市面上有非常多的消息中间件,rabbitMQ、kafka、rocketMQ、pulsar、 redis等等,多得令人眼花缭乱。它们到底有什么异同,你应该选哪个?本文尝试通过技术演进的方式,以redis、kafka和 pulsar为例,逐步深入,讲讲它们架构和原理,帮助你更好地理解和学习消息队列。
一、最基础的队列
最基础的消息队列其实就是一个双端队列,我们可以用双向链表来实现,如下图所示:


- push_front:添加元素到队首;
- pop_tail:从队尾取出元素。
有了这样的数据结构之后,我们就可以在内存中构建一个消息队列,一些任务不停地往队列里添加消息,同时另一些任务不断地从队尾有序地取出这些消息。添加消息的任务我们称为producer,而取出并使用消息的任务,我们称之为consumer。
要实现这样的内存消息队列并不难,甚至可以说很容易。但是如果要让它能在应对海量的并发读写时保持高效,还是需要下很多功夫的。
二、Redis的队列
redis刚好提供了上述的数据结构——list。redis list支持:
- lpush:从队列左边插入数据;
- rpop:从队列右边取出数据。
这正好对应了我们队列抽象的push_front和pop_tail,因此我们可以直接把redis的list当成一个消息队列来使用。而且redis本身对高并发做了很好的优化,内部数据结构经过了精心地设计和优化。所以从某种意义上讲,用redis的list大概率比你自己重新实现一个list强很多。
但另一方面,使用redis list作为消息队列也有一些不足,比如:
- 消息持久化:redis是内存数据库,虽然有aof和rdb两种机制进行持久化,但这只是辅助手段,这两种手段都是不可靠的。当redis服务器宕机时一定会丢失一部分数据,这对于很多业务都是没法接受的。
- 热key性能问题:不论是用codis还是twemproxy这种集群方案,对某个队列的读写请求最终都会落到同一台redis实例上,并且无法通过扩容来解决问题。如果对某个list的并发读写非常高,就产生了无法解决的热key,严重可能导致系统崩溃。
- 没有确认机制:每当执行rpop消费一条数据,那条消息就被从list中永久删除了。如果消费者消费失败,这条消息也没法找回了。你可能说消费者可以在失败时把这条消息重新投递到进队列,但这太理想了,极端一点万一消费者进程直接崩了呢,比如被kill -9,panic,coredump…
- 不支持多订阅者:一条消息只能被一个消费者消费,rpop之后就没了。如果队列中存储的是应用的日志,对于同一条消息,监控系统需要消费它来进行可能的报警,BI系统需要消费它来绘制报表,链路追踪需要消费它来绘制调用关系……这种场景redis list就没办法支持了。
- 不支持二次消费:一条消息rpop之后就没了。如果消费者程序运行到一半发现代码有bug,修复之后想从头再消费一次就不行了。
对于上述的不足,目前看来第一条(持久化)是可以解决的。很多公司都有团队基于rocksdb leveldb进行二次开发,实现了支持redis协议的kv存储。这些存储已经不是redis了,但是用起来和redis几乎一样。它们能够保证数据的持久化,但对于上述的其他缺陷也无能为力了。
其实redis 5.0开始新增了一个stream数据类型,它是专门设计成为消息队列的数据结构,借鉴了很多kafka的设计,但是依然还有很多问题…直接进入到kafka的世界它不香吗?
三、Kafka
从上面你可以看到,一个真正的消息中间件不仅仅是一个队列那么简单。尤其是当它承载了公司大量业务的时候,它的功能完备性、吞吐量、稳定性、扩展性都有非常苛刻的要求。kafka应运而生,它是专门设计用来做消息中间件的系统。
前面说redis list的不足时,虽然有很多不足,但是如果你仔细思考,其实可以归纳为两点:
- 热key的问题无法解决,即:无法通过加机器解决性能问题;
- 数据会被删除:rpop之后就没了,因此无法满足多个订阅者,无法重新从头再消费,无法做ack。
这两点也是kafka要解决的核心问题。
热key的本质问题是数据都集中在一台实例上,所以想办法把它分散到多个机器上就好了。为此,kafka提出了partition的概念。一个队列(redis中的list),对应到kafka里叫topic。kafka把一个topic拆成了多个partition,每个partition可以分散到不同的机器上,这样就可以把单机的压力分散到多台机器上。因此topic在kafka中更多是一个逻辑上的概念,实际存储单元都是partition。
