2018 年国庆节期间 ElasticSearch 母公司上市,那个时候我就想写一个 es 教程,可惜后来烂尾了,这事在我心里老是一个疙瘩。最近刚好有一个时间空档,就想着能不能把这个系列给完结了。
不同于之前的教程,这次的教程我打算出一个视频版 图文混合版的。视频为主,图文为辅。视频我会上传到百度网盘,文末会有文章对应的视频下载链接。
ElasticSearch 目前也算是非常火了,站内搜索、日志分析都会用到它,而且还可以直接当成 NoSQL 数据库来使用。
接下来,我们就通过下面这个简单介绍,开启 es 之旅吧~
松哥针对本文内容录制了一个视频,如下:

视频下载链接:https://pan.baidu.com/s/1bIvtBv9OvTEXJUyZRtajgQ 提取码: pm94
1.Lucene
Lucene 是一个开源、免费、高性能、纯 Java 编写的全文检索引擎,可以算作是开源领域最好的全文检索工具包。
在实际开发中,Lucene 几乎适用于任何需要全文检索的场景,所以 Lucene 先后发展出好多语言版本,例如 C 、C#、Python 等。
早在 2005 年,Lucene 就升级为 Apache 顶级开源项目。它的作者是 Doug Cutting,有的人可能没听过这这个人,不过你肯定听过他的另一个大名鼎鼎的作品 Hadoop。
不过需要注意的是,Lucene 只是一个工具包,并非一个完整的搜索引擎,开发者可以基于 Lucene 来开发完整的搜索引擎。比较著名的有 Solr、ElasticSearch,不过在分布式和大数据环境下,ElasticSearch 更胜一筹。
Lucene 主要有如下特点:
- 简单
- 跨语言
- 强大的搜索引擎
- 索引速度快
- 索引文件兼容不同平台
