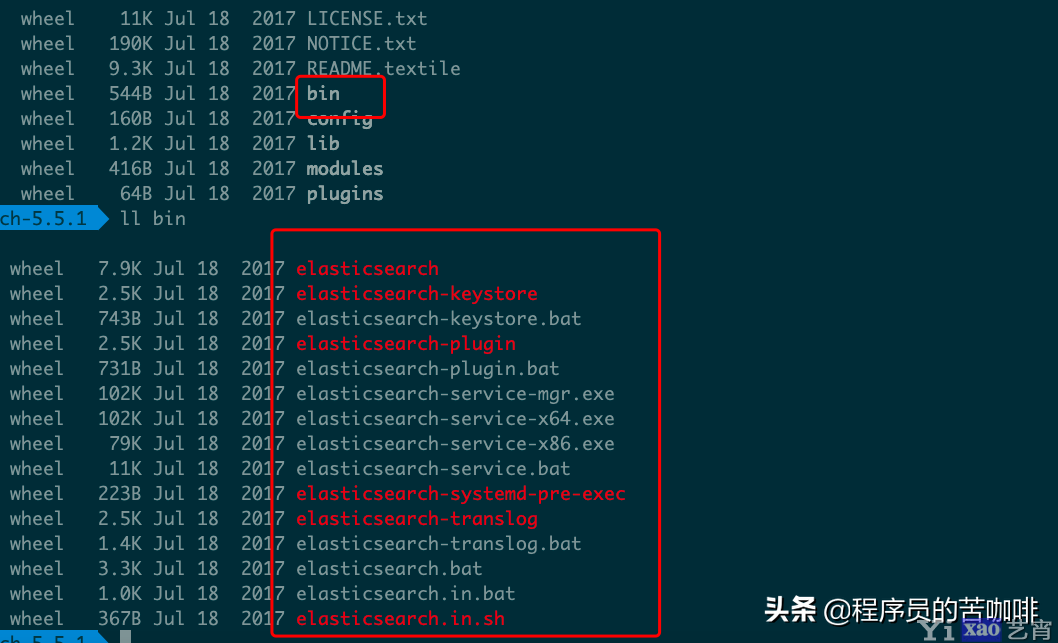
解压刚才下载的压缩包,然后进入bin目录,可以看到一些es的相关命令:
使用bin目录中的elasticsearch命令启动:
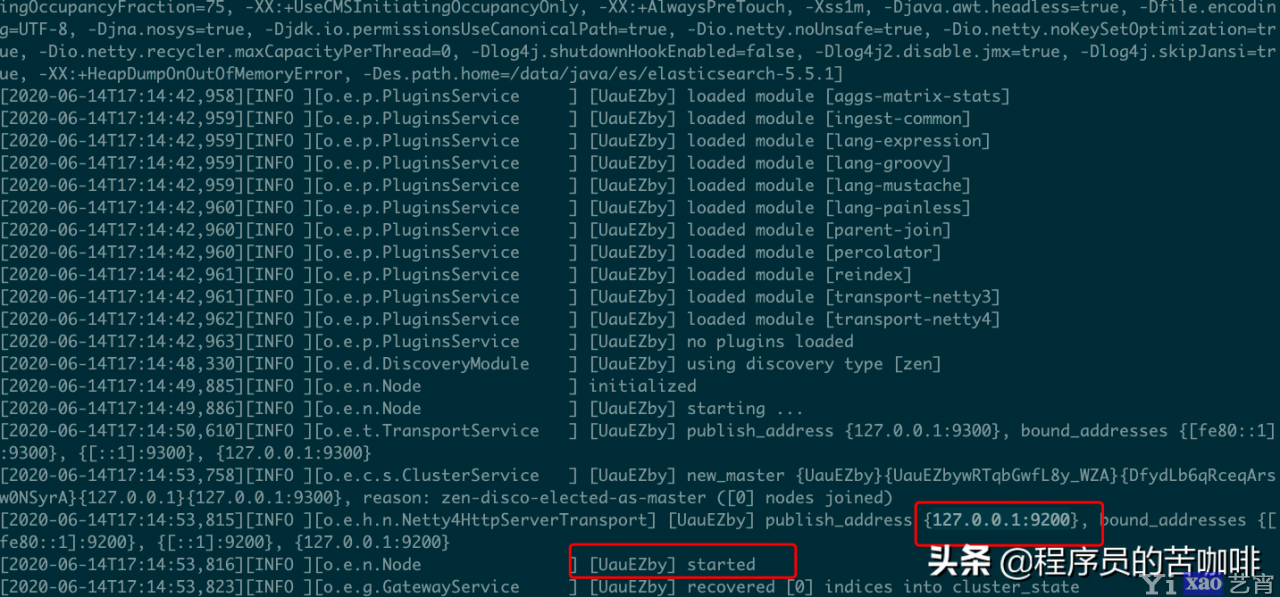
它会启动在9200端口,这是我们可以访问一下http://127.0.0.1:9200/:
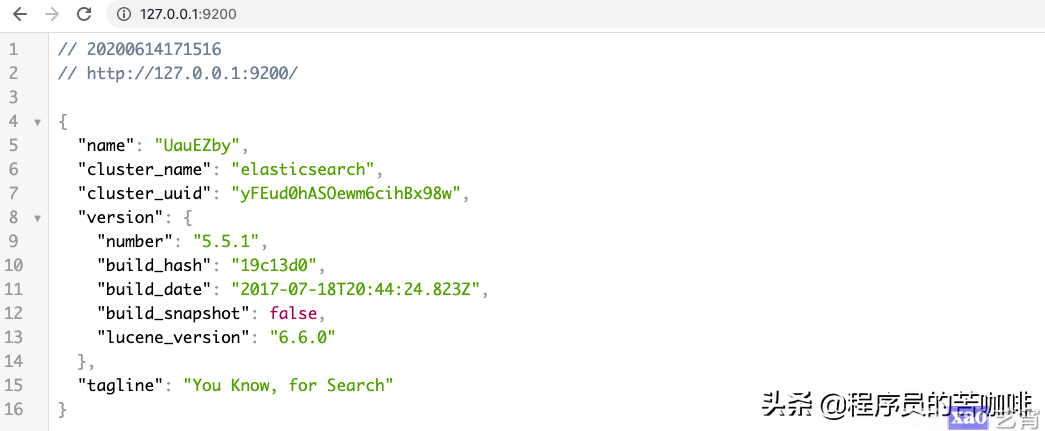
看它的tagline:ou Know, for Search。证明启动成功了,可以开始我们的搜索了。
三:概念
在使用es之前,先来了解一些它的基本概念:
1、Node:单个 Elastic 实例称为一个节点(node)
2、Cluster:一组节点构成一个集群(cluster),Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
3、Index:Elastic 数据管理的顶层单位就叫做 Index(索引),Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
4、Document:Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
5、Type:Document 可以分组,这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
四:中文分词
在搜索引擎中,还有一个重要的设置,那就是中文分词的设置,毕竟国内开发不得不安装这个插件,就像编码处理一样,刚才在bin目录中大家也看到一个命令:elasticsearch-plugin,我们可以利用它来安装中文分词神器-ik中文分词器,安装命令如下:
/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