其实redis的list也能实现这种效果,不过这需要在业务代码中增加额外的逻辑。比如可以建立n个list,key1, key2, …, keyn,客户端每次往不同的key里push,消费端也可以同时从key1到keyn这n个list中rpop消费数据,这就能达到kafka多partition的效果。所以你可以看到,partition就是一个非常朴素的概念,用来把请求分散到多台机器。
redis list中另一个大问题是rpop会删除数据,所以kafka的解决办法也很简单,不删就行了嘛。kafka用游标(cursor)解决这个问题。
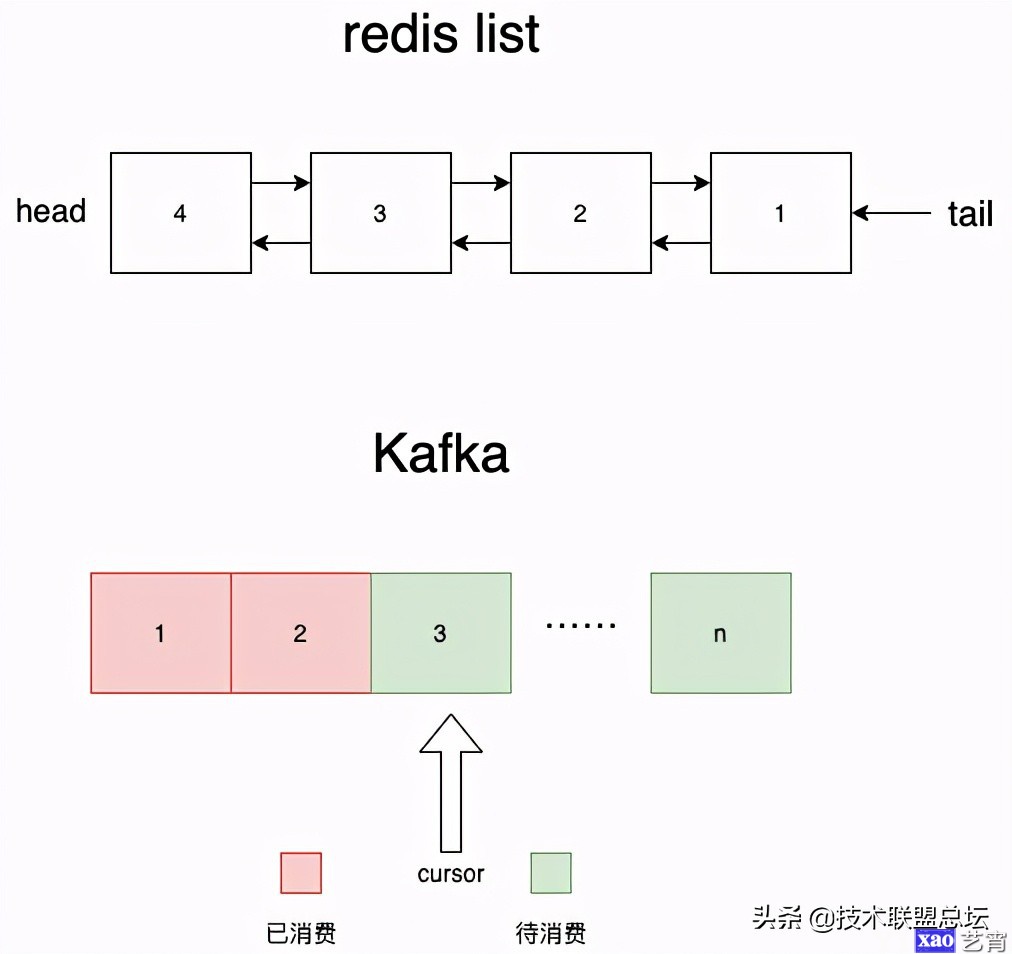
和redis list不同的是,首先kafka的topic(实际上是partion)是用的单向队列来存储数据的,新数据每次直接追加到队尾。同时它维护了一个游标cursor,从头开始,每次指向即将被消费的数据的下标。每消费一条,cursor 1 。通过这种方式,kafka也能和redis list一样实现先入先出的语义,但是kafka每次只需要更新游标,并不会去删数据。
这样设计的好处太多了,尤其是性能方面,顺序写一直是最大化利用磁盘带宽的不二法门。但我们主要讲讲游标这种设计带来功能上的优势。
首先可以支持消息的ACK机制了。由于消息不会被删除,因此可以等消费者明确告知kafka这条消息消费成功以后,再去更新游标。这样的话,只要kafka持久化存储了游标的位置,即使消费失败进程崩溃,等它恢复时依然可以重新消费
第二是可以支持分组消费:
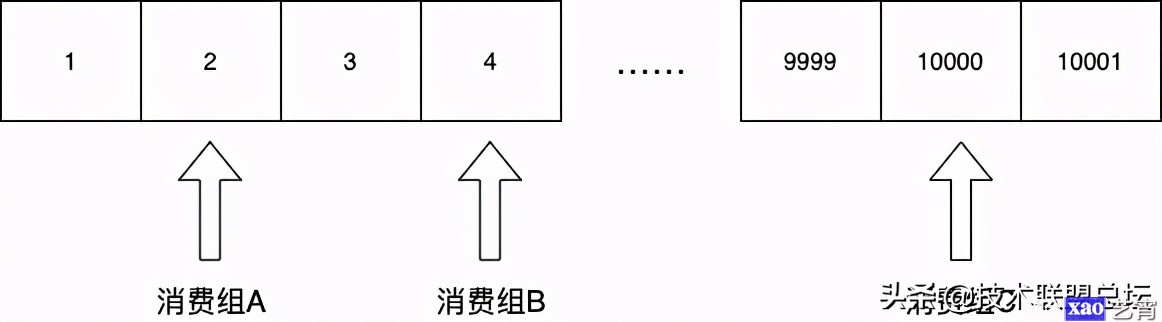
这里需要引入一个消费组的概念,这个概念非常简单,因为消费组本质上就是一组游标。对于同一个topic,不同的消费组有各自的游标。监控组的游标指向第二条,BI组的游标指向第4条,trace组指向到了第10000条……各消费者游标彼此隔离,互不影响。
通过引入消费组的概念,就可以非常容易地支持多业务方同时消费一个topic,也就是说所谓的1-N的“广播”,一条消息广播给N个订阅方。
最后,通过游标也很容易实现重新消费。因为游标仅仅就是记录当前消费到哪一条数据了,要重新消费的话直接修改游标的值就可以了。你可以把游标重置为任何你想要指定的位置,比如重置到0重新开始消费,也可以直接重置到最后,相当于忽略现有所有数据。
因此你可以看到,kafka这种数据结构相比于redis的双向链表有了一个质的飞跃,不仅是性能上,同时也是功能上,全面的领先。
我们可以来看看kafka的一个简单的架构图:
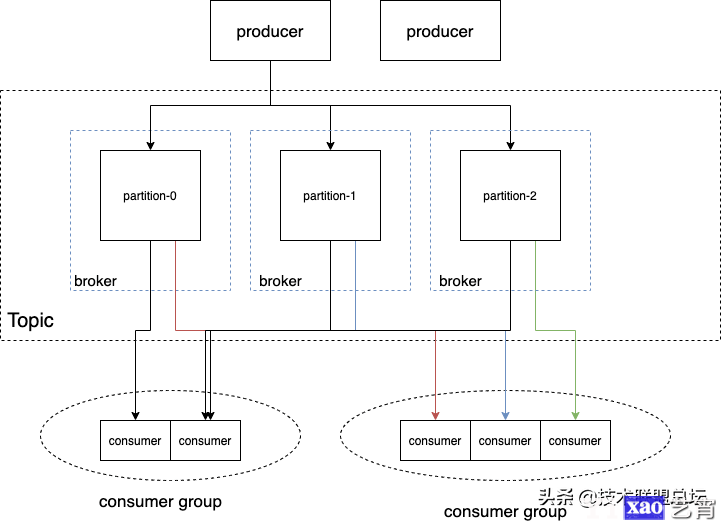
从这个图里我们可以看出,topic是一个逻辑上的概念,不是一个实体。一个topic包含多个partition,partition分布在多台机器上。这个机器,kafka中称之为broker。(kafka集群中的一个broker对应redis集群中的一个实例)。对于一个topic,可以有多个不同的消费组同时进行消费。一个消费组内部可以有多个消费者实例同时进行消费,这样可以提高消费速率。
但是这里需要非常注意的是,一个partition只能被消费组中的一个消费者实例来消费。换句话说,消费组中如果有多个消费者,不能够存在两个消费者同时消费一个partition的场景。
为什么呢?其实kafka要在partition级别提供顺序消费的语义,如果多个consumer消费一个partition,即使kafka本身是按顺序分发数据的,但是由于网络延迟等各种情况,consumer并不能保证按kafka的分发顺序接收到数据,这样达到消费者的消息顺序就是无法保证的。因此一个partition只能被一个consumer消费。kafka各consumer group的游标可以表示成类似这样的数据结构:
{
"topic-foo": {
"groupA": {
"partition-0": 0,
"partition-1": 123,
"partition-2": 78
},
"groupB": {
"partition-0": 85,
"partition-1": 9991,
"partition-2": 772
},
}
}了解了kafka的宏观架构,你可能会有个疑惑,kafka的消费如果只是移动游标并不删除数据,那么随着时间的推移数据肯定会把磁盘打满,这个问题该如何解决呢?这就涉及到kafka的retention机制,也就是消息过期,类似于redis中的expire。
