前言
前段时间,因为项目需求,需要根据关键词搜索聊天记录,这不就是一个搜索引擎的功能吗? 于是我第一时间想到的就是 ElasticSearch 分布式搜索引擎,但是由于一些原因,公司的服务器资源比较紧张,没有额外的机器去部署一套 ElasticSearch 服务,而且上线时间也比较紧张,数据量也不大,然后就想到了 Mysql 的全文索引。
简介
其实 Mysql 很早就支持全文索引了,只不过一直只支持英文的检索,从5.7.6 版本开始,Mysql 就内置了 ngram 全文解析器,用来支持中文、日文、韩文分词。
Mysql 全文索引采用的是倒排索引的原理,在倒排索引中关键词是主键,每个关键词都对应着一系列文件,这些文件中都出现了这个关键词。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
本文测试,基于 Mysql 8.0 版本,数据库引擎采用的是 InnoDB
ngram 全文解析器
ngram 就是一段文字里面连续的 n 个字的序列。ngram 全文解析器能够对文本进行分词,每个单词是连续的 n 个字的序列。例如,用 ngram 全文解析器对“你好靓仔”进行分词:
n=1: '你', '好', '靓', '仔'
n=2: '你好', '好靓', '靓仔'
n=3: '你好靓', '好靓仔'
n=4: '你好靓仔'MySQL 中使用全局变量 ngram_token_size来配置 ngram 中 n 的大小,它的取值范围是1到10,默认值是 2。通常 ngram_token_size 设置为要查询的单词的最小字数。如果需要搜索单字,就要把 ngram_token_size 设置为 1。在默认值是 2 的情况下,搜索单字是得不到任何结果的。因为中文单词最少是两个汉字,推荐使用默认值 2。
可以通过以下命令查看 Mysql 默认的 ngram_token_size 大小:
show variables like 'ngram_token_size'

有两种方式可以设置全局变量 ngram_token_size 的值:
1、启动 mysqld 命令时指定:
mysqld --ngram_token_size=22、修改 Mysql 配置文件 my.ini,末尾增加一行参数:
ngram_token_size=2创建全文索引
1、建表时创建全文索引
CREATE TABLE `article` (
`id` bigint NOT NULL,
`url` varchar(1024) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`title` varchar(256) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`source` varchar(32) COLLATE utf8mb4_general_ci DEFAULT '',
