简介: 近年来,随着数据实时化的诉求加剧,催生了一系列的实时数仓架构,Lambda架构也应运而生,但是随着场景的复杂度和业务多维需求,Lambda架构的痛点也越来越明显。HSAP的理念则是服务分析一体化,在本文中,来自阿里巴巴的资深技术专家将会深度剖析HSAP技术实现Hologres的设计原理,解读其产品典型场景。
一、传统数据仓库
目前来说,大数据相关的业务场景一般有实时大屏、实时BI报表、用户画像和监控预警等,如下图所示。
- 实时大屏业务,一般用在公司领导做决策的辅助工具,在对外展示,比如实时成交额等场景也会经常用到,是一种展示公司实力的方式。
- 实时BI报表是运营和产品经理经常用到的一个业务。
- 用户画像常用在广告推荐场景中,通过更详细的算法给用户贴上标签,使得推荐算法更加有针对性,更加有效。
- 预警监控,比如对网站、APP进行流量监控,在达到一定阈值的时候可以进行报警。

对于上面这些大数据业务场景,在很早之前业界就开始通过数据仓库的建设来满足这些场景的需求,比较传统的是如下图所示的离线数据仓库,其大致流程就是:首先,将各类数据收集起来;然后经过ETL处理,再经过层层建模对数据进行聚合、筛选等处理;最后在需要的时候通过应用层的工具对数据进行展现,或者生成报表。
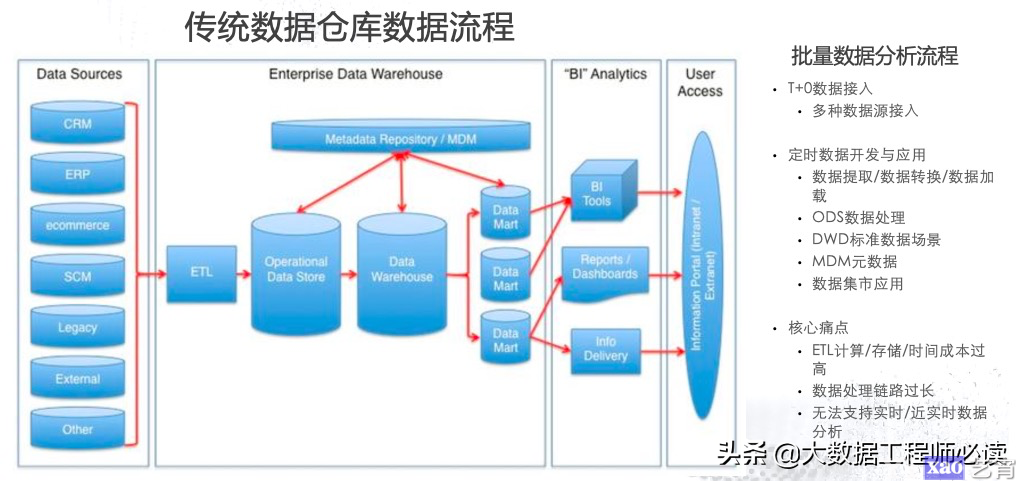
上面这种方式虽然可以对接多种数据源,但是存在一些很明显的痛点:
- ETL逻辑复杂,存储、时间成本过高;
- 数据处理链路非常长;
- 无法支持实时/近实时的数据,只能处理T 1的数据。
二、Lambda架构
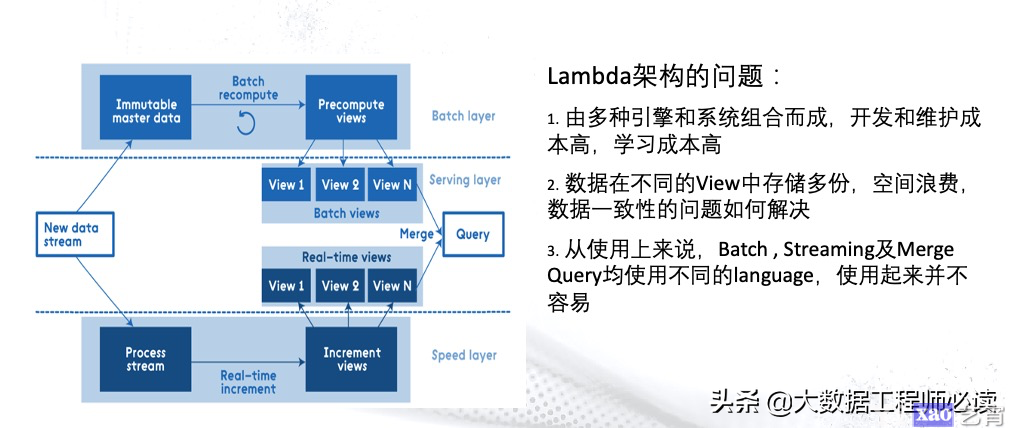
随着实时计算技术的兴起,出现了Lambda架构。Lambda架构的原理如下图所示,其思路其实是相当于在传统离线数仓的基础上再加上一个处理实时数据的层,然后将离线数仓和实时链路产生的数据在Serving层进行Merge,以此来对离线产生的数据和实时产生的数据进行查询。