不同的是,redis是按key来过期的,如果你给redis list设置了1分钟有效期,1分钟之后redis直接把整个list删除了。而kafka的过期是针对消息的,不会删除整个topic(partition),只会删除partition中过期的消息。不过好在kafka的partition是单向的队列,因此队列中消息的生产时间都是有序的。因此每次过期删除消息时,从头开始删就行了。
看起来似乎很简单,但仔细想一下还是有不少问题。举例来说,假如topicA-partition-0的所有消息被写入到一个文件中,比如就叫topicA-partition-0.log。我们再把问题简化一下,假如生产者生产的消息在topicA-partition-0.log中一条消息占一行,很快这个文件就到200G了。现在告诉你,这个文件前x行失效了,你应该怎么删除呢?非常难办,这和让你删除一个数组中的前n个元素一样,需要把后续的元素向前移动,这涉及到大量的CPU copy操作。假如这个文件有10M,这个删除操作的代价都非常大,更别说200G了。
因此,kafka在实际存储partition时又进行了一个拆分。topicA-partition-0的数据并不是写到一个文件里,而是写到多个segment文件里。假如设置的一个segment文件大小上限是100M,当写满100M时就会创建新的segment文件,后续的消息就写到新创建的segment文件,就像我们业务系统的日志文件切割一样。这样做的好处是,当segment中所有消息都过期时,可以很容易地直接删除整个文件。而由于segment中消息是有序的,看是否都过期就看最后一条是否过期就行了。
1. Kafka中的数据查找
topic的一个partition是一个逻辑上的数组,由多个segment组成,如下图所示:
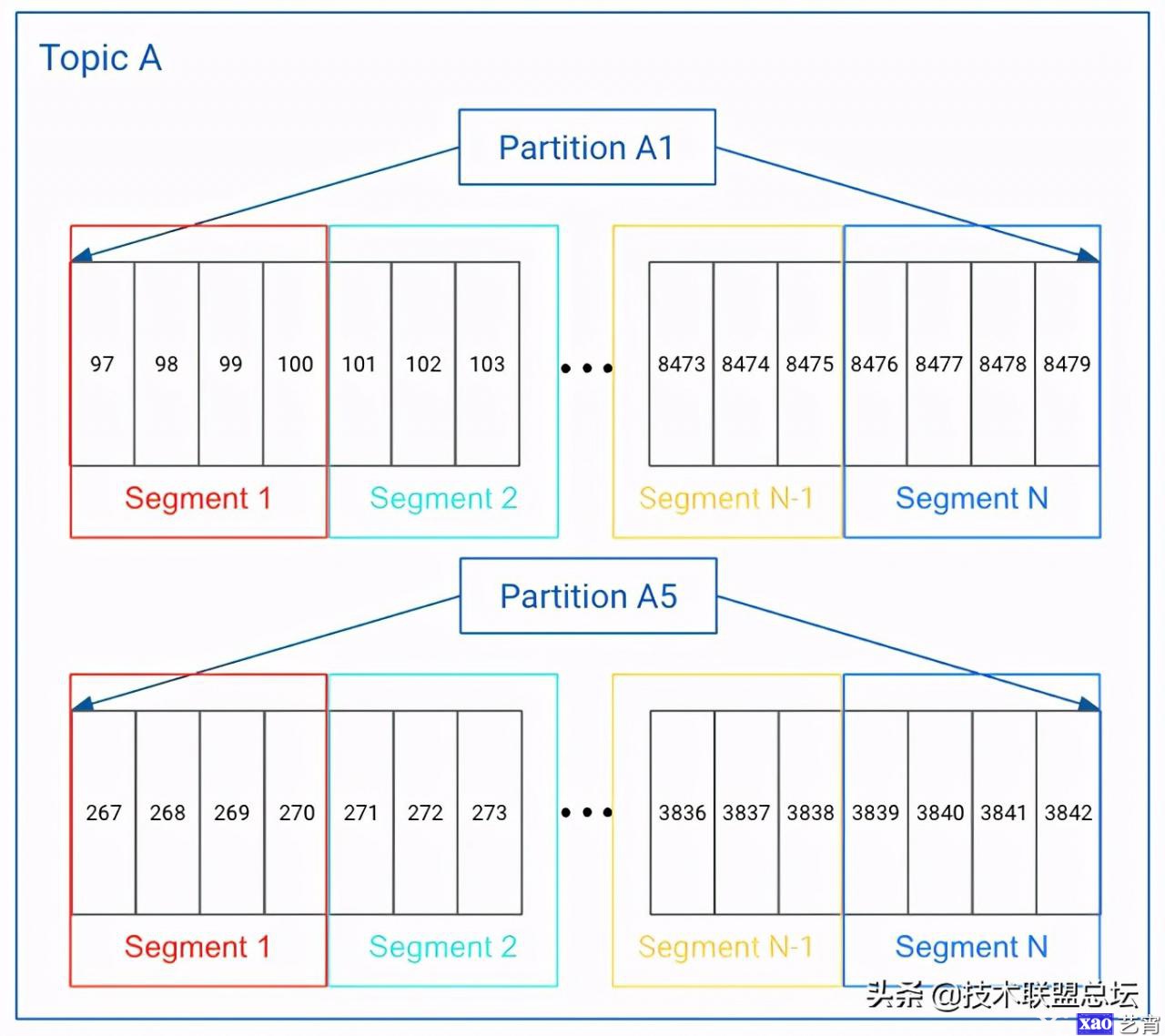
这时候就有一个问题,如果我把游标重置到一个任意位置,比如第2897条消息,我怎么读取数据呢?
根据上面的文件组织结构,你可以发现我们需要确定两件事才能读出对应的数据:
- 第2897条消息在哪个segment文件里;
- 第2897条消息在segment文件里的什么位置。
为了解决上面两个问题,kafka有一个非常巧妙的设计。首先,segment文件的文件名是以该文件里第一条消息的offset来命名的。一开始的segment文件名是 0.log,然后一直写直到写了18234条消息后,发现达到了设置的文件大小上限100M,然后就创建一个新的segment文件,名字是18234.log……
- /kafka/topic/order_create/partition-0
- 0.log
- 18234.log #segment file
- 39712.log
- 54101.log当我们要找offset为x的消息在哪个segment时,只需要通过文件名做一次二分查找就行了。比如offset为2879的消息(第2880条消息),显然就在0.log这个segment文件里。
定位到segment文件之后,另一个问题就是要找到该消息在文件中的位置,也就是偏移量。如果从头开始一条条地找,这个耗时肯定是无法接受的!kafka的解决办法就是索引文件。
就如mysql的索引一样,kafka为每个segment文件创建了一个对应的索引文件。索引文件很简单,每条记录就是一个kv组,key是消息的offset,value是该消息在segment文件中的偏移量:
|
offset |
position |
|
0 |
0 |
|
1 |
124 |
|
2 |
336 |
每个segment文件对应一个索引文件:
- /kafka/topic/order_create/partition-0
- 0.log
- 0.index
- 18234.log #segment file
- 18234.index #index file
- 39712.log
- 39712.index
- 54101.log
- 54101.index有了索引文件,我们就可以拿到某条消息具体的位置,从而直接进行读取。再捋一遍这个流程:
- 当要查询offset为x的消息
- 利用二分查找找到这条消息在y.log
- 读取y.index文件找到消息x的y.log中的位置
- 读取y.log的对应位置,获取数据