`keywords` varchar(32) COLLATE utf8mb4_general_ci DEFAULT NULL,
`publish_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `title_index` (`title`) WITH PARSER `ngram`
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;2、通过 alter table 方式
ALTER TABLE article ADD FULLTEXT INDEX title_index(title) WITH PARSER ngram;3、通过 create index 方式
CREATE FULLTEXT INDEX title_index ON article (title) WITH PARSER ngram;检索方式
1、自然语言检索(NATURAL LANGUAGE MODE)
自然语言模式是 MySQL 默认的全文检索模式。自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。
示例
select * from article where MATCH(title) AGAINST ('北京旅游' IN NATURAL LANGUAGE MODE);
// 不指定模式,默认使用自然语言模式
select * from article where MATCH(title) AGAINST ('北京旅游');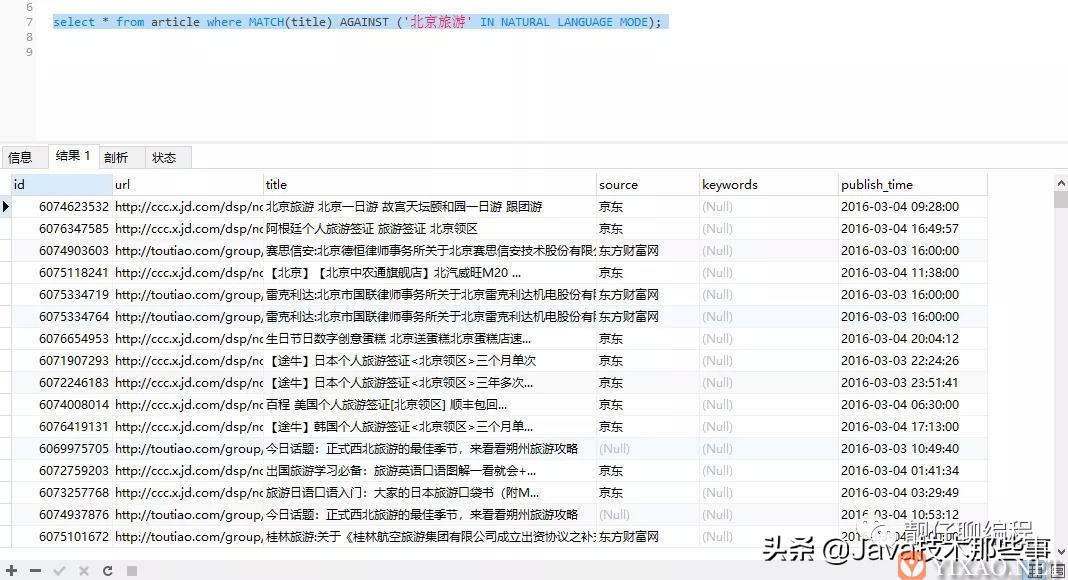
可以看出,该模式下根据“北京旅游”搜索,可以搜索出包含“北京”的或者包含“旅游”的内容,因为它是根据自然语言分成了两个关键词。
上面示例中返回的结果会自动按照匹配度排序,匹配度高的在前面,匹配度是一个非负浮点数。
示例
// 查看匹配度
select * , MATCH(title) AGAINST ('北京旅游') as score from article where MATCH(title) AGAINST ('北京旅游' IN NATURAL LANGUAGE MODE);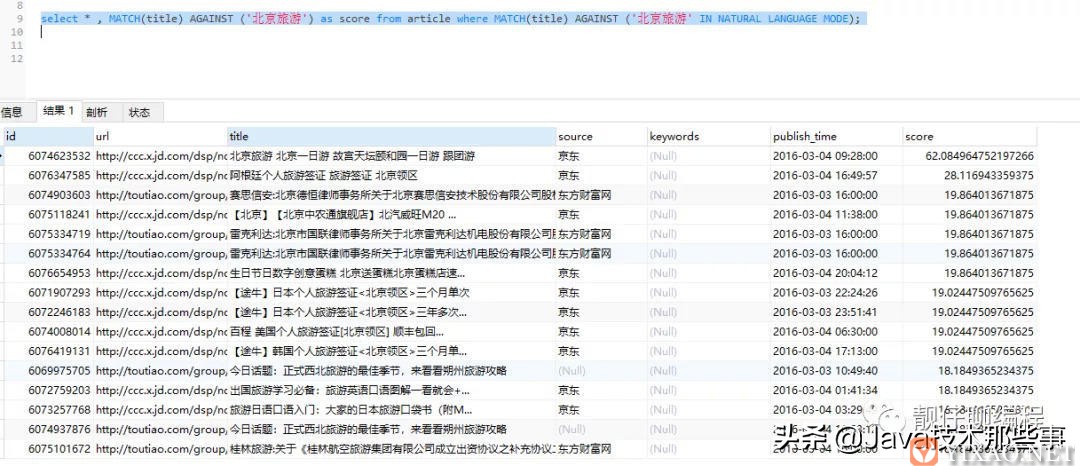
2、布尔检索(BOOLEAN MODE)
布尔检索模式可以使用操作符,可以支持指定关键词必须出现或者必须不能出现或者关键词的权重高还是低等复杂查询。
示例
// 无操作符
// 包含“约会”或“攻略”
