摘要:目前,物联网、工业互联网、车联网等智能互联技术在各个行业场景下快速普及应用,导致联网传感器、智能设备数量急剧增加,随之而来的海量时序监控数据存储、处理问题,也为时序数据库高效压缩、存储数据能力提出了更高的要求。对于通量愈加庞大的物联网时序大数据存储,尽管标准压缩方法还能发挥其价值,但某些场景对时序数据压缩解压技术效率、性能提出了新的需求。本文介绍了现有的时序数据压缩解压技术,分类介绍了不同算法的特点和优劣势。
时序数据普遍存在于IoT物联网、工业互联网、车联网等相关场景,物联网设备已遍布各种行业场景应用,从可穿戴设备到工业生产设备,都会或将会产生大量数据。比如,新型波音787客机每次飞行传感器产生的数据量都在500GB左右。在这些场景下,通常具备高并发写和高通量数据处理特点,选择时序数据压缩算法需要全方位考虑数据采集、存储、分析的需要。特别需要注意的是业务应用对时序数据当前和历史数据分析的方式,选择压缩算法不当将可能导致关键信息丢失,从而影响分析结果。对于业务来说,更直接使用时序数据压缩技术的应用就是时序数据库,对于时序数据库压缩解压是关键数据处理步骤,压缩算法性能直接影响时序数据库建设投入的ROI。
一 时序数据压缩
对于数据压缩算法,业界存在更普遍的解释,通常是针对通用场景和业务相关场景,比如视频、音频、图像数据流压缩。本文重点介绍时序数据库中常用的面向时序数据设计或可用于时序数据处理的通用压缩算法。我们选择分析的算法具备对更普遍场景下持续产生时序数据压缩处理的能力,并对IoT物联网场景传感器数据压缩的以下特点做了特殊设计:
1、数据冗余(Redundancy):一些特定模式的时序数据经常性重复出现在一个或多个时间序列。
2、函数估算(Approximability):某些传感器产生的时序数据生成模式可以根据预定义函数估算。
3、趋势预测(Predictability):某些时序数据未来趋势可以通过算法预测,例如利用回归、深度神经网络等技术。
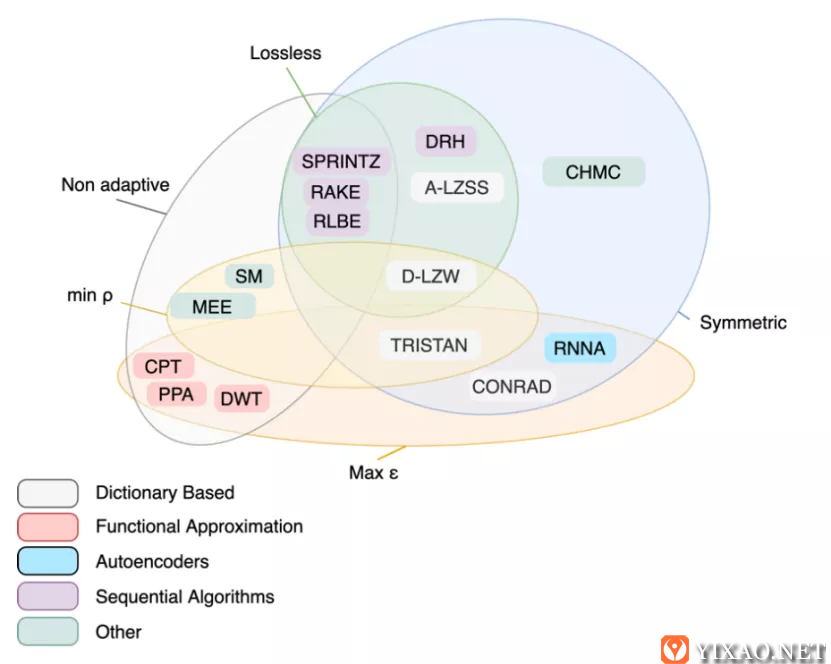

图 时序数据压缩算法分类
本文重点总结了时序数据库和物联网IoT传感器管理常用压缩算法,并根据技术方法(dictionary-based, functional approximation, autoencoders, sequential等)和技术属性(adaptiveness, lossless reconstruction, symmetry, tuneability)对碎片化的压缩技术进行了分类,详细参考上图,并针对主要算法性能进行了对比分析。
二 背景技术介绍
在介绍压缩算法之前,我们先对时序数据、压缩和品质指数(quality indices)几个关键的概念进行定义。
1 时序数据(Time Series)
时序数据指数据元组根据时间戳(ti)升序排列的数据集合,可以被划分为:
1、单变量时序(Univariate Time Series,UTS):每次采集的数据元组集合为单个实数变量。
2、多变量时序(Multivariate Time Series ,MTS):每次采集的数据元组集合由多个实数序列组成,每个组成部分对映时序一个特征。
比如,图2中股票价格在指定时间窗口的波动可以被定义为单变量时序数据,而每天交易信息(如:开盘、收盘价格,交易量等)则可以定义为多变量时序数据。
图 股票交易UTS时序数据样例
用数学范式表达时序可以被定义为:
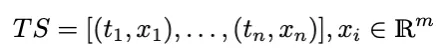
2 数据压缩
数据压缩(又被称为源编码,source coding),根据David Salmon在《Data Compression: The Complete Reference》一书中的定义,可以简单描述为“将输入原始数据流转变为字符流(bit stream)或压缩流的体量更小的输出数据流的过程”。这个过程遵循J. G.Wolff提出的Simplicity Power(SP)理论,旨在尽量保持数据信息的前提下去除数据冗余。
数据解压缩(又被称为源解码,source decoding),执行与压缩相反过程重构数据流以适应更高效数据应用层对数据表述、理解的需要。
现有压缩算法根据实现原理的差异,可以被划分为以下几类:
- 非适应/自适应(Non-adaptive/ adaptive):非适应算法不需要针对特殊数据流进行训练以提升效率,而适应算法则需要有训练过程。
- 松散/非松散(Lossy/Lossless):松散算法不保障对原始数据压缩后的结果唯一,而非松散算法对同样原始数据的压缩结果唯一。
- 对称/非对称(Symmetric/Asymmetric):对称算法对数据的压缩、解压缩使用相同的算法实现,通过执行不同的代码路径切换压缩解压缩过程;非对称算法则在数据压缩、解压缩过程分别使用不同的算法。
对于具体的时序数据流压缩解压缩过程,一个压缩算法实例(encoder)输入s体量的时序数据流TS,返回压缩后的体量s′的时序数据流TS′,且s>s′包含一同压缩的时间戳字段E(TS) = TS′。解压缩算法实例(decoder)的执行过程则是从压缩数据流还源原始的时序数据流D(TS′) = TS,若TS = TSs则压缩算法是非松散的,否则就是松散的。