通过这种文件组织形式,我们可以在kafka中非常快速地读取出任何一条消息。但这又引出了另一个问题,如果消息量特别大,每条消息都在index文件中加一条记录,这将浪费很多空间。
可以简单地计算一下,假如index中一条记录16个字节(offset 8 position 8),一亿条消息就是16*10^8字节=1.6G。对于一个稍微大一点的公司,kafka用来收集日志的话,一天的量远远不止1亿条,可能是数十倍上百倍。这样的话,index文件就会占用大量的存储。因此,权衡之下kafka选择了使用”稀疏索引“。
所谓稀疏索引就是并非所有消息都会在index文件中记录它的position,每间隔多少条消息记录一条,比如每间隔10条消息记录一条offset-position:
|
offset |
position |
|
0 |
0 |
|
10 |
1852 |
|
20 |
4518 |
|
30 |
6006 |
|
40 |
8756 |
|
50 |
10844 |
这样的话,如果当要查询offset为x的消息,我们可能没办法查到它的精确位置,但是可以利用二分查找,快速地确定离他最近的那条消息的位置,然后往后多读几条数据就可以读到我们想要的消息了。
比如,当我们要查到offset为33的消息,按照上表,我们可以利用二分查找定位到offset为30的消息所在的位置,然后去对应的log文件中从该位置开始向后读取3条消息,第四条就是我们要找的33。这种方式其实就是在性能和存储空间上的一个折中,很多系统设计时都会面临类似的选择,牺牲时间换空间还是牺牲空间换时间。
到这里,我们对kafka的整体架构应该有了一个比较清晰的认识了。不过在上面的分析中,我故意隐去了kafka中另一个非常非常重要的点,就是高可用方面的设计。因为这部分内容比较晦涩,会引入很多分布式理论的复杂性,妨碍我们理解kafka的基本模型。在接下来的部分,将着重讨论这个主题。
2. Kafka高可用
高可用(HA)对于企业的核心系统来说是至关重要的。因为随着业务的发展,集群规模会不断增大,而大规模集群中总会出现故障,硬件、网络都是不稳定的。当系统中某些节点各种原因无法正常使用时,整个系统可以容忍这个故障,继续正常对外提供服务,这就是所谓的高可用性。对于有状态服务来说,容忍局部故障本质上就是容忍丢数据(不一定是永久,但是至少一段时间内读不到数据)。
系统要容忍丢数据,最朴素也是唯一的办法就是做备份,让同一份数据复制到多台机器,所谓的冗余,或者说多副本。为此,kafka引入 leader-follower的概念。topic的每个partition都有一个leader,所有对这个partition的读写都在该partition leader所在的broker上进行。partition的数据会被复制到其它broker上,这些broker上对应的partition就是follower:
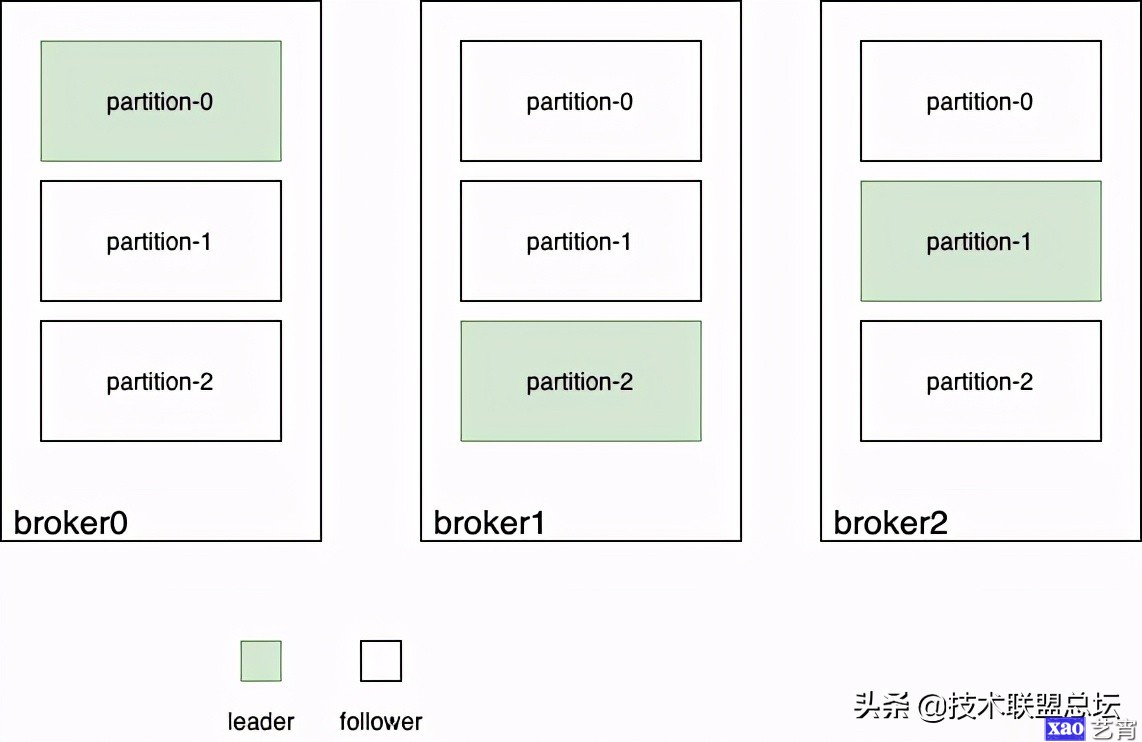
producer在生产消息时,会直接把消息发送到partition leader上,partition leader把消息写入自己的log中,然后等待follower来拉取数据进行同步。具体交互如下:
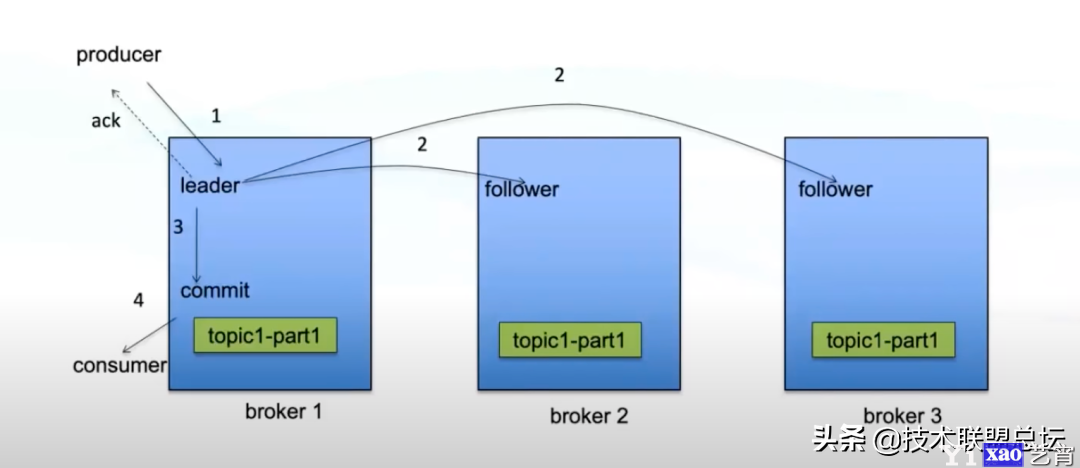
上图中对producer进行ack的时机非常关键,这直接关系到kafka集群的可用性和可靠性。
- 如果producer的数据到达leader并成功写入leader的log就进行ack优点:不用等数据同步完成,速度快,吞吐率高,可用性高;缺点:如果follower数据同步未完成时leader挂了,就会造成数据丢失,可靠性低。
- 如果等follower都同步完数据时进行ack优点:当leader挂了之后follower中也有完备的数据,可靠性高;缺点:等所有follower同步完成很慢,性能差,容易造成生产方超时,可用性低。
而具体什么时候进行ack,对于kafka来说是可以根据实际应用场景配置的。
其实kafka真正的数据同步过程还是非常复杂的,本文主要是想讲一讲kafka的一些核心原理,数据同步里面涉及到的很多技术细节,HW epoch等,就不在此一一展开了。最后展示一下kafka的一个全景图:
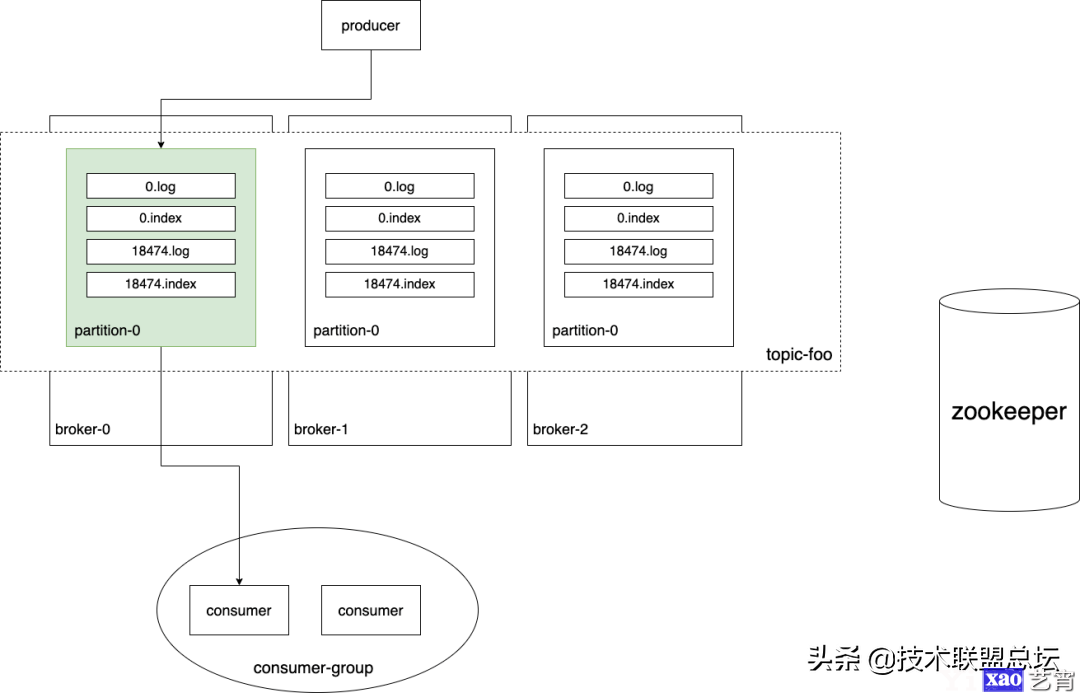