2.ElasticSearch
ElasticSearch 是一个分布式、可扩展、近实时性的高性能搜索与数据分析引擎。ElasticSearch 基于 Java 编写,通过进一步封装 Lucene,将搜索的复杂性屏蔽起来,开发者只需要一套简单的 RESTful API 就可以操作全文检索。
ElasticSearch 在分布式环境下表现优异,这也是它比较受欢迎的原因之一。它支持 PB 级别的结构化或非结构化海量数据处理
整体上来说,ElasticSearch 有三大功能:
- 数据搜集
- 数据分析
- 数据存储
ElasticSearch 的主要特点:
- 分布式文件存储。
- 实时分析的分布式搜索引擎。
- 高可拓展性。
- 可插拔的插件支持。
3.安装
3.1 单节点安装
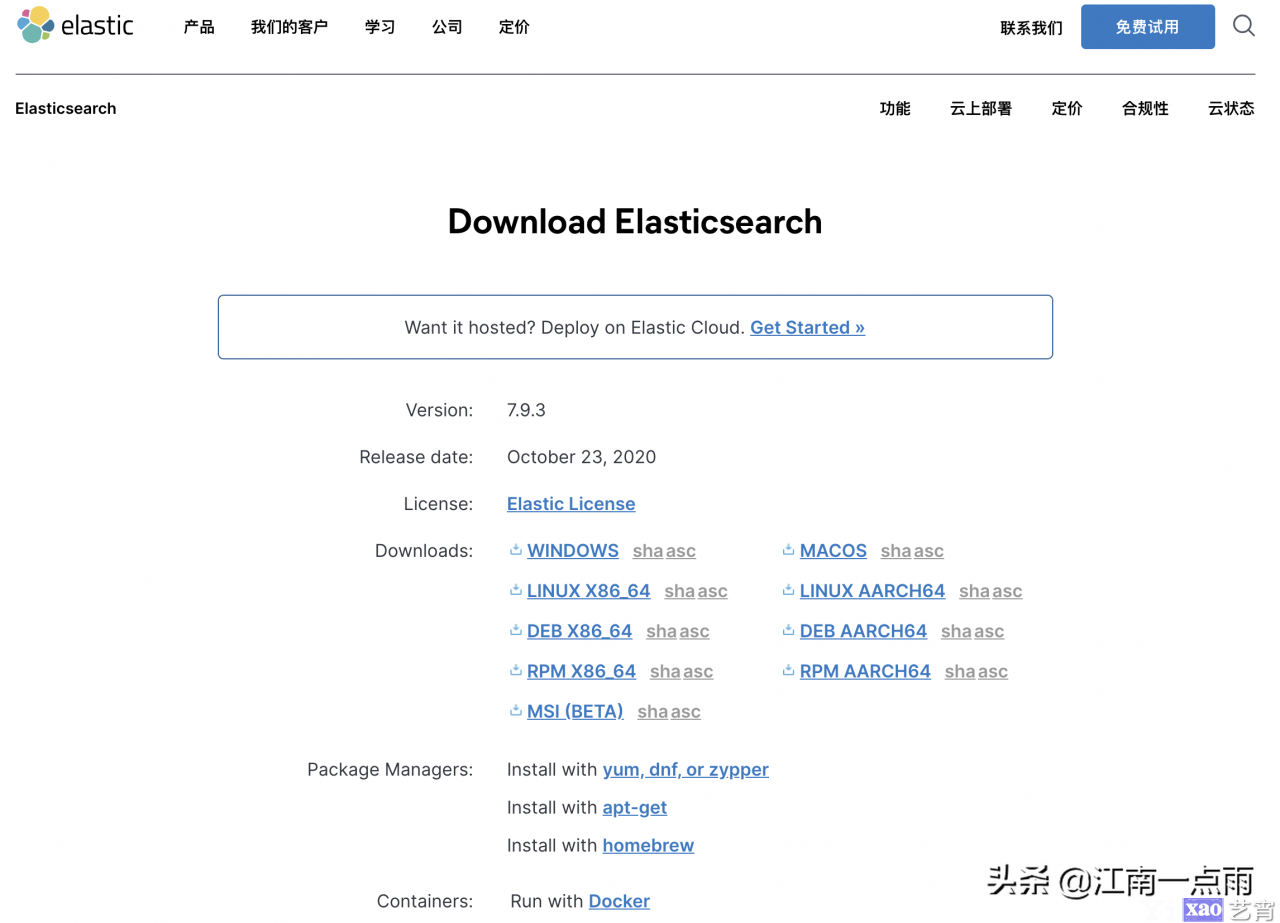
首先打开 Es 官网,找到 Elasticsearch:
- https://www.elastic.co/cn/elasticsearch/
然后点击下载按钮,选择合适的版本直接下载即可。
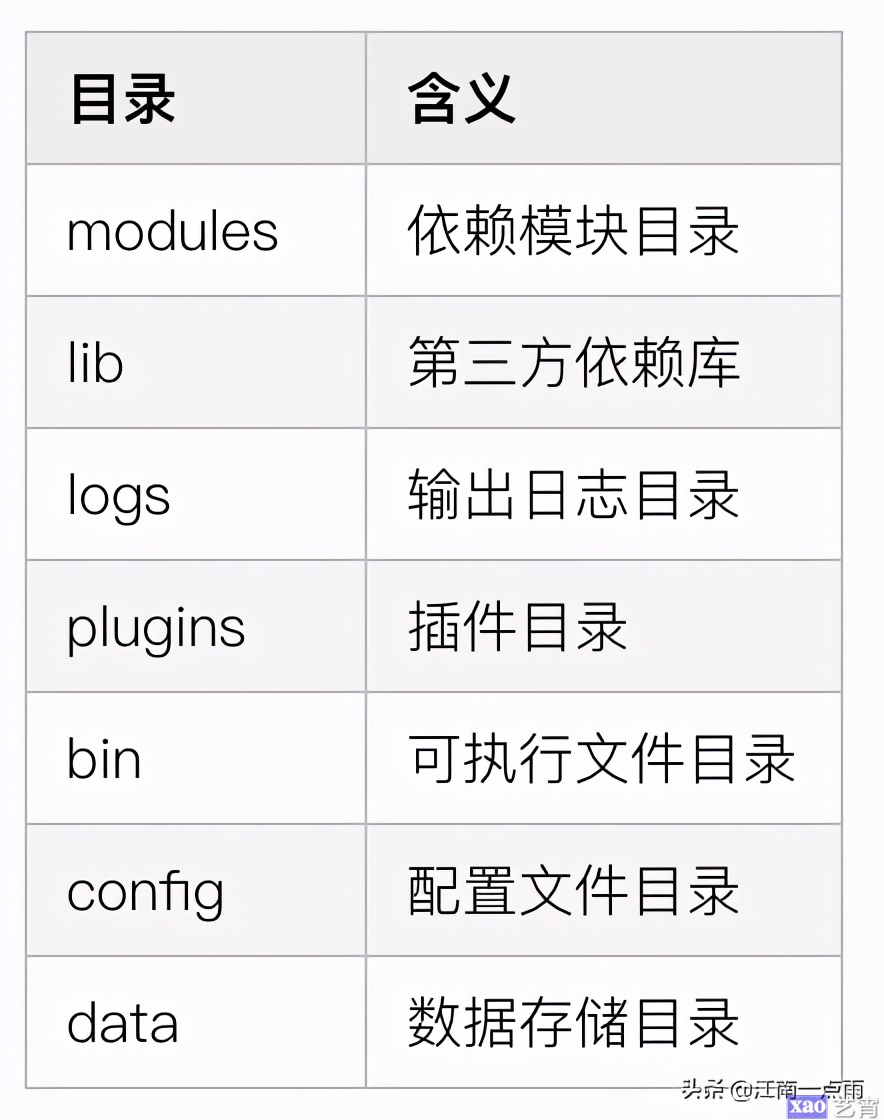
将下载的文件解压,解压后的目录含义如下:
启动方式:
进入到 bin 目录下,直接执行 ./elasticsearch 启动即可。

看到 started 表示启动成功。
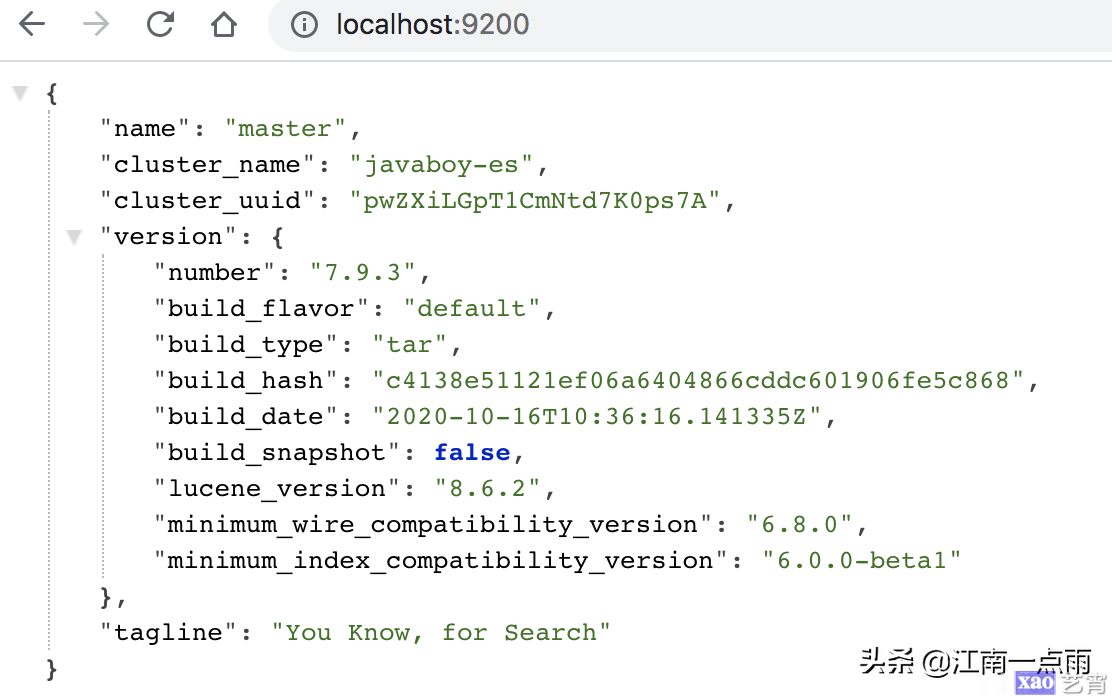
默认监听的端口是 9200,所以浏览器直接输入 localhost:9200 可以查看节点信息。
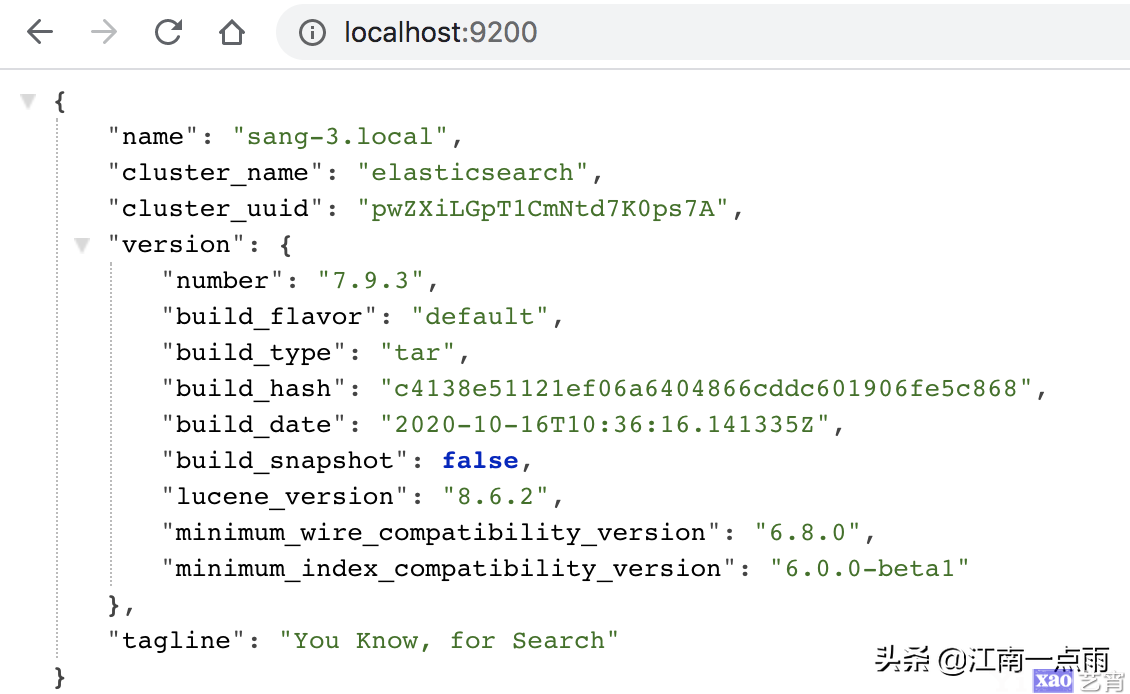
节点的名字以及集群(默认是 elasticsearch)的名字,我们都可以自定义配置。
