在我们的服务器上通常会生成各种日志文件,比如系统日志、 应用日志、安全日志。当系统发生故障时,工程师需要登录到服务器上,在日志里查找故障原因。
如果定位到处理请求的服务器部署了多个实例,那么就需要到每个实例的日志目录下去查看日志。另外每个服务器实例还需要设置日志滚动策略,比如每天生成一个文件,以及日志压缩归档策略等。
管理分布式集群的多台服务器的日志,是很麻烦的事情。尤其是排查故障的时候,服务器太多通过日志找故障太麻烦。因此需要把这些服务器的日志集中管理,并提供集中检索功能,这样就可以提高故障诊断的效率。
业界通用的日志数据管理方案主要包括 Elasticsearch 、 Logstash 和 Kibana 三个组件,这三个组件又先后被收购于Elastic.co公司名下。取三个组件的首字母,业界把这套方案简称为ELK。
什么是ELK?
Logstash :数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。
Elasticsearch :分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点,可以用于全文检索、结构化检索和分析。ES 基于 Lucene 开发,Lucene是现在使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于Lucene来构建搜索引擎。
Kibana :可视化平台。能够搜索、展示存储在 Elasticsearch 中的索引数据,使用Kibana可以很方便地用图表、表格、地图展示和分析数据。
Logstash部署架构
常见的Logstash的部署架构如下图所示,主要由Shipper、Broker和Indexer三个角色组成。


- Shipper:日志收集者,也就是Agent。负责监控本地日志文件的变化,及时读取日志文件的最新内容,经过处理输出到Broker。
- Broker:日志Hub,用来连接多个Shipper和多个Indexer。Redis是Logstash官方推荐的Broker,支持订阅发布和队列两种数据传输模式。
- Indexer:日志存储者。负责从Redis接收日志,经过处理,比如对文本进行格式化,之后写入到本地文件。
无论是Shipper还是Indexer,Logstash始终只做三件事:日志的收集、过滤和输出。主要由三个部分组成:Input 、Filter、Output。
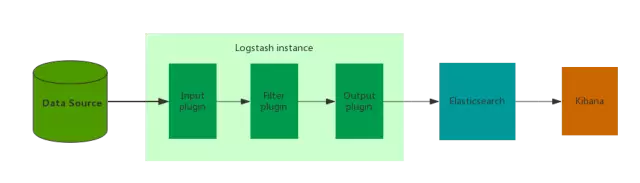
Logstash实例由Input、Filter、Output组成
Input(输入):Logstash实例通过Input插件可以读取多种数据源,输入数据可以是Java日志、Nginx日志 、TCP连接、控制台输入 、Syslog(系统日志)、Redis 、Collectd(系统监控守护进程)等。
Filter(过滤):通过Filter插件可以将日志转换为我们需要的格式。Logstash 提供了丰富的Filter插件,包括date(日志解析)、grok(正则解析)、dissect(分隔符解析)、mutate(字段处理)、json解析、geoip(地理位置数据解析)、ruby等。
Output(输出):通过 Output 插件可以实现数据的多份复制输出,输出目标可以是控制台、Redis 、TCP 、文件、Email等,目前业内常用的输出方式是和搜索引擎Elasticsearch来对接。
接下来我们看一下Logstash与ES如何配合实现ELK架构。
ELK架构
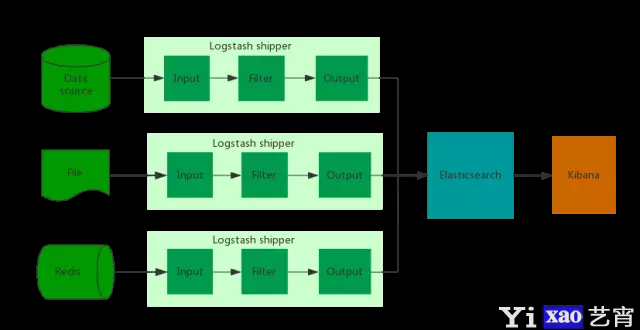
ELK架构
数据收集端:每台服务器都在上面部署 Logstash Shipper来收集日志,经过处理传输到 Elasticsearch 集群。
数据存储与搜索:采用多个 Elasticsearch 节点组成 Elasticsearch 集群,采用集群模式运行,可以避免单个实例压力过重的问题。
数据展示:Kibana 可以根据 Elasticsearch 的数据来绘制各种各样的图表,直观的展示业务实时状况。
Kibana
加入队列的ELK
当并发量较大的时候,由于日志传输峰值较高,会导致 Elasticsearch 集群丢失数据。对于这种Logstash数据超过ES集群处理能力的情况,可以通过队列就能起到削峰填谷的作用, Elasticsearch 集群就不存在丢失数据的问题。
目前业界在日志服务场景中,使用比较多的两种消息队列是Kafka和Redis。Redis 队列多用于实时性较高的消息推送,并不保证可靠。Kafka保证可靠但有点延时。