select * from article where MATCH(title) AGAINST ('约会 攻略' IN BOOLEAN MODE);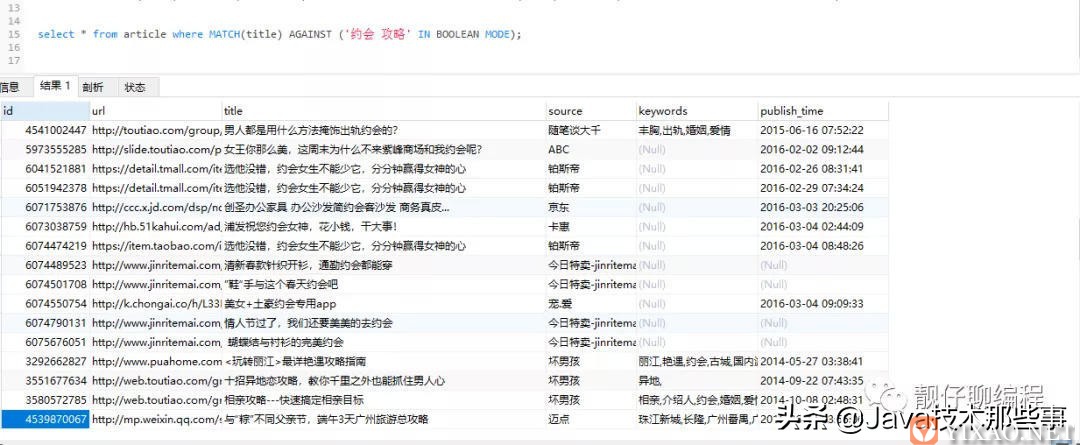
// 使用操作符// 必须包含“约会”,可包含“攻略”select * from article where MATCH(title) AGAINST ('+约会 攻略' IN BOOLEAN MODE);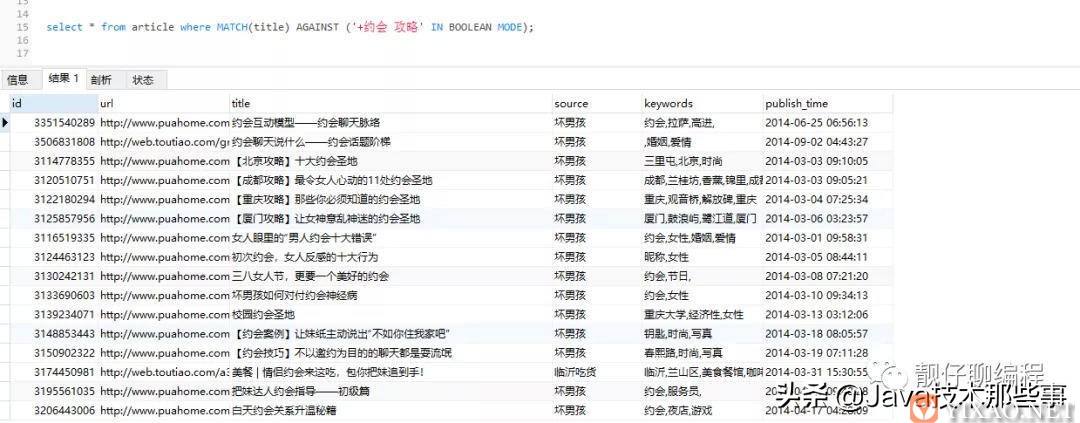
更多操作符示例:
'约会 攻略'
无操作符,表示或,要么包含“约会”,要么包含“攻略”
'+约会 +攻略'
必须同时包含两个词
'+约会 攻略'
必须包含“约会”,但是如果也包含“攻略”的话,匹配度更高。
'+约会 -攻略'
必须包含“约会”,同时不能包含“攻略”。
'+约会 ~攻略'
必须包含“约会”,但是如果也包含“攻略”的话,匹配度要比不包含“攻略”的记录低。
'+约会 +(>攻略 <技巧)'
查询必须包含“约会”和“攻略”或者“约会”和“技巧”的记录,但是“约会 攻略”的匹配度要比“约会 技巧”高。
'约会*'
查询包含以“约会”开头的记录。
'"约会攻略"'
使用双引号把要搜素的词括起来,效果类似于like '%约会攻略%',
例如“约会攻略初级篇”会被匹配到,而“约会的攻略”就不会被匹配。与 Like 对比
全文索引和 like 查询对比,有以下优点:
- like 只是进行模糊匹配,全文索引却提供了一些语法语义的查询功能,会将要查的字符串进行分词操作,这决定于 Mysql 的词库。
- 全文索引可以自己设置词语的最小、最大长度,要忽略的词,这些都是可以设置的。
- 用全文索引去某个列查一个字符串,会返回匹配度,可以理解为匹配的关键字个数,是个浮点数。
而且全文检索的性能也是优于 like 查询的
以下是以 50w 左右数据进行的测试:
// like 查询
select * from article where title like '%北京%';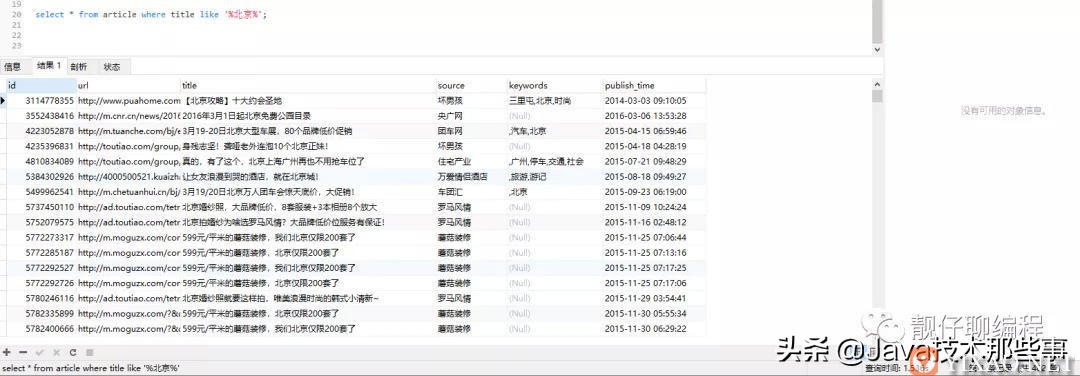
// 全文索引查询select * from article where MATCH(title) AGAINST ('北京' IN BOOLEAN MODE);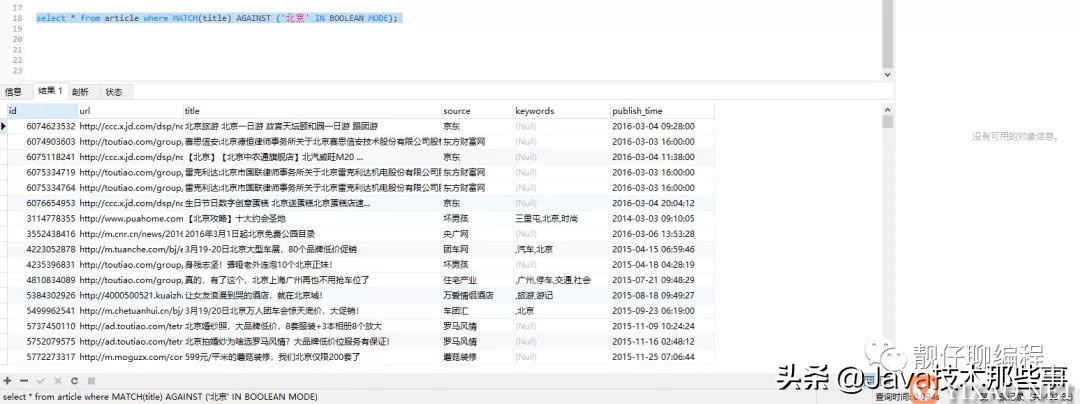
可以看出 like 查询是 1.536s,全文索引查询是 0.094s,快了16倍左右。
总结