接着,重新启动 Elastic,就会自动加载这个新安装的插件。
五:数据的操作
1、新建Index,指定需要分词的字段:
命令
curl -X PUT \'localhost:9200/cities\' -d \'
{
"mappings": {
"city": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}\'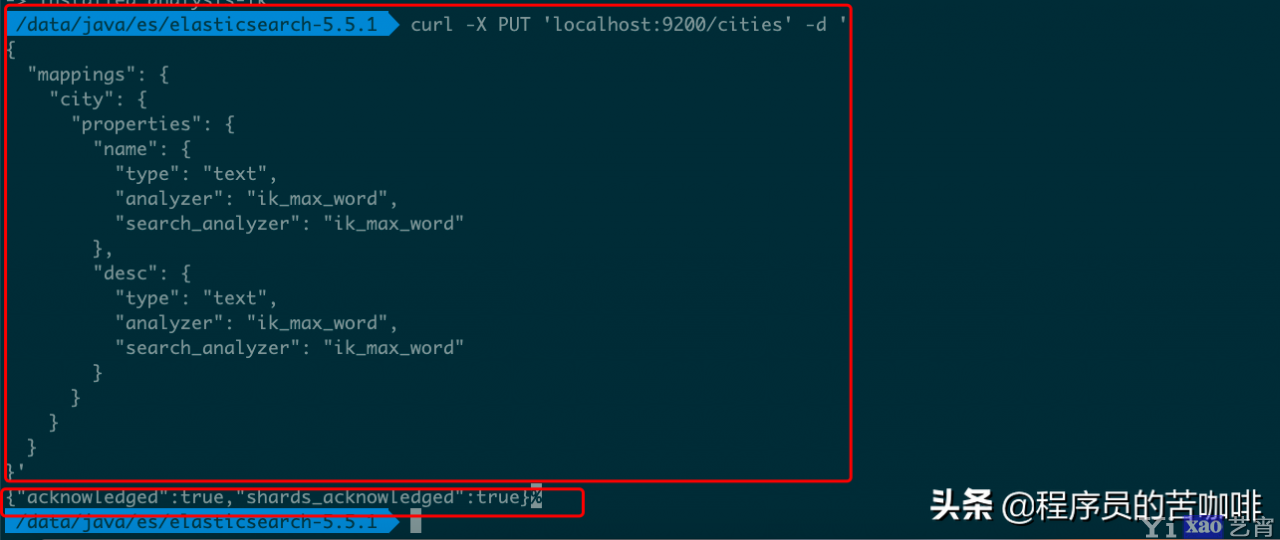
上述操作新建一个名称为cities的 Index,里面有一个名称为city的 Type。person有两个属性:name和desc。analyzer是字段文本的分词器,search_analyzer是搜索词的分词器。ik_max_word分词器是插件ik提供的,可以对文本进行最大数量的分词。{“acknowledged”:true,”shards_acknowledged”:true}是服务器返回的JSON值,acknowledged=true表示操作成功。
2、新增记录
向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录。
命令
curl -X PUT \'localhost:9200/cities/city/1\' -d \'
{
"name": "北京",
"desc": "帝都,北漂的人想出去,外边的人想北漂。"
}\'
如图所示,服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
在请求的路径中,最后的1是该条记录的 Id,它不一定是数字,任意字符串都可以。新增记录的时候,也可以不指定 Id,这时要改成 POST 请求。
命令:
curl -X POST \'localhost:9200/cities/city\' -d \'
{