从2011年至今,Lambda架构被多数互联网公司所采纳,也确实解决了一些问题,但是随着数据量的增大、应用复杂度的提升,其问题也逐渐凸显,主要有:
- 由多种引擎和系统组合而成,开发和维护成本高,学习成本高;
- 数据在不同的View中存储多份,空间浪费,数据一致性的问题难以解决;
- 从使用上来说,Batch,Streaming以及Merge Query等处理过程中均使用不同的language,使用起来并不容易;
- 学习成本非常高,增大了应用成本。
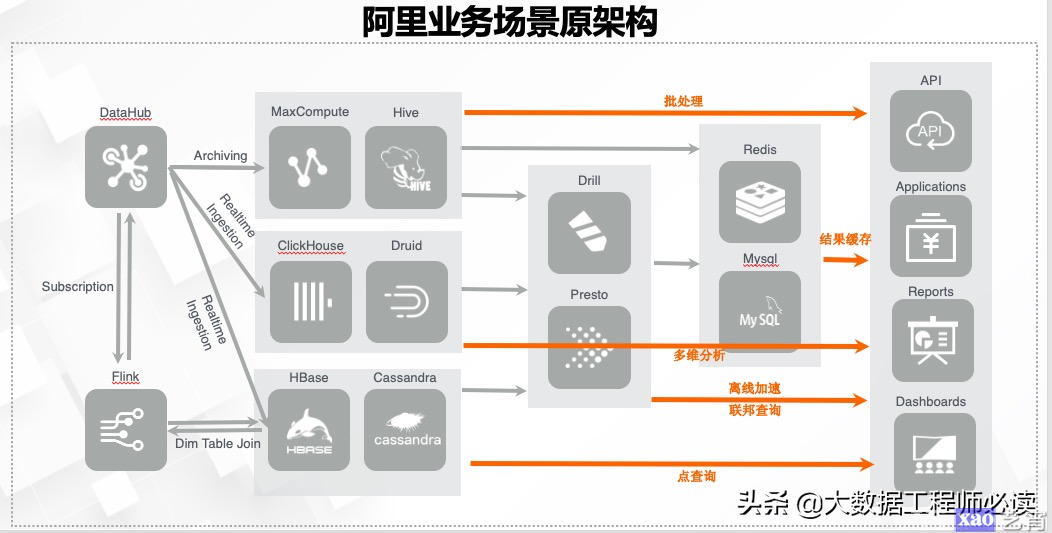
下图是阿里巴巴在2011年到2016年间沉淀下来的一套实时数仓架构,其本质上也是Lambda架构,然而随着业务量的增长,随着数据的增长,关系复杂度越来越大,成本急剧增加,上面讲到的问题,在阿里内部也都遇到了,因此,我们迫切的需要一种更优雅的方案去解决类似的问题。
三、HSAP:分析、服务一体化
基于上述背景,我们提出了HSAP解决方案,HSAP是指Hybrid serving and analytical processing,我们的理念是能够支持这种很高QPS的Serverless场景的查询写入,并且将复杂的分析场景在一套体系里面完成。 那么其核心是什么呢?首先,要有一套非常强大的存储,能够把实时的数据和离线的数据存储进来,实现数据的通存,同时还要有一种高效的查询服务,能够支持高QPS的查询,支持复杂的分析以及联邦查询和分析,这样的话就可以把离线数据和实时数据都导入到系统里去,然后将前端的数据应用,比如BI报表和一些在线服务,对接到系统中去。如此,上面提到的架构复杂的问题,其实就可以迎刃而解。我们把这样的设计理念叫做HSAP设计理念。

四、Hologres简介
有了上面HSAP的设计理念,我们要去做相应的产品来实现这种理念,于是有了Hologres。Hologres这个词是holographic和Postgres的组合,Postgres指的是兼容PostgreSQL生态,holographic指的是全息,也就是全部信息,我们希望通过Hologres对数据进行全息的分析,并且能够兼容PostgreSQL生态。