最后对kafka进行一个简要地总结:kafka通过引入partition的概念,让topic能够分散到多台broker上,提高吞吐率。但是引入多partition的代价就是无法保证topic维度的全局顺序性,需要这种特性的场景只能使用单个partition。在内部,每个partition以多个segment文件的方式进行存储,新来的消息append到最新的segment log文件中,并使用稀疏索引记录消息在log文件中的位置,方便快速读取消息。当数据过期时,直接删除过期的segment文件即可。为了实现高可用,每个partition都有多个副本,其中一个是leader,其它是follower,分布在不同的broker上。对partition的读写都在leader所在的broker上完成,follower只会定时地拉取leader的数据进行同步。当leader挂了,系统会选出和leader保持同步的follower作为新的leader,继续对外提供服务,大大提高可用性。在消费端,kafka引入了消费组的概念,每个消费组都可以互相独立地消费topic,但一个partition只能被消费组中的唯一一个消费者消费。消费组通过记录游标,可以实现ACK机制、重复消费等多种特性。除了真正的消息记录在segment中,其它几乎所有meta信息都保存在全局的zookeeper中。
3. 优缺点
(1)优点:kafka的优点非常多
- 高性能:单机测试能达到 100w tps;
- 低延时:生产和消费的延时都很低,e2e的延时在正常的cluster中也很低;
- 可用性高:replicate isr 选举 机制保证;
- 工具链成熟:监控 运维 管理 方案齐全;
- 生态成熟:大数据场景必不可少 kafka stream.
(2)不足
- 无法弹性扩容:对partition的读写都在partition leader所在的broker,如果该broker压力过大,也无法通过新增broker来解决问题;
- 扩容成本高:集群中新增的broker只会处理新topic,如果要分担老topic-partition的压力,需要手动迁移partition,这时会占用大量集群带宽;
- 消费者新加入和退出会造成整个消费组rebalance:导致数据重复消费,影响消费速度,增加e2e延迟;
- partition过多会使得性能显著下降:ZK压力大,broker上partition过多让磁盘顺序写几乎退化成随机写。
在了解了kafka的架构之后,你可以仔细想一想,为什么kafka扩容这么费劲呢?其实这本质上和redis集群扩容是一样的!当redis集群出现热key时,某个实例扛不住了,你通过加机器并不能解决什么问题,因为那个热key还是在之前的某个实例中,新扩容的实例起不到分流的作用。kafka类似,它扩容有两种:新加机器(加broker)以及给topic增加partition。给topic新加partition这个操作,你可以联想一下mysql的分表。比如用户订单表,由于量太大把它按用户id拆分成1024个子表user_order_{0..1023},如果到后期发现还不够用,要增加这个分表数,就会比较麻烦。因为分表总数增多,会让user_id的hash值发生变化,从而导致老的数据无法查询。所以只能停服做数据迁移,然后再重新上线。kafka给topic新增partition一样的道理,比如在某些场景下msg包含key,那producer就要保证相同的key放到相同的partition。但是如果partition总量增加了,根据key去进行hash,比如 hash(key) % parition_num,得到的结果就不同,就无法保证相同的key存到同一个partition。当然也可以在producer上实现一个自定义的partitioner,保证不论怎么扩partition相同的key都落到相同的partition上,但是这又会使得新增加的partition没有任何数据。
其实你可以发现一个问题,kafka的核心复杂度几乎都在存储这一块。数据如何分片,如何高效的存储,如何高效地读取,如何保证一致性,如何从错误中恢复,如何扩容再平衡……
上面这些不足总结起来就是一个词:scalebility。通过直接加机器就能解决问题的系统才是大家的终极追求。Pulsar号称云原生时代的分布式消息和流平台,所以接下来我们看看pulsar是怎么样的。
四、Pulsar
kafka的核心复杂度是它的存储,高性能、高可用、低延迟、支持快速扩容的分布式存储不仅仅是kafka的需求,应该是现代所有系统共同的追求。而apache项目底下刚好有一个专门就是为日志存储打造的这样的系统,它叫bookeeper!