"name": "上海",
"desc": "上海滩,多少人想成为许文强一样的人物"
}\'
3、查看记录
向/Index/Type/Id发出 GET 请求,就可以查看这条记录。
命令
curl \'localhost:9200/cities/city/1?pretty=true\'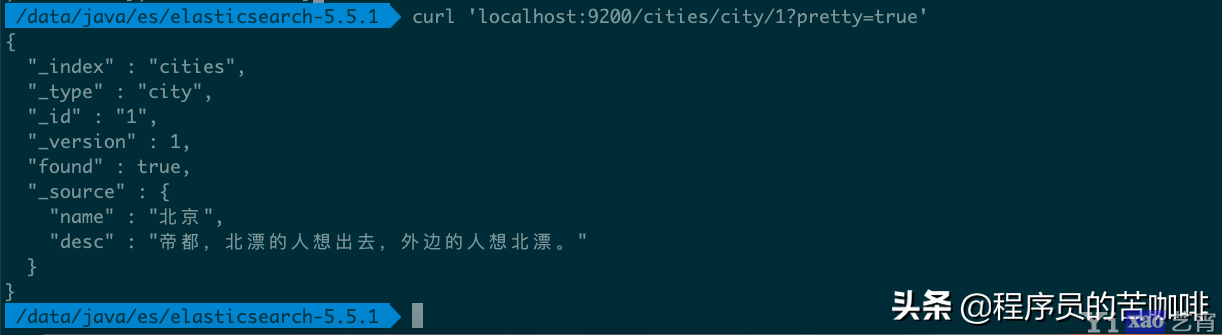
4、删除记录
删除记录就是发出 DELETE 请求。
命令
curl -X DELETE \'localhost:9200/cities/city/1\'
5、更新记录
更新记录就是使用 PUT 请求,重新发送一次数据。
命令:
curl -X PUT \'localhost:9200/cities/city/AXKyTASFQrU13vhMO-rj\' -d \'
{
"name": "上海",
"desc": "上海滩,多少人想成为许文强一样的人物,还需要丁力一样的帮手"
}\'
6、返回所有记录
使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录。我们把刚才删除的北京添加进来,再查询:
命令
curl \'localhost:9200/cities/city/_search\'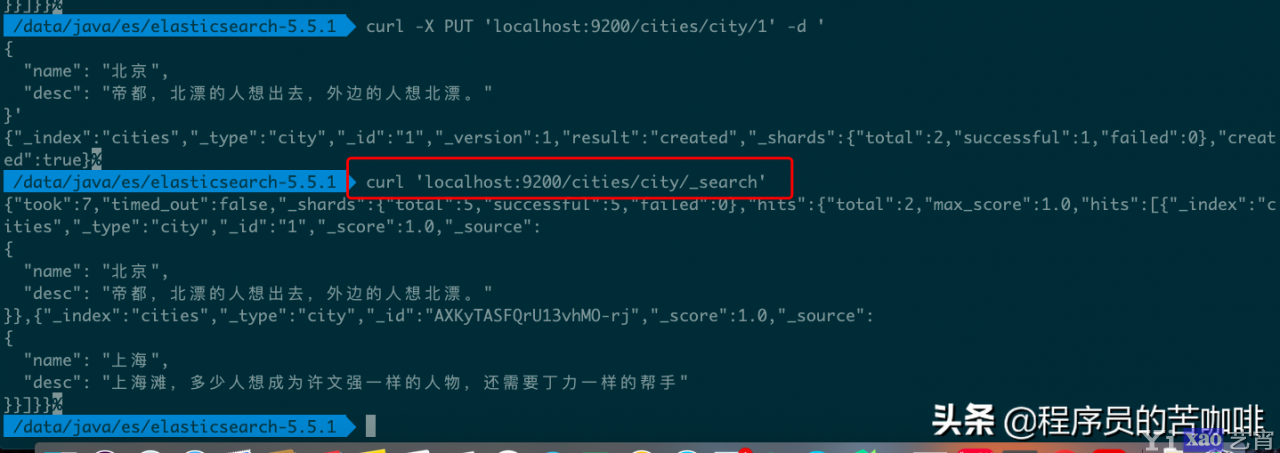
7、全文搜索
Elastic 有自己的查询语法,要求 GET 请求带有数据体。
命令:
curl \'localhost:9200/cities/city/_search\' -d \'
{
"query" : { "match" : { "desc" : "北漂" }}
}\'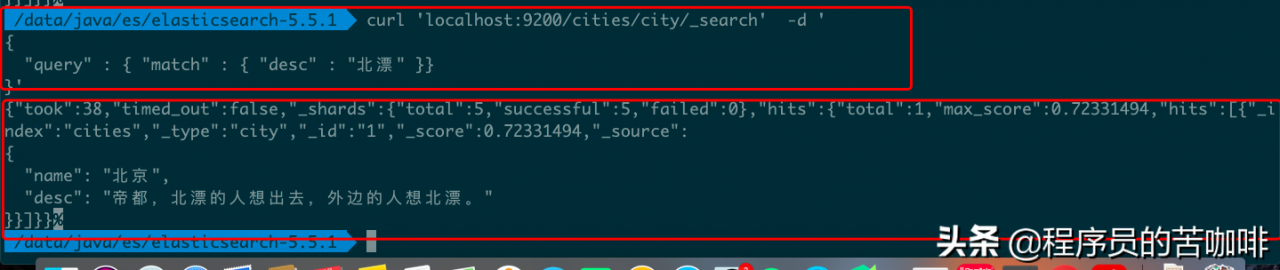
上面是查询语法,下面是查询结果。
8、逻辑运算
如果有多个搜索关键字, Elastic 认为它们是or关系。