用一句话来总结,Hologres就是基于HSAP理念,兼容PostgreSQL生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时数据仓库,其架构图如下所示。
整体来看,其架构非常简单,是存储计算分离的架构,数据全部存在一个分布式文件系统里面,在阿里内部指的是盘古分布式文件系统;服务节点叫做Backend,真正去接收数据,存储和查询,并且能够支持数据的计算;Frontend接收路由分发过来的SQL,然后生成真正的物理执行计划,发布到Backend做分布式的执行;在接入端由LBS来做相应的负载均衡任务。下图中黄色部分均部署在容器中,整个分布式系统可以做到高度容错。同时,因为兼容PostgreSQL生态,所以一些开源或者商业化的BI工具,或者WebIDE可以直接跟Hologres进行对接。
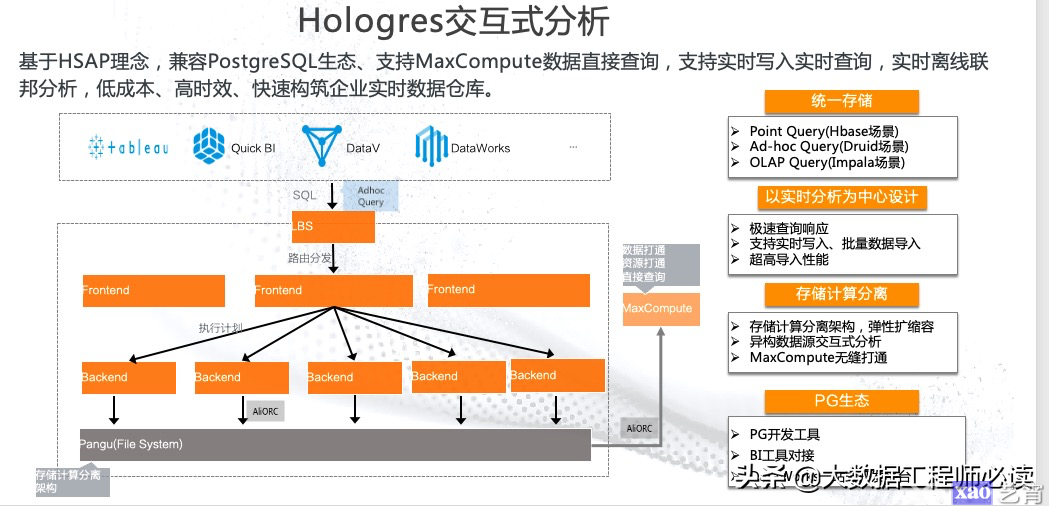
Hologres有着强大的性能,主要包括:
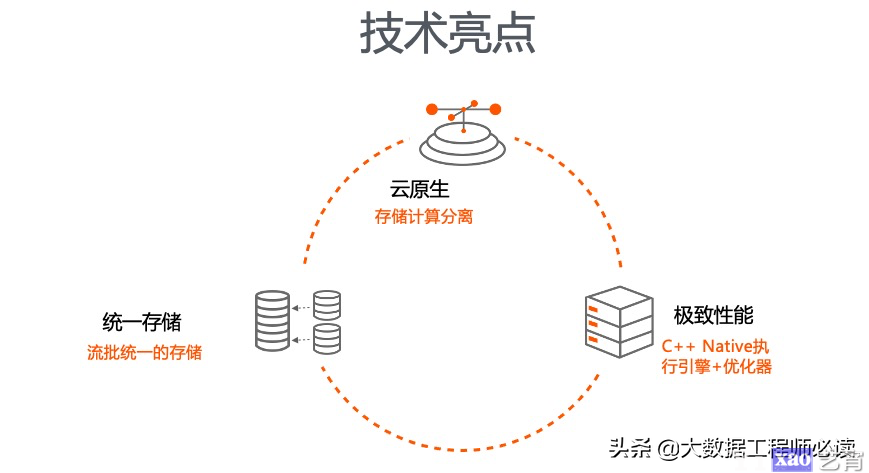
1)统一存储
Hologres能够满足多种场景中的数据存储方式,支持Point Query(Hbase场景)、Ad-hoc Query(Durid场景)和OLAP Query(Impala场景)等。
2)以实时分析为中心设计
Hologres的设计理念就是为了快,支持压秒级的数据实时分析,极速查询响应,还支持实时写入、批量数据导入,拥有超高导入性能。
3)存储计算分离
Hologres采用存储计算分离架构,用户可以根据需求进行弹性扩缩容,如果存储用的比较多可以多买存储,CPU用的比较多可以多买CPU。另外,Hologres支持异构数据源交互分析以及离线数据和实时数据的联邦查询。Hologres已经和MaxCompute无缝打通,能够直接在Hologres中对MaxCompute表进行查询。
4)PG生态