有了专门的存储组件,那么实现一个消息系统剩下的就是如何来使用这个存储系统来实现feature了。pulsar就是这样一个”计算-存储 分离“的消息系统:
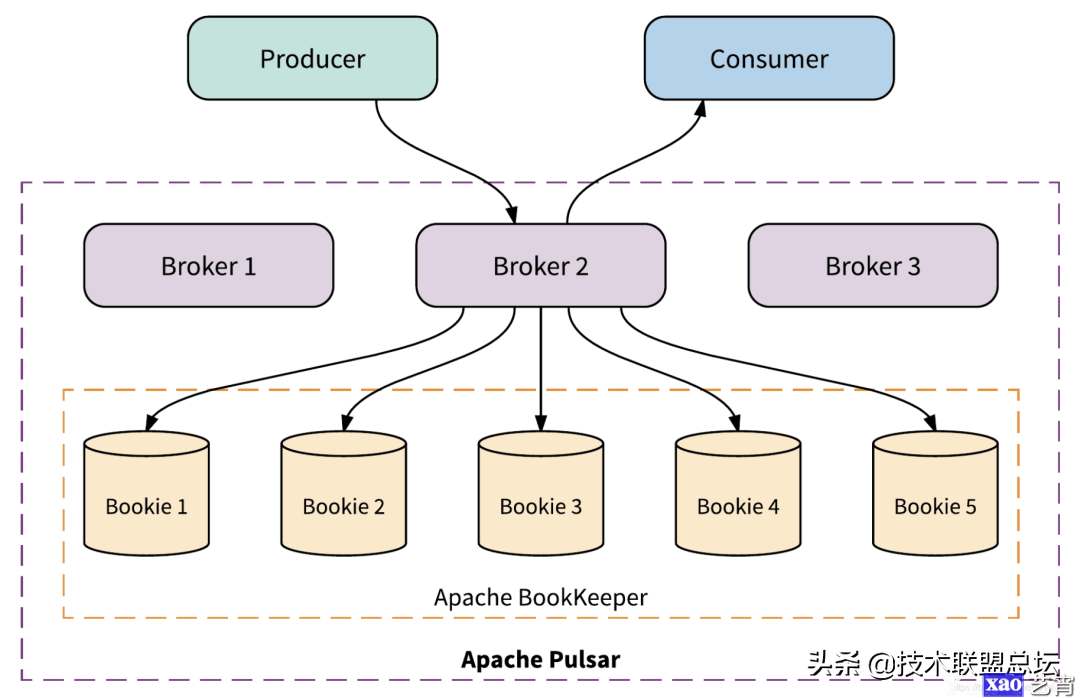
pulsar利用bookeeper作为存储服务,剩下的是计算层。这其实是目前非常流行的架构也是一种趋势,很多新型的存储都是这种”存算分离“的架构。比如tidb,底层存储其实是tikv这种kv存储。tidb是更上层的计算层,自己实现sql相关的功能。还有的例子就是很多”持久化”redis产品,大部分底层依赖于rocksdb做kv存储,然后基于kv存储关系实现redis的各种数据结构。
在pulsar中,broker的含义和kafka中的broker是一致的,就是一个运行的pulsar实例。但是和kafka不同的是,pulsar的broker是无状态服务,它只是一个”API接口层“,负责处理海量的用户请求,当用户消息到来时负责调用bookeeper的接口写数据,当用户要查询消息时从bookeeper中查数据,当然这个过程中broker本身也会做很多缓存之类的。同时broker也依赖于zookeeper来保存很多元数据的关系。
由于broker本身是无状态的,因此这一层可以非常非常容易地进行扩容,尤其是在k8s环境下,点下鼠标的事儿。至于消息的持久化,高可用,容错,存储的扩容,这些都通通交给bookeeper来解决。
但就像能量守恒定律一样,系统的复杂性也是守恒的。实现既高性能又可靠的存储需要的技术复杂性,不会凭空消失,只会从一个地方转移到另一个地方。就像你写业务逻辑,产品经理提出了20个不同的业务场景,就至少对应20个if else,不论你用什么设计模式和架构,这些if else不会被消除,只会从从一个文件放到另一个文件,从一个对象放到另一个对象而已。所以那些复杂性一定会出现在bookeeper中,并且会比kafka的存储实现更为复杂。
但是pulsar存算分离架构的一个好处就是,当我们在学习pulsar时可以有一个比较明确的界限,所谓的concern segregation。只要理解bookeeper对上层的broker提供的API语义,即使不了解bookeeper内部的实现,也能很好的理解pulsar的原理。
接下来你可以思考一个问题:既然pulsar的broker层是无状态的服务,那么我们是否可以随意在某个broker进行对某个topic的数据生产呢?
看起来似乎没什么问题,但答案还是否定的——不可以。为什么呢?想一想,假如生产者可以在任意一台broker上对topic进行生产,比如生产3条消息a b c,三条生产消息的请求分别发送到broker A B C,那最终怎么保证消息按照a b c的顺序写入bookeeper呢?这是没办法保证,只有让a b c三条消息都发送到同一台broker,才能保证消息写入的顺序。
既然如此,那似乎又回到和kafka一样的问题,如果某个topic写入量特别特别大,一个broker扛不住怎么办?所以pulsar和kafka一样,也有partition的概念。一个topic可以分成多个partition,为了每个partition内部消息的顺序一致,对每个partition的生产必须对应同一台broker。
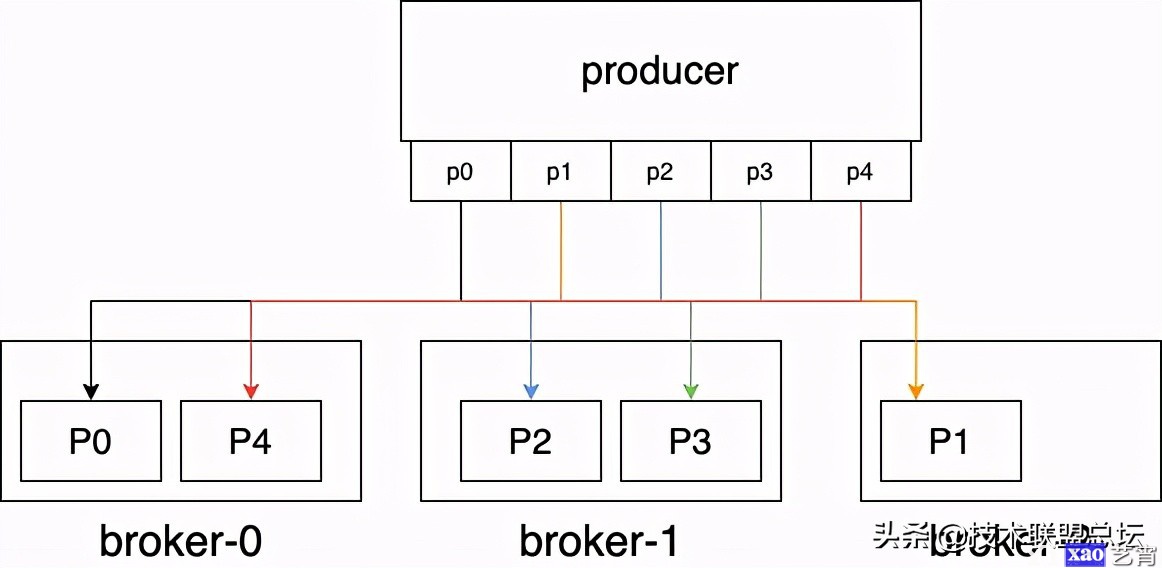
这里看起来似乎和kafka没区别,也是每个partition对应一个broker,但是其实差别很大。为了保证对partition的顺序写入,不论kafka还是pulsar都要求写入请求发送到partition对应的broker上,由该broker来保证写入的顺序性。然而区别在于,kafka同时会把消息存储到该broker上,而pulsar是存储到bookeeper上。这样的好处是,当pulsar的某台broker挂了,可以立刻把partition对应的broker切换到另一个broker,只要保证全局只有一个broker对topic-partition-x有写权限就行了,本质上只是做一个所有权转移而已,不会有任何数据的搬迁。
当对partition的写请求到达对应broker时,broker就需要调用bookeeper提供的接口进行消息存储。和kafka一样,pulsar在这里也有segment的概念,而且和kafka一样的是,pulsar也是以segment为单位进行存储的(respect respect respect)。
为了说清楚这里,就不得不引入一个bookeeper的概念,叫ledger,也就是账本。可以把ledger类比为文件系统上的一个文件,比如在kafka中就是写入到xxx.log这个文件里。pulsar以segment为单位,存入bookeeper中的ledger。