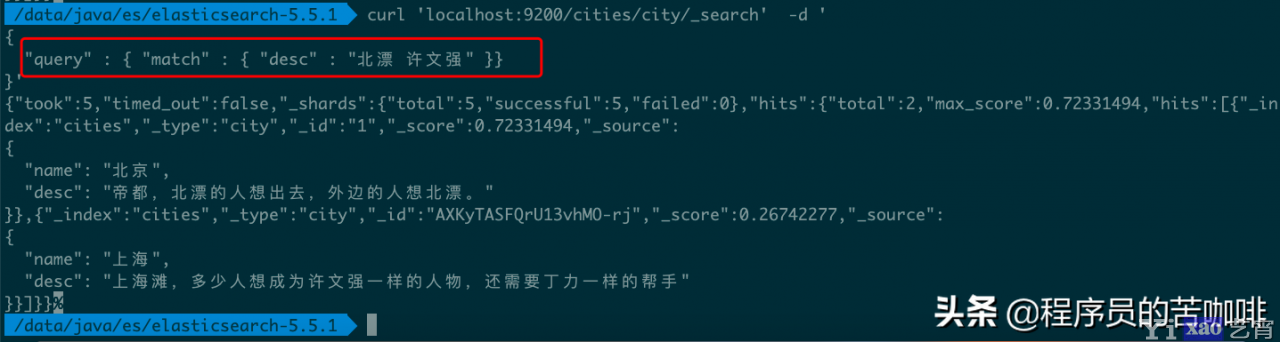
命令:
curl \'localhost:9200/cities/city/_search\' -d \'
{
"query" : { "match" : { "desc" : "北漂 许文强" }}
}\'
如果要执行多个关键词的and搜索,必须使用布尔查询。
命令:
curl \'localhost:9200/cities/city/_search\' -d \'
{
"query": {
"bool": {
"must": [
{ "match": { "desc": "北漂" } },
{ "match": { "desc": "许文强" } }
]
}
}
}\'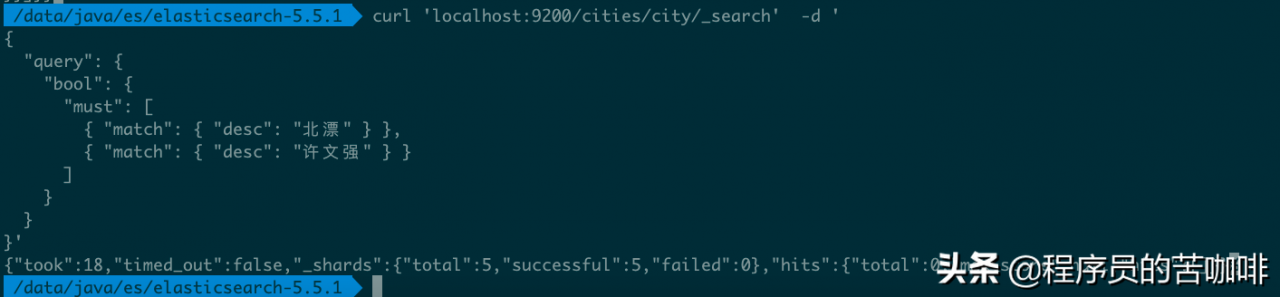
没有结果返回。
elasticsearch在日常开发中用途很多,感兴趣可以动手试一试,了解一下它都有什么功能。

内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/14380.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
主流短视频SDK调研对比报告
此报告为19年年中做的,偶尔翻出来了也不知道有没有参考价值,大家觉得有参考价值就给个赞,不喜也勿喷哈!!! (整理此报告的背景还是要吐槽的,在面试一家公司的时候,老板提出来的需要做…
-
今日头条集卡分2亿,如何集2021稀缺卡?
按照规则,前1000名集齐五张福卡即可获得2021元大红包,目前只有90人集齐。在今日头条“团圆家乡年”集卡活动中,“2021卡”是稀有卡,是最难获得的,那么今日头条2021卡怎么…
-
Google正式向用户推送Fuchsia OS