Hologres兼容PostgreSQL生态,能够与PG开发工具、BI工具进行对接,同时在阿里云提供了一套原生的开发平台,能够在WebIDE中进行SQL的开发,并且支持任务的调度。
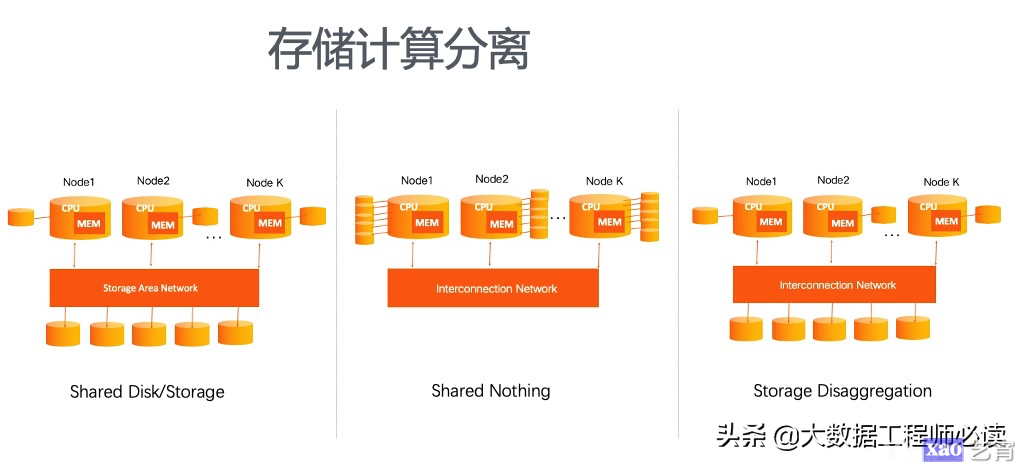
(一)存储计算分离
在传统的分布式系统,尤其是分布式存储中,常用的架构有如下三种。
其中Shared Disk/Storage就是在存储集群上挂载了很多盘,每个计算节点都可以访问这些盘;
Shared Nothing架构就是每个计算节点自己挂载存储,节点之间可以通信,但是各个节点之间的盘不共享,存在资源浪费的情况;
Storage Disaggregation就是相当于把存储集群看做一个大的磁盘,每个计算节点都可以访问,且每个计算节点都有一定的缓存空间,可以对缓存数据进行访问,也无需关心存储集群的管理,这种存储计算分离的架构便于灵活扩容,能够有效节省资源,Hologres就是采用的这种架构。
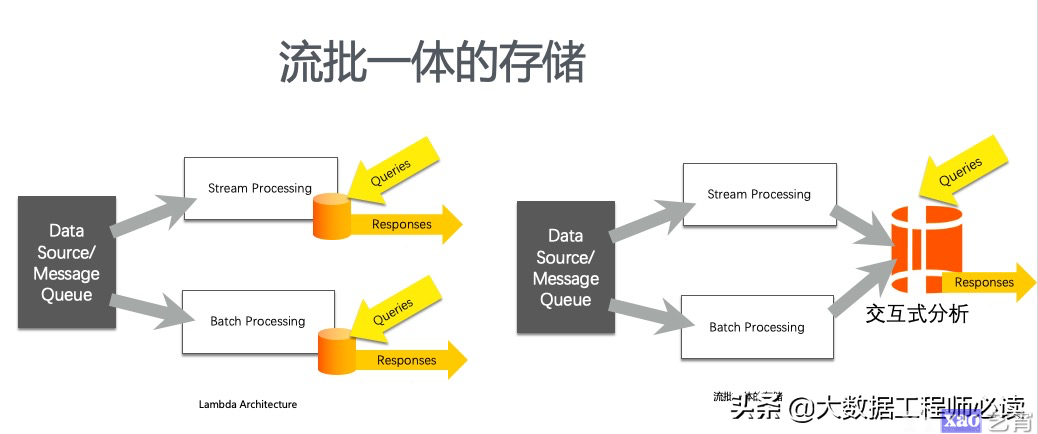
(二)流批统一的存储
Hologres定位是能够做离线数据和实时数据的存储。对于典型的Lambda架构,是将实时数据通过实时数据的链路写入到实时数据存储中,离线数据通过离线数据的链路写入到离线存储中,然后将不同的Query放到不同的存储中,再做一个Merge。对于Hologres,如下图所示,数据收集之后可以走不同的处理链路,但是处理完成之后的结果都可以写入Hologres中,这样就解决了数据的一致性问题,也不需要去区分离线表和实时表,降低了复杂度,也大大降低了使用者的学习成本。
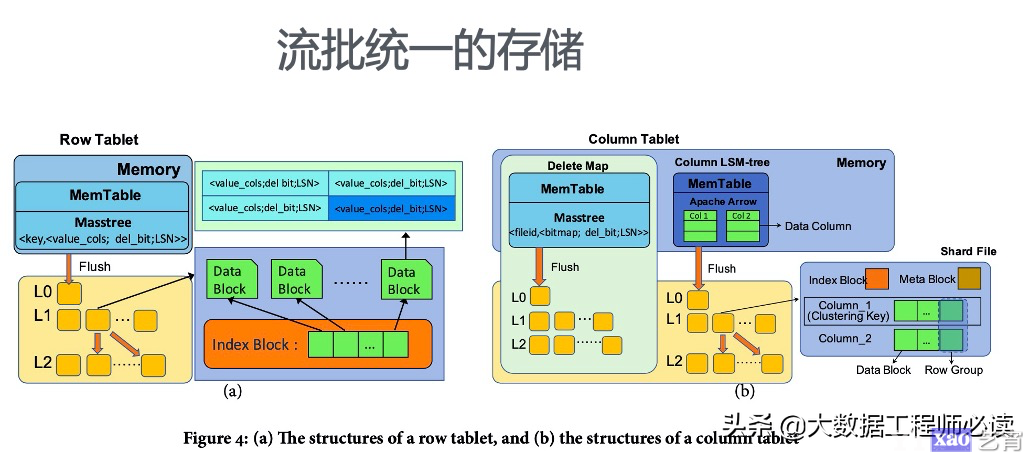
Hologres底层支持行存储和列存储两种文件格式,对于两者的处理也有略微不同,具体如下图所示。数据写入的时候先写log,log是存储在分布式文件系统中的,保证整个服务的数据不会丢失,因为即便服务器挂掉也可以从分布式系统中恢复。Log写完之后再写MemTable,就是内存表,这样子才认为是数据写入成功。