在bookeeper集群中每个节点叫bookie(为什么集群的实例在kafka叫broker在bookeeper又叫bookie……无所谓,名字而已,作者写了那么多代码,还不能让人开心地命个名啊)。在实例化一个bookeeper的writer时,就需要提供3个参数:
- 节点数n:bookeeper集群的bookie数;
- 副本数m:某一个ledger会写入到n个bookie中的m个里,也就是说所谓的m副本;
- 确认写入数t:每次向ledger写入数据时(并发写入到m个bookie),需要确保收到t个acks,才返回成功。
bookeeper会根据这三个参数来为我们做复杂的数据同步,所以我们不用担心那些副本啊一致性啊的东西,直接调bookeeper的提供的append接口就行了,剩下的交给它来完成。
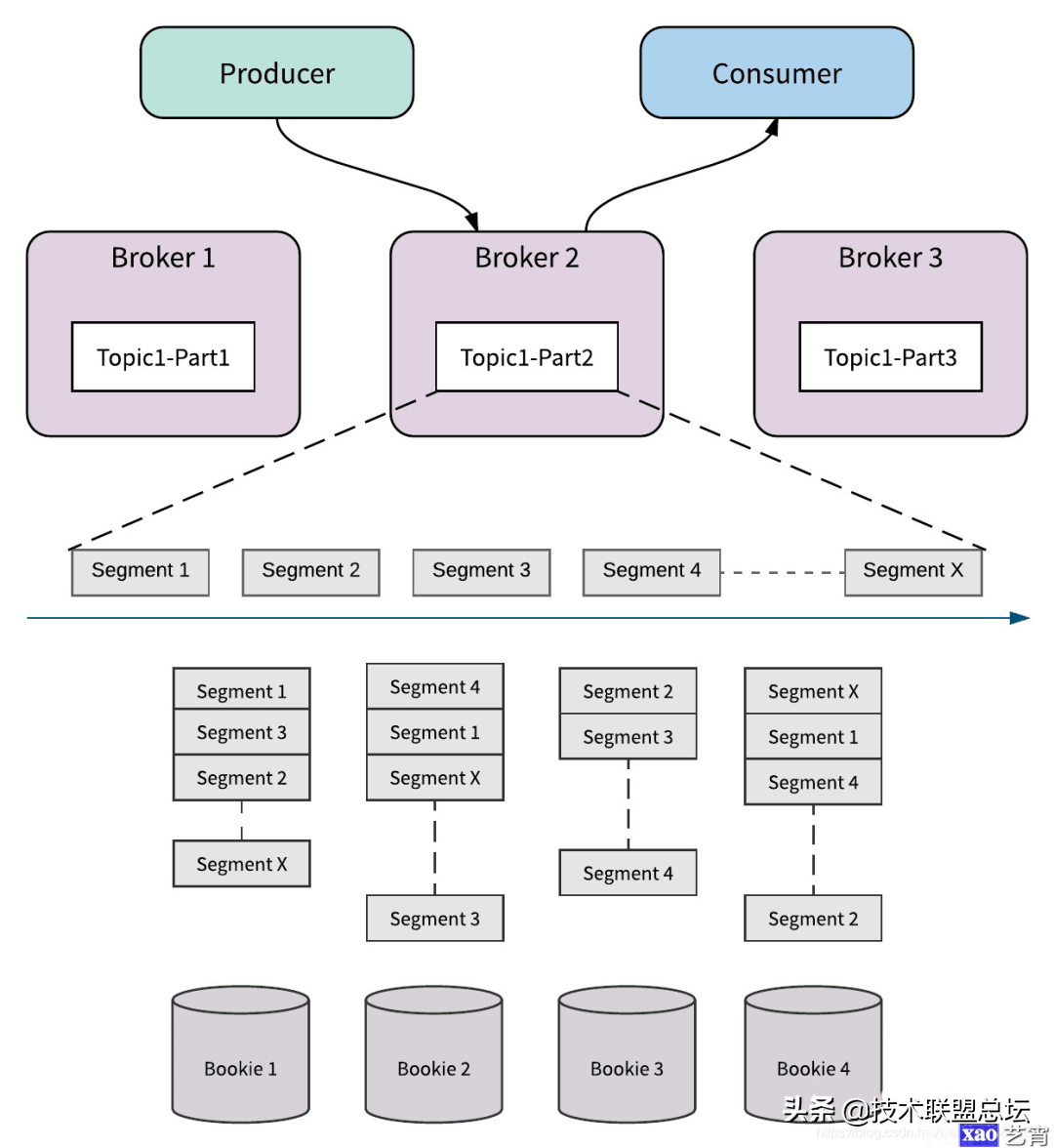
如上图所示,parition被分为了多个segment,每个segment会写入到4个bookie其中的3个中。比如segment1就写入到了bookie1,2,4中,segment2写入到bookie1,3,4中…
这其实就相当于把kafka某个partition的segment均匀分布到了多台存储节点上。这样的好处是什么呢?在kafka中某个partition是一直往同一个broker的文件系统中进行写入,当磁盘不够用了,就需要做非常麻烦的扩容 迁移数据的操作。而对于pulsar,由于partition中不同segment可以保存在bookeeper不同的bookies上,当大量写入导致现有集群bookie磁盘不够用时,我们可以快速地添加机器解决问题,让新的segment寻找最合适的bookie(磁盘空间剩余最多或者负载最低等)进行写入,只要记住segment和bookies的关系就好了。
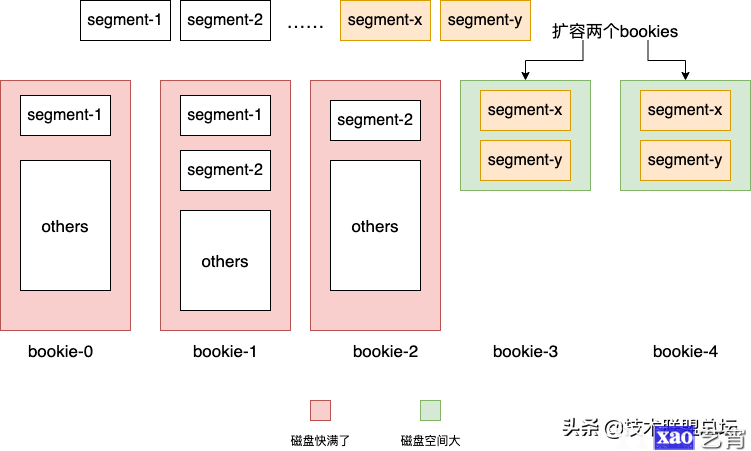
由于partition以segment为粒度均匀的分散到bookeeper上的节点上,这使得存储的扩容变得非常非常容易。这也是Pulsar一直宣称的存算分离架构的先进性的体现:
- broker是无状态的,随便扩容;
- partition以segment为单位分散到整个bookeeper集群,没有单点,也可以轻易地扩容;
- 当某个bookie发生故障,由于多副本的存在,可以另外t-1个副本中随意选出一个来读取数据,不间断地对外提供服务,实现高可用。
其实在理解kafka的架构之后再来看pulsar,你会发现pulsar的核心就在于bookeeper的使用以及一些metadata的存储。但是换个角度,正是这个恰当的存储和计算分离的架构,帮助我们分离了关注点,从而能够快速地去学习上手。
消费模型
Pulsar相比于kafka另一个比较先进的设计就是对消费模型的抽象,叫做subscription。通过这层抽象,可以支持用户各种各样的消费场景。还是和kafka进行对比,kafka中只有一种消费模式,即一个或多个partition对一个consumer。如果想要让一个partition对多个consumer,就无法实现了。pulsar通过subscription,目前支持4种消费方式:
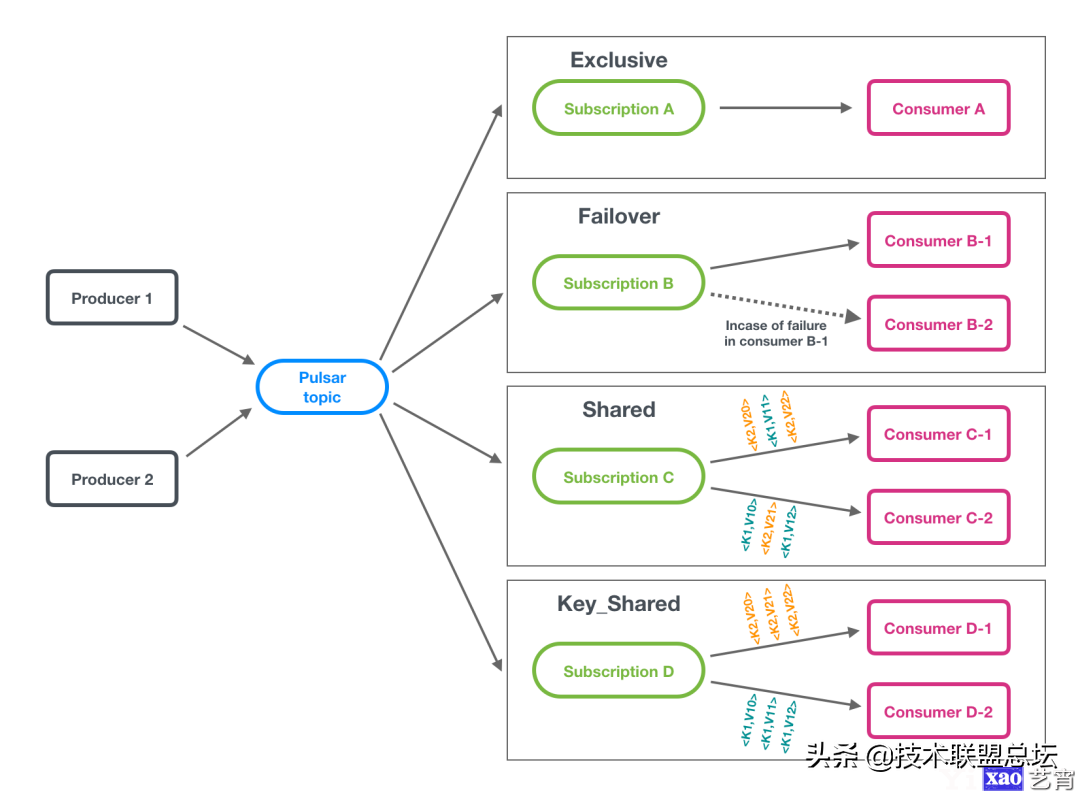
可以把pulsar的subscription看成kafka的consumer group,但subscription更进一步,可以设置这个”consumer group“的消费类型:
- exclusive:消费组里有且仅有一个consumer能够进行消费,其它的根本连不上pulsar;
- failover:消费组里的每个消费者都能连上每个partition所在的broker,但有且仅有一个consumer能消费到数据。当这个消费者崩溃了,其它的消费者会被选出一个来接班;
- shared:消费组里所有消费者都能消费topic中的所有partition,消息以round-robin的方式来分发;
- key-shared:消费组里所有消费者都能消费到topic中所有partition,但是带有相同key的消息会保证发送给同一个消费者。
这些消费模型可以满足多种业务场景,用户可以根据实际情况进行选择。通过这层抽象,pulsar既支持了queue消费模型,也支持了stream消费模型,还可以支持其它无数的消费模型(只要有人提pr),这就是pulsar所说的统一了消费模型。
其实在消费模型抽象的底下,就是不同的cursor管理逻辑。怎么ack,游标怎么移动,怎么快速查找下一条需要重试的msg……这都是一些技术细节,但是通过这层抽象,可以把这些细节进行隐藏,让大家更关注于应用。