打开 config/elasticsearch.yml 文件,可以配置集群名称以及节点名称。配置方式如下:
cluster.name: javaboy-es
node.name: master
配置完成后,保存配置文件,并重启 es。重启成功后,刷新浏览器 localhost:9200 页面,就可以看到最新信息。
Es 支持矩阵:
- https://www.elastic.co/cn/support/matrix
3.2 HEAD 插件安装
Elasticsearch-head 插件,可以通过可视化的方式查看集群信息。
这里介绍两种安装思路。
3.2.1 浏览器插件安装
Chrome 直接在 App Store 搜索 Elasticsearch-head,点击安装即可。
公众号江南一点雨后台回复 Elasticsearch-head,可以下载离线安装包。
3.2.2 下载插件安装
四个步骤
- git clone git://github.com/mobz/elasticsearch-head.git
- cd elasticsearch-head
- npm install
- npm run start
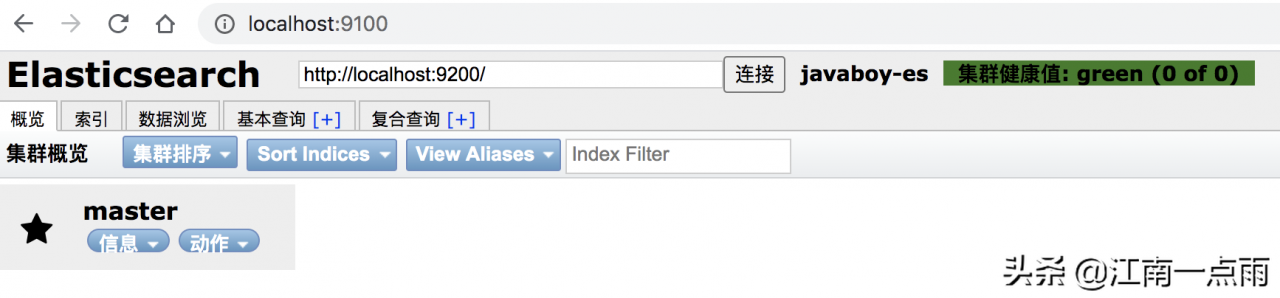
启动成功,页面如下:

注意,此时看不到集群数据。原因在于这里通过跨域的方式请求集群数据的,默认情况下,集群不支持跨域,所以这里就看不到集群数据。
解决办法如下,修改 es 的 config/elasticsearch.yml 配置文件,添加如下内容,使之支持跨域:
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后,重启 es,此时 head 上就有数据了。