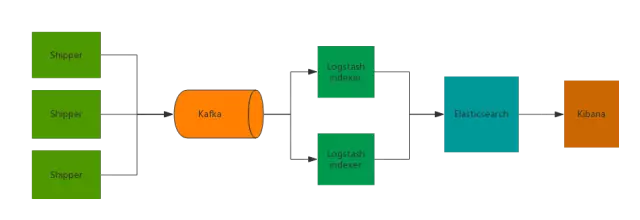
Kafka作为队列加入ELK架构
轻量级的Agent方案:Filebeat
Filebeat 是基于原先 logstash-forwarder 的源码改造出来的,用 Golang 编写,无需依赖 Java 环境就能运行,安装包10M不到。
Filebeat效率高,占用内存和 CPU 比较少,可以解决在服务器上部署Logstash shipper消耗资源较高的问题,非常适合作为日志收集系统的Agent运行在服务器上。

ELK/EFK总结
基于 ELK或EFK的分布式日志解决方案的优势主要体现在以下几个方面:
- 扩展性强:采用高可扩展性的分布式系统架构设计,可以支持每日 TB 级别的新增数据。
- 使用简单:通过用户图形界面实现各种统计分析功能,简单易用,上手快
- 响应迅速:从日志产生到查询可见,能达到秒级完成数据的采集、处理和搜索统计。
- 界面美观:Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
对于除了ELK方案以外,在分布式日志管理上,我们还有很多其他的选择。近年来随着大数据的发展,海量数据采集组件Flume也开始广泛应用于分布式日志解决方案中。因为没有太多日志分析需求,我的团队采用了更轻量级的方案:Loki promtail grafana,建立类似Prometheus的日志监控系统,promtail负责收集日志,Loki负责存储,grafana负责展示。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/23454.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
新闻类网站设计的五个要素
新闻类网站设计主要为以下五方面: 战略层设计。体现在两方面:一是用户核心需求分析,二是网站商业目标等。 范围层设计。体现在内容需求和实现内容的功能方式上。具体讲是指从新闻事件的核心…
-
Android App开发现在学Kotlin好还是Flutter好?
如果想要进行单纯的Android 平台App开发,建议先学习Kotlin(Kotlin是Google Android开发的官方语言);后面如果考虑构建跨平台应用,可以使用Flutt…
-
常见Web安全攻防总结
Web 安全地对于 Web 从业人员来说是一个非常重要的课题,所以在这里总结一下 Web 相关的安全攻防知识,希望以后不要再踩雷,也希望对看到这篇文章的同学有所帮助。今天这边文章主…
-
Google基于Flutter的Windows 10的UWP应用界面首曝
Flutter跨平台UI框架是GitHub上增长最快的语言之一,它适用于移动应用、Web应用甚至桌面应用。谷歌在2018年12月首次宣布Flutter用于移动平台,然后将框架扩展到…
-
简述五种开源NAS存储服务器
存储对于公司来说是必不可少的:数据必须被存储、检索、共享和保护。而且,存储不会占用您的全部IT预算。所幸的是,您将在开源世界中找到许多有效的NAS存储服务器解决方案。除了具有成本效…
-
B2B 和 B2C 网站设计有什么核心差异?
B2B 和 B2C 的生意是截然不同的。在产品设计上,有些设计原则是通用的,比如都需要清晰明了的信息架构、简洁易懂的交互界面等等。但同时,两者也存在许多差异。 前段时间,我们团队针…
-
探索浏览器的内幕:JavaScript内部原理分析
简介 Javascript 是一种奇怪语言,有些人喜欢它,有些人讨厌它。它有许多独特的机制,这些机制在其他流行语言中不存在,也没有对应的机制,还有突出明显的就是代码的执行顺序 了解…
-
PowerToys0.29更新发布:优化用户体验、稳定性等
适用于 Windows 的 PowerToys 0.29 更新于今天正式发布。本次更新重点优化了用户体验、稳定性、可访问性,本地化和质量上。由于本月是圣诞假期,因此开发周期比较短,…
-
Flash停止支持,偶尔要访问的老网站怎么办?
经过长达三年的过渡后,Adobe 终于在 2020 年的最后一天正式结束了对 Flash 技术的支持。此番 Adobe 还联合了多个浏览器开发商以及操作系统巨头,誓要从技术手段和使…
-
Web框架基础之WSGI协议
本篇文章我们主要介绍WSGI协议,该协议用来描述Server与Framework之间的通信接口,我们日常使用的Python WEB框架Django、Flask、web.py等都遵循…