MemTable有一定的大小,写满了之后会将其中的数据逐渐flush到文件中,文件是存储在分布式系统中的。而对于行存储和列存储的区别就在Flash到文件的这个过程中,这个过程会将行存表flush成行存储的文件,列存表会Flash成列存文件。在Flash的过程中会产生很多小文件,后台会将这些小文件合并成一个大文件,这里也会有所不同,大家可以自行查阅文档了解。
(三)极致查询性能
如果希望得到一个快速的系统,除了高性能的存储,更少不了高性能的查询。Hologres其自身有着极致的查询性能,主要包括:
- 同时支持行寸列存;
- 向量化等执行层优化;
- 高并发充分利用计算资源;
- 纯C 实现保证稳定的低延迟;
- 优化的调度保证SLA;
- 基于成本的优化器,针对存储特点高度优化。

总得来说,Hologres的技术亮点包括云原生、统一存储和极致性能,具体的细节大家可以参考http://www.vldb.org/pvldb/vol13/p3272-jiang.pdf。
五、Hologres典型应用场景
从Hologres的设计理念来看,其典型的应用场景主要有以下三类:
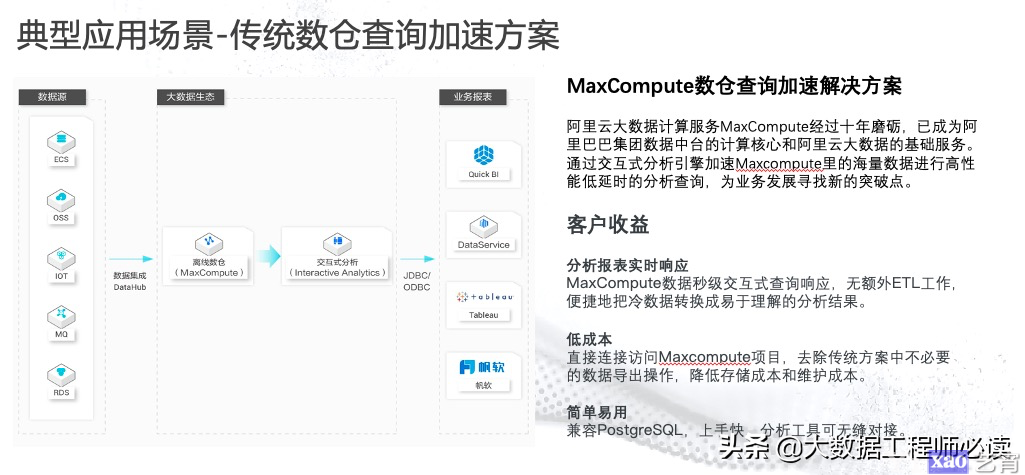
(一)离线数据查询加速场景
这种场景下,就是将以前在离线系统里面的数据和查询通过Hologres来进行加速,来达到量级提升的加速效果。通过Hologres,对离线数据秒级交互式查询响应,无需额外ETL工作,便捷地把冷数据转换成易于理解的分析结果,提升企业决策效率,降低时间成本。
(二)实时数仓场景
在下图所示场景中,实时数仓通过搭建用户洞察体系,实时监测平台用户情况,并从不同视角对用户进行实时诊断,进而采取针对性的用户运营策略,从而达到精细化用户运营目的, 助力实时精细化运营。这种场景下,离线数据和实时数据都可以写入到Hologres中,不需要再通过Lambda架构做多个系统中数据的Merge,减少异质性,降低学习成本。

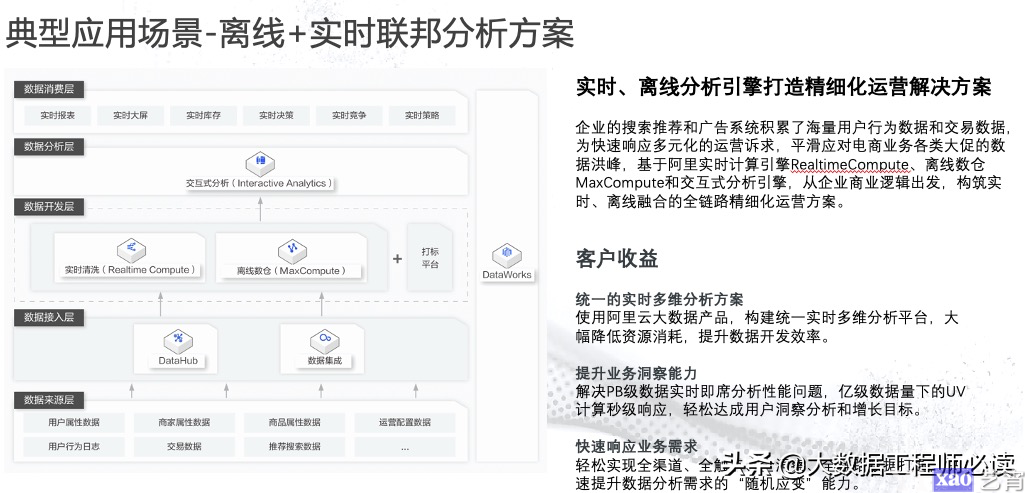