3.3 分布式安装
假设:
- 一主二从
- master 的端口是 9200,slave 端口分别是 9201 和 9202
首先修改 master 的 config/elasticsearch.yml 配置文件:
node.master: true
network.host: 127.0.0.1
配置完成后,重启 master。
将 es 的压缩包解压两份,分别命名为 slave01 和 slave02,代表两个从机。
分别对其进行配置。
slave01/config/elasticsearch.yml:
# 集群名称必须保持一致
cluster.name: javaboy-es
node.name: slave01
network.host: 127.0.0.1
http.port: 9201
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
slave02/config/elasticsearch.yml:
# 集群名称必须保持一致
cluster.name: javaboy-es
node.name: slave02
network.host: 127.0.0.1
http.port: 9202
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
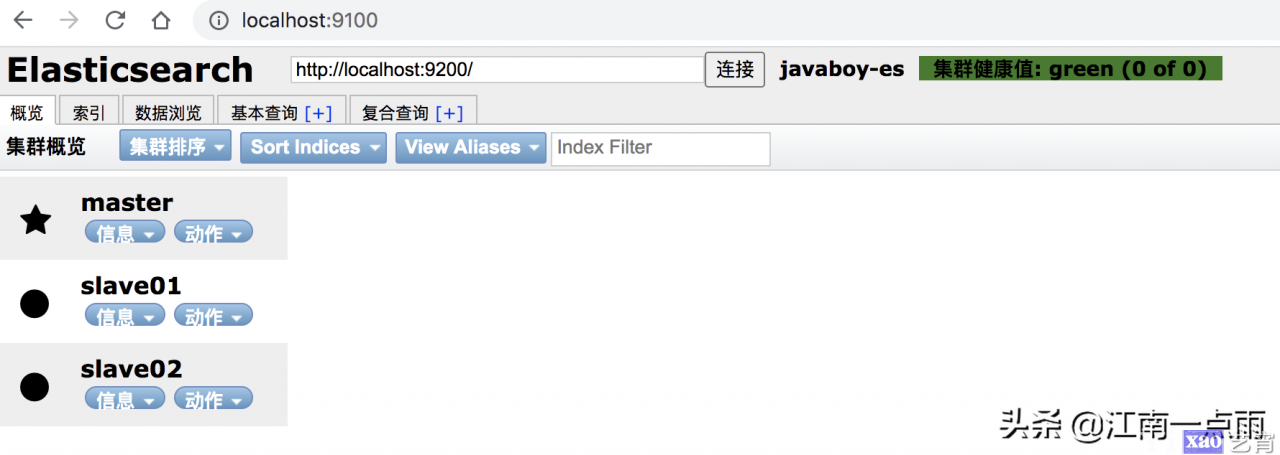
然后分别启动 slave01 和 slave02。启动后,可以在 head 插件上查看集群信息。
3.4 Kibana 安装
Kibana 是一个 Elastic 公司推出的一个针对 es 的分析以及数据可视化平台,可以搜索、查看存放在 es 中的数据。