五、存算分离架构
其实技术的发展都是螺旋式的,很多时候你会发现最新的发展方向又回到了20年前的技术路线了。
在20年前,由于普通计算机硬件设备的局限性,对大量数据的存储是通过NAS(Network Attached Storage)这样的“云端”集中式存储来完成。但这种方式的局限性也很多,不仅需要专用硬件设备,而且最大的问题就是难以扩容来适应海量数据的存储。
数据库方面也主要是以Oracle小型机为主的方案。然而随着互联网的发展,数据量越来越大,Google后来又推出了以普通计算机为主的分布式存储方案,任意一台计算机都能作为一个存储节点,然后通过让这些节点协同工作组成一个更大的存储系统,这就是HDFS。
然而移动互联网使得数据量进一步增大,并且4G 5G的普及让用户对延迟也非常敏感,既要可靠,又要快,又要可扩容的存储逐渐变成了一种企业的刚需。而且随着时间的推移,互联网应用的流量集中度会越来越高,大企业的这种刚需诉求也越来越强烈。
因此,可靠的分布式存储作为一种基础设施也在不断地完善。它们都有一个共同的目标,就是让你像使用filesystem一样使用它们,并且具有高性能高可靠自动错误恢复等多种功能。然而我们需要面对的一个问题就是CAP理论的限制,线性一致性(C),可用性(A),分区容错性(P),三者只能同时满足两者。因此不可能存在完美的存储系统,总有那么一些“不足”。我们需要做的其实就是根据不同的业务场景,选用合适的存储设施,来构建上层的应用。这就是pulsar的逻辑,也是tidb等newsql的逻辑,也是未来大型分布式系统的基本逻辑,所谓的“云原生”。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/23374.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
PostgreSQL数据目录深度揭秘
一 概述PostgreSQL是一个功能非常强大的、源代码开放的客户/服务器关系型数据库管理系统(RDBMS),PostgreSQL被业界誉为“先进的开源数据库”,支持NoSQL数据…
-
python爬虫技术如何挣钱?教你爬虫月入三万!
爬虫技术挣钱方法1:接外包爬虫项目 这是网络爬虫最通常的的挣钱方式,通过外包网站,熟人关系接一个个中小规模的爬虫项目,一般向甲方提供数据抓取,数据结构化,数据清洗等服务。 各位新入…
-
使用Flutter开发简单的Web应用
本文指导读者如何使用 Flutter 运行和部署第一个 Web 应用。– Jis Joe Mathew(作者) Flutter 在 Android 和 iOS 开发方面…
-
incaseformat病毒20s狂删电脑数据的紧急应对措施
1月13日,新型电脑病毒:incaseformat大举进攻用户电脑,使得大量用户的电脑数据丢失,造成大量损失。被incaseformat病毒攻击的电脑会出现除C盘以外,其他磁盘空白…
-
incaseformat蠕虫病毒通过DeleteFileA和RemoveDirectory代码进行文件的删除,并会自动创建启动项重启后删除电脑文件
最近360团队等发布声明incaseformat蠕虫病毒爆发,某企业已经中招,电脑文件被删除。而且疑似创建incaseformat文件等。 大家及时更新系统补丁,更新杀毒软件,打开…
-
IntelliJ idea一劳永逸的高效使用教程
安装好 Intellij idea 之后,进行如下的初始化操作,工作效率提升十倍。 1插件1. Codota 代码智能提示插件 只要打出首字母就能联想出一整条语句,这也太智能了,还…
-
今日头条2021卡怎么得?这个方法极大可能获得
今年头条集卡分2亿活动已经开始,不知不觉集卡活动已经举办4年了,今年的活动依然和去年一样精彩。 1、活动规则 先看一下活动时间,从2月4号到2月11号的21:30。 活动分为两轮,…
-
互联网企业文娱行业布局投资分析:百度、哔哩哔哩、字节跳动
2019年文娱领域排名前十的投资机构中,VC和互联网大企业各占一半,势均力敌。然而,从投资数量上说,互联网大企业的投资数量更多,优势更明显;榜单前五位中,VC仅有IDG一位上榜。 …
-
MES系统与ERP系统如何对接
现在很多的企业都会先上线ERP系统,因为ERP系统对于财务板块的作用,还是显而易见的,特别是制造业,最早上线的是基本上都是ERP系统,但是涉及到数字化工厂、智能工厂、智慧车间这些新…
-
KindEditor上传图片弹出白屏的无反应问题的解决方法
KindEditor是一款非常不错的富文本编辑器,可是这两年常有客户反馈上传图片有问题,不显示选择图片的弹出,也不显示关闭的按钮, 只有空白背景,重复刷新也无效。 这个bug我们一…