(三)实时离线联邦计算场景
如下图所示场景,基于实时计算引擎RealtimeCompute、离线数仓MaxCompute和交互式分析,从商业逻辑出发,实现离线数据分析实时化,实时离线联合分析, 构筑实时全链路精细化运营。
四、典型客户案例
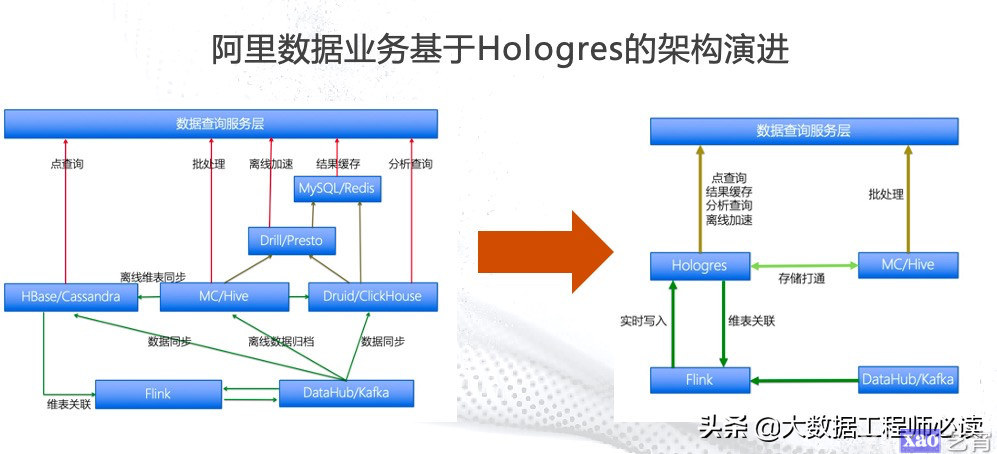
下图所示的是阿里数据业务基于Hologres的架构演进,从下图(左)可以看出,在没有Hologres之前,整个数据链路以及架构非常的复杂,比如图中所示的5条红线代表的5个链路;在有了Hologres之后,整个数据链路就变得清晰明了,数据进入系统之后通过Flink做实时的ETL,然后直接写入到Hologres中,之后可以通过Hologres进行归档、历史数据的加速等,数据服务也非常简单,点查询、分析查询等操作都可以通过Hologres来完成,整个链路就变的非常简单,大大降低了架构复杂度,降低了成本。
下面三张图展示的分别是Hologres在基于实时分析引擎搜索推荐实时分析和算法应用、基于实时分析引擎行业精细化运营、基于实时分析引擎构建安全风控系统实时分析场景中的应用。
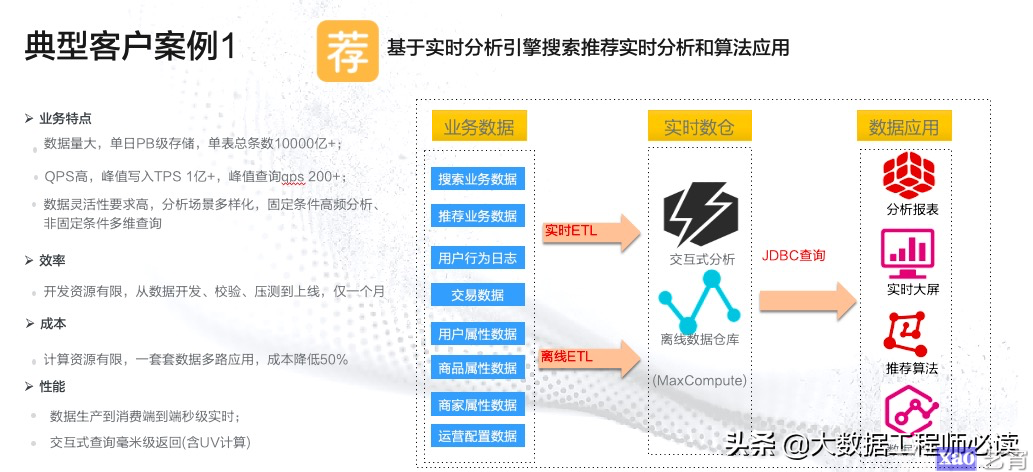
(1)基于实时分析引擎搜索推荐实时分析和算法应用
本案例是阿里巴巴的一个实时搜索推荐的场景,其特点是数据量相当大,单日数据达到了PB级别,且写入数据量也非常大,QPS也非常高。该场景对数据的灵活性要求非常高,分析场景多样化,在应用了Hologres之后,可以将原来众多的业务数据通过实时ETL导入Hologres中(离线数据通过离线ETL导入离线数仓再加载到Hologres中),然后再通过JDBC查询进行数据的应用,比如分析报表、实时大屏等。通过Hologres的引入,开发效率大大提升,且成本降低了一半,整个业务系统的性能也得到了很大的提升,数据生产到消费端到端秒级实时,交互式查询毫米级返回。
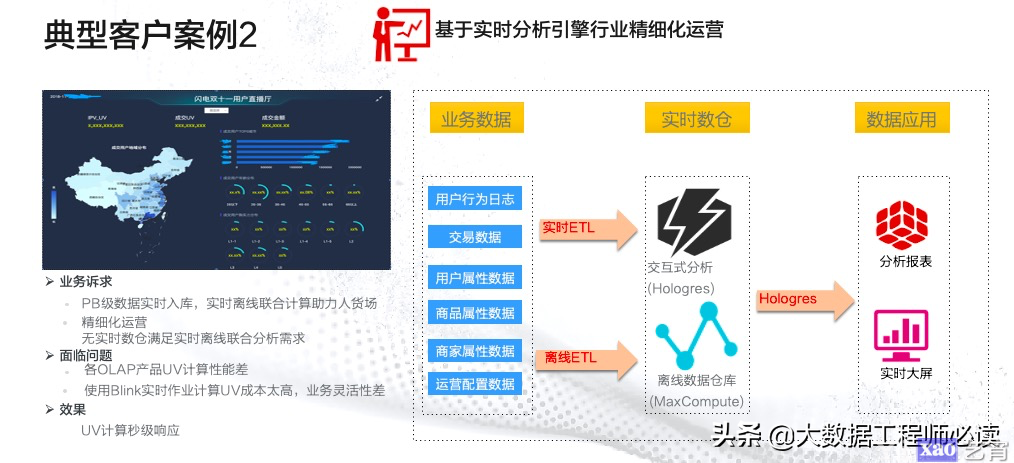
(2)基于实时分析引擎行业精细化运营