安装步骤如下:
- 下载 Kibana:https://www.elastic.co/cn/downloads/kibana
- 解压
- 配置 es 的地址信息(可选,如果 es 是默认地址以及端口,可以不用配置,具体的配置文件是 config/kibana.yml)
- 执行 ./bin/kibana 文件启动
- localhost:5601
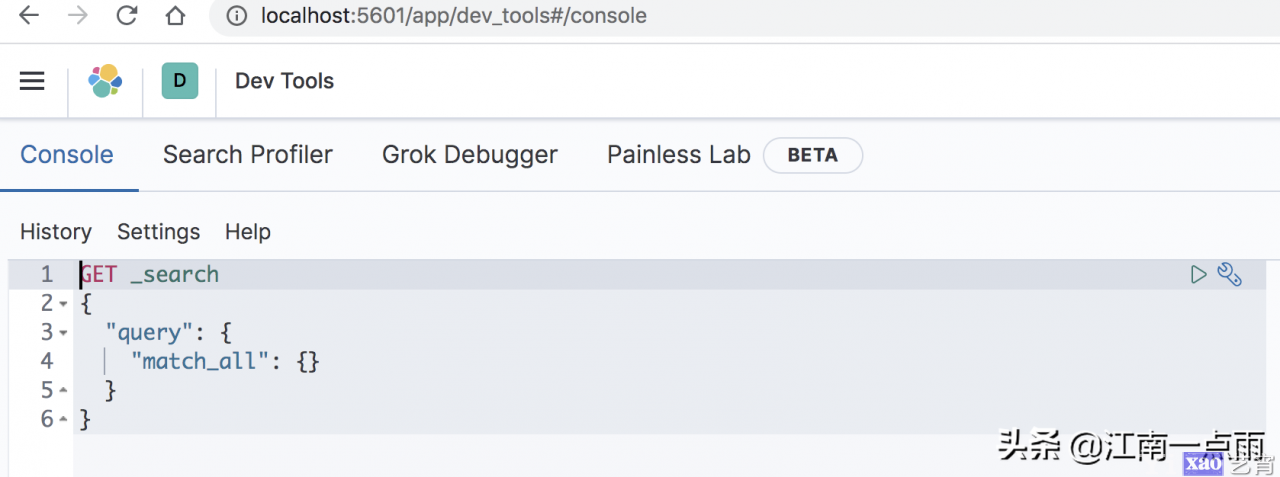
Kibana 安装好之后,首次打开时,可以选择初始化 es 提供的测试数据,也可以不使用。
4.ElasticSearch 核心概念介绍
4.1 ElasticSearch 十大核心概念
4.1.1 集群(Cluster)
一个或者多个安装了 es 节点的服务器组织在一起,就是集群,这些节点共同持有数据,共同提供搜索服务。
一个集群有一个名字,这个名字是集群的唯一标识,该名字成为 cluster name,默认的集群名称是 elasticsearch,具有相同名称的节点才会组成一个集群。
可以在 config/elasticsearch.yml 文件中配置集群名称:
cluster.name: javaboy-es
在集群中,节点的状态有三种:绿色、黄色、红色:
- 绿色:节点运行状态为健康状态。所有的主分片、副本分片都可以正常工作。
- 黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行,但是至少有一个副本分片是不能正常工作的。
- 红色:表示集群无法正常工作。
4.1.2 节点(Node)