Google 开始向第一代 Google Nest Hub 推送 Fuchsia OS 2016 年,有媒体报道了 GitHub 上的一个神秘源码,显示 Google 正在开发一个…
-
神马搜索引擎大力发展 位居中国移动搜索第二位置
这是互联网的时代,互联网发展离不开搜索引擎。我国的搜索行业在政府的大力监管下,发展的越来越规范化,在过去的一年,搜索引擎进一步推进,而且开始和人工智能技术相结合。以前是百度搜索引擎…
-
网易云音乐的消息队列改造之路
背景 网易云音乐从 13 年 4 月上线以来,业务和用户突飞猛进。后台技术也从传统的 Tomcat 集群到分布式微服务快速演进和迭代,在业务的不断催生下,诞生了云音乐的 RPC,A…
-
如何绕过百度网盘客户端直接下载文件
每次到百度网盘下载文件,不管大小文件,一看到提示需要客户端,我就烦躁。百度网盘客户端下载速度慢的跟龟似的(估计龟都比它快)。之前也有用过破解下载速度、无限试用加速、修改成wap模拟…
-
搭建Vue开发环境教程
前言 由于是工具,很可能你看到的时候有些工具包已经升级了,会有一些报错;这个你就需要自己探索了。 工具的版本 node: v10.16.0 npm: v6.9.0 babel: 7…
-
.NET使用Minimal API介绍
Intro .NET 6 Preview 4 开始引入了 Minimal API 到如今的 RC1,Minimal API 也完善了许多并且修复了很多BUG,之前也写过文章介绍,可…
-
常见Web安全攻防总结
Web 安全地对于 Web 从业人员来说是一个非常重要的课题,所以在这里总结一下 Web 相关的安全攻防知识,希望以后不要再踩雷,也希望对看到这篇文章的同学有所帮助。今天这边文章主…
-
jupyter lab3.0客观使用体验
1 简介 jupyter lab于近期发布了其具有里程碑意义的3.0版本,随之带来的一些重要新特性,想必广大读者朋友已在各大公众号所翻译转载的jupyter lab团队官方介绍文章…