该案例针对的是行业精细化运营的场景,使用对象一般是运营小二或者商家。这种场景下,通过将业务数据数据通过ETL导入到Hologres中,然后去做多维的筛选,提供给用户分析报表或者进行实时大屏的展现,解决了之前各种OLAP产品UV计算性能差,使用Blink实时作业计算UV成本高、业务灵活性差等痛点,实现了UV计算的秒级响应。
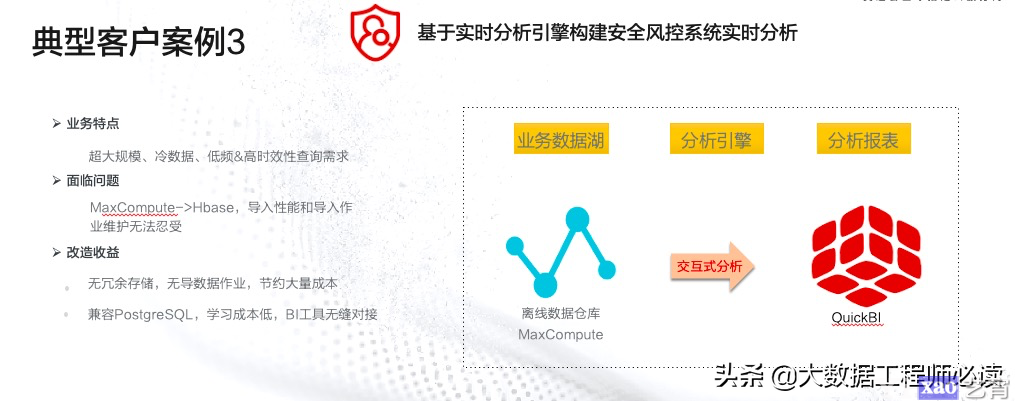
(3)基于实时分析引擎构建安全风控系统实时分析
本案例是一个风控场景,通过将实时、离线的数据写入到Hologres中,加速查询的过程,最终产生相应的分析报表或者实时预警的规则,通过Hologres的引入,节约了大量成本,大大降低了学习成本,且与BI工具可以无缝对接。
上面三个场景各有各的业务特点,也有各自的痛点问题,通过Hologres可以针对性的解决所面临的问题,达到降低成本,节约资源的效果。
目前,Hologres已经在阿里内部众多场景得到应用来解决面临的问题,并且Hologres也已经完成了商业化,欢迎大家使用,希望能够给云上的客户带来业务上的实质性帮助。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/16259.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
美团实时消息推送服务的技术演进之路
1、引言 传统意义上来说,实时消息推送通常都是IM即时通讯这类应用的技术范畴,随着移动端互联网的普及,人人拥有手机、随时都是“在线”已属常态,于是消息的实时触达能力获得了广泛的需求…
-
利用Spring的aop原理实现系统级日志管理
背景 日常开发中,我们常用的日志有两种,一种是业务日志,该类型主要用于记录系统中某些业务的变化或属性的改变,比如业务流转过程中记录状态的变化或对象属性的变化,此类型主要用于查询业务…
-
iTop3.0 Beta版本发布,界面有较大优化