集群中的一个服务器就是一个节点,节点中会存储数据,同时参与集群的索引以及搜索功能。一个节点想要加入一个集群,只需要配置一下集群名称即可。默认情况下,如果我们启动了多个节点,多个节点还能够互相发现彼此,那么它们会自动组成一个集群,这是 es 默认提供的,但是这种方式并不可靠,有可能会发生脑裂现象。所以在实际使用中,建议一定手动配置一下集群信息。
4.1.3 索引(Index)
索引可以从两方面来理解:
名词
具有相似特征文档的集合。
动词
索引数据以及对数据进行索引操作。
4.1.4 类型(Type)
类型是索引上的逻辑分类或者分区。在 es6 之前,一个索引中可以有多个类型,从 es7 开始,一个索引中,只能有一个类型。在 es6.x 中,依然保持了兼容,依然支持单 index 多个 type 结构,但是已经不建议这么使用。
4.1.5 文档(Document)
一个可以被索引的数据单元。例如一个用户的文档、一个产品的文档等等。文档都是 JSON 格式的。
4.1.6 分片(Shards)
索引都是存储在节点上的,但是受限于节点的空间大小以及数据处理能力,单个节点的处理效果可能不理想,此时我们可以对索引进行分片。当我们创建一个索引的时候,就需要指定分片的数量。每个分片本身也是一个功能完善并且独立的索引。
默认情况下,一个索引会自动创建 1 个分片,并且为每一个分片创建一个副本。
4.1.7 副本(Replicas)
副本也就是备份,是对主分片的一个备份。
4.1.8 Settings
集群中对索引的定义信息,例如索引的分片数、副本数等等。
4.1.9 Mapping
Mapping 保存了定义索引字段的存储类型、分词方式、是否存储等信息。
4.1.10 Analyzer
字段分词方式的定义。
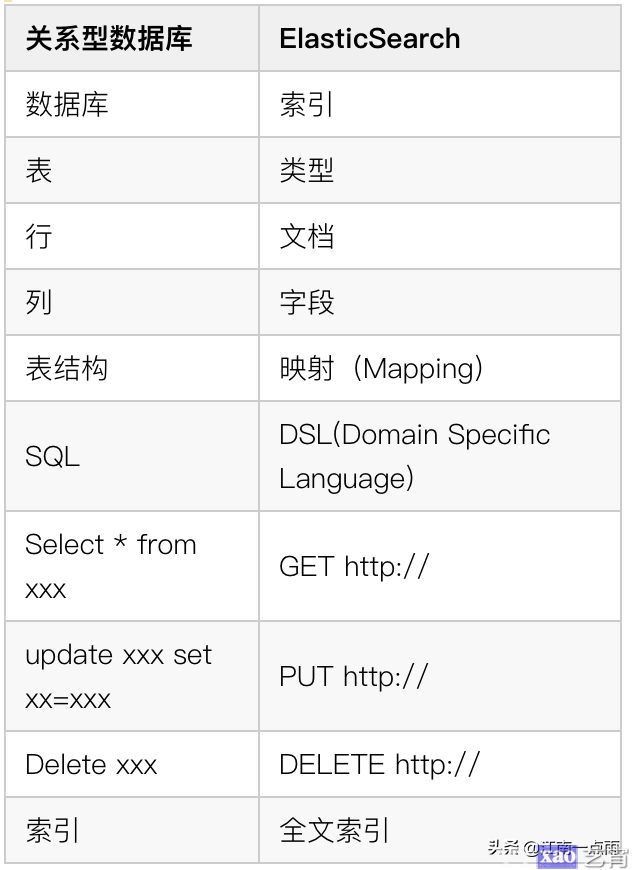