全文索引能快速搜索,但是也存在维护索引的开销。字段长度越大,创建的全文索引也越大,会影响DML语句的吞吐量。数据量不大的情况下可以采用全文索引来做搜索,简单方便,但是数据量大的话还是建议用专门的搜索引擎 ElasticSearch 来做这件事。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/28158.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
Google Chrome标签页组自动创建功能现已推出
随着Google Chrome 87的推出,一些在测试中的功能现在已经可以向普通用户提供,包括新的标签组功能。谷歌在5月份向普通Chrome用户推出了标签组特性,但估计大多数用户甚…
-
SpringBoot+Mysql疫情核酸检测统计管理系统源码+讲解教程+文档
今天给大家介绍的的是由一个基于springboot脚手架的疫情核酸监测统计管理系统,涉及的知识点有:springboot框架原理、freemark模板标签语法、jpa数据库操作及自…
-
KindEditor上传图片弹出白屏的无反应问题的解决方法
KindEditor是一款非常不错的富文本编辑器,可是这两年常有客户反馈上传图片有问题,不显示选择图片的弹出,也不显示关闭的按钮, 只有空白背景,重复刷新也无效。 这个bug我们一…
-
Spring Boot 2.3.8 发布
Spring Boot 2.3.8 已发布,此版本更新内容包括 35 个 bug 修复和依赖项升级。 具体更新内容如下: Bug Fixes 1、Default servlet l…
-
如何开启MacOS11系统的自带的PHP环境
我们都知道MacOS系统内置了Apahce服务,而且还内置php环境,今天在这里教大家如何开启apache服务和php环境! 开启apache服务的方法 打开终端,在终端里输入&#…
-
Chrome浏览器今天正式更新了87版本
Chrome浏览器今天正式更新了87版本,这是一次史无前例的大升级,看来真的被Edge逼急了 感谢微软让我们用上更好的Chrome。 1,非活动标签冻结,不再频繁唤醒。CPU占用率…
-
谷歌提出新的字体调用方案帮助提高中文字体的加载速度
谷歌旗下的网页字体调用Google Fonts API旨在帮助用户加载不同网站时复用资源达到提高加速速度的目的。目前该公司提出了新的解决方案用来提高中文字体的加载速度, 该方案主要…
-
MYSQL5.7安装教程
前置工作-更换yum源 1)打开 mirrors.aliyun.com,选择centos的系统,点击帮助 2)执行命令:yum install wget -y 3)改变某些文件的名…
-
中国Corda网络(CCN)正式上线发布
2021年7月31日,由R3与BSN共同建立的中国Corda网络(China Corda Network,简称:CCN)正式上线发布。CCN旨在通过为我国打造一个国际广泛认可的金融…