上周著名开源的配置管理系统iTop发布了,一个新的大版本3.0 预览Beta,版本中虽然在底层架构上没有较大调整,但是在界面UI有较大变化,我们一起来学习下新版本的变化。 概述 本…
-
易语言E2EE互联网服务框架初识,中文编程也可以开发网站
可能有人对易语言这门全中文编程语言还有些偏见,认为编程语言都是用的英文,中文编程太low了等等。但是其实说白了,编程不就是把人类能看懂的语言转换成计算机能识别的二进制串吗,只要能实…
-
利用搜狐快站建设网站,草根站长的首选
对于搜狐快站,下面就进入今天的主题,给大家一步一步的讲解,菜鸟一看就会。 第一,注册搜狐快站到建站页面的几个步骤 1,打开搜狐快站官方网站,点击右上角的注册 2,填写资料上的邮箱,…
-
Spring Data JPA 与 MyBatis简单对比
Spring Data JPA是Spring Data的子模块。 1.使用Spring Data,使得基于“repositories”概念的JPA实现更简单和容易。 2.Sprin…
-
微信小程序开发视频教程!瞬间学会开发微信小程序!
腾讯小程序的正式发布以来,可谓是完全引爆了IT界,各行各界的小程序蜂拥而至,一天的时间里大量APP开发者在微信朋友圈“晒”出自家的小程序截图。短短不到24小时,甚至网络上出现了关于…
-
Windows10家庭中文版启用Hyper-V虚拟机
一直以为要将 Windows 10 家庭中文版 系统升级成 专业版 是为了 远程桌面 等功能,但 从未想过 大家竟然都是为了使用 Hyper-V 虚拟机。如果你仅需要使用它的话,大…
-
Vue之MVVM模型和MVC模型
MVC模式的业务逻辑主要集中在Controller,而前端的View其实已经具备了独立处理用户事件的能力,当每个事件都流经Controller时,这层会变得十分臃肿。
-
修复Windows10更新导致打印蓝屏问题的解决方案
3 月 9 日的补丁星期二活动日上,微软面向尚处于支持状态的 Windows 10 发布了累积更新。其中,Windows 10 20H1/20H2 功能更新获得 KB5000802…