4.2 ElasticSearch Vs 关系型数据库
这篇文章其实是松哥所录制的 Es 视频教程的笔记,笔记相对简陋一些,小伙伴们也可以参考视频,视频下载链接:https://pan.baidu.com/s/1bIvtBv9OvTEXJUyZRtajgQ 提取码: pm94
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/15612.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
基于Ubuntu 20.04 LTS 代号Uma的Linux Mint 20.2正式发布
基于 Ubuntu 20.04 LTS 版本,代号为 Uma 的 Linux Mnit 20.2 于今天正式发布。目前官方提供了 Cinnamon、MATE 和 Xfce 三种桌面…
-
Webflow与WordPress:谁才是网站建设中的王者
当企业家考虑创建新网站时,会立即弹出一个选择:WordPress,全球排名第一的CMS。38.4%的网站都在使用WordPress,它的重要性毋庸置疑,WordPress之于内容管…
-
mysql数据库写入数据提示1366代码错误解决方法
错误代码: 1366 Incorrect string value: ‘xE5xBCxA0xE4xB8x89…’ for column `stu…
-
新版Microsoft Edge浏览器功能详解 高效使用谷歌扩展
亲测良心推荐之浏览器详细解读篇 Microsoft Edge如何高质量使用 一般用户只需要安装这一款浏览器,就基本可以保证生活和工作的高效和愉快体验。名字虽然很熟悉,不过好的工具,…
-
Windows Terminal Preview 1.8 已发布
Windows Terminal Preview 1.8 已发布,按照其发布计划,只要新版本进入 Preview 阶段,上一个版本的所有预览功能就会进入稳定阶段,因此 Window…
-
如何搭建属于你的专业Python大数据分析环境
什么是数据科学 数据科学通常被描述为统计和编程的交集。在本文中,我们讲介绍如何在你的电脑上设置立专业数据科学环境,这样你就可以开始动手实践与流行的数据科学库! 什么是专业的数据科学…
-
网页设计中不可缺少的尺寸知识
网页设计在初始要界定出网页的尺寸大小.就像绘画给出一块画版来.这样才能方便设计. 网页的尺寸受限于两个因素:一个是显示器屏幕.显示器现在种类很多,以17寸为主流, 正在朝19寸及宽屏的方向发展.但目前也有为数不少的15寸显示器.另一个是浏览器软件,就是我们常用的IE,遨游,Friefox等. 高度: 高度是可以向下延展的,所以一般对高度不限制. 对于一屏来说,一般没有一个固定值。
-
工信部组织下架90款APP:天涯社区、大麦、途牛旅游、脉脉等在列
工业和信息化部信息通信管理局发布《关于下架侵害用户权益APP名单的通报》(文末附件为下架名单)对天涯社区、大麦等90款APP进行下架处理,所涉及的问题大多为“违规收集个人信息”“A…
-
Restful API设计规范
RESTFUL是一种网络应用程序的设计风格和开发方式,基于HTTP,可以使用XML格式定义或JSON格式定义。RESTFUL适用于移动互联网厂商作为业务使能接口的场景,实现第三方O…
-
HTTP和HTTPS的区别简述
HTTP是超文本传输协议,是一个基于请求与响应、无状态的、应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。 H…