3 品质指数(quality indices)
为了度量时序数据压缩算法的性能,通常需要考虑三点特性:压缩率、压缩速度、精确度。
1、压缩率:衡量压缩算法对原始时序数据压缩比率,可以定义为:
ρ=s’s
其中,s′代表时序数据压缩后的体量,s为时序数据压缩前的原始体量。ρ的转置又被称为压缩因数,而品质指数(quality indices)则是被用来表述压缩收益的指标,其定义为:
cg=100loge1ρ
2、速度:度量压缩算法执行速度,通常用每字节压缩周期的平均执行时间(Cycles Per Byte,CPB)。
3、精确度:又被称为失真度量(Distortion Criteria,DC),衡量被压缩算法重构后的时序数据保留信息可信度。为适应不同场景度量需要,可以用多种度量指标来确定,常用的指标有:
Mean Squared Error:
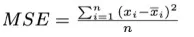
Root Mean Squared Error:
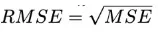
Signal to Noise Ratio:
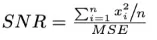
Peak Signal to Noise Ratio:
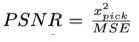
三 压缩算法
目前常用的时序数据压缩算法主要有以下几种:
1) Dictionary-Based (DB)
1.1. TRISTAN
1.2. CONRAD
1.3. A-LZSS
1.4. D-LZW
2) Functional Approximation (FA)
2.1. Piecewise Polynomial Approximation (PPA)
2.2. Chebyshev Polynomial Transform (CPT)
2.3. Discrete Wavelet Transform (DWT)
3) Autoencoders:
3.1. Recurrent Neural Network Autoencoder (RNNA)
4) Sequential Algorithms (SA)
4.1. Delta encoding, Run-length and Huffman (DRH)
4.2. Sprintz
4.3. Run-Length Binary Encoding (RLBE)
4.4. RAKE
5) Others:
5.1. Major Extrema Extractor (MEE)
5.2. Segment Merging (SM)
5.3. Continuous Hidden Markov Chain (CHMC)
1 Dictionary-Based (DB)
DB算法实现理念是通过识别时序数据都存在的相同片段,并将片段定义为原子片段并以更精简的标识标记替代,形成字典供使用时以标识作为Key恢复,这种方式能够在保证较高数据压缩比的同时,降低错误率。此技术实现的压缩可能是无损的,具体取决于实现情况。此架构的主要挑战是:
- 最大限度地提高搜索速度,以便在字典中查找时间系列片段;
- 使存储在 dictionary 中的时间串段尽可能一般,以最大限度地缩短压缩阶段的距离。
TRISTAN是基于DB策略实现的一种算法,TRISTAN算法把压缩划分为两个阶段处理,第一阶段适应性学习,第二阶段数据压缩。在学习阶段,TRISTAN字典表通过学习训练数据集来生成,或者结合专家经验定义特定模式的原子片段。有了字典表,在压缩阶段TRISTAN算法执行从以下公式中检索w的过程。
s=w·D w ∈ {0,1}k
其中,D是字典表,s为原子片段,K是压缩后的时序表征数据长度。TRISTAN解压过程则是通字典表D解释表征数据w得到原始时序数据的过程。
CORAD算法在TRISTAN基础之上增加了自动数据关联信息,对两两时序数据片断进行基于Pearson相关系数的度量,以相邻矩阵M存储相关性,通过M与字典表D相结合的计算方式,进一步提升压缩比和数据解压精确度。
Accelerometer LZSS(A-LZSS)算法是基于LZSS搜索匹配算法的DB策略实现,A-LZSS算法使用Huffman编码,以离线方式通过统计数据概率分布生成。
Differential LZW (D-LZW)算法核心思想是创建一个非常大的字典表,它会随着时间的推移而增长。一旦字典表被创建,如果在字典表中发现缓冲区块,它就会被相应的索引替换,否则,新方块将插入字典作为新的条目。增加新的缓存区块是在保证非松散压缩的原则下实现,并不限制增加的数量,但随之而来的问题就是字典表有可能无限膨胀,这就导致D-LZW算法只适用于特定场景,比如输入时序数据流为有限词组或可枚举字符集组成。
Zstandard(zstd)是一种基于Huffman编码Entropy coder实现的快速非松散DB压缩算法,字典表作为一个可选选项支撑参数控制开启关闭。算法实现由Facebook开源,支持压缩速度与压缩比之间的按需调整,能够通过牺牲压缩速度来换取更高压缩比,反之亦然。相比同类算法,zstd算法性能可参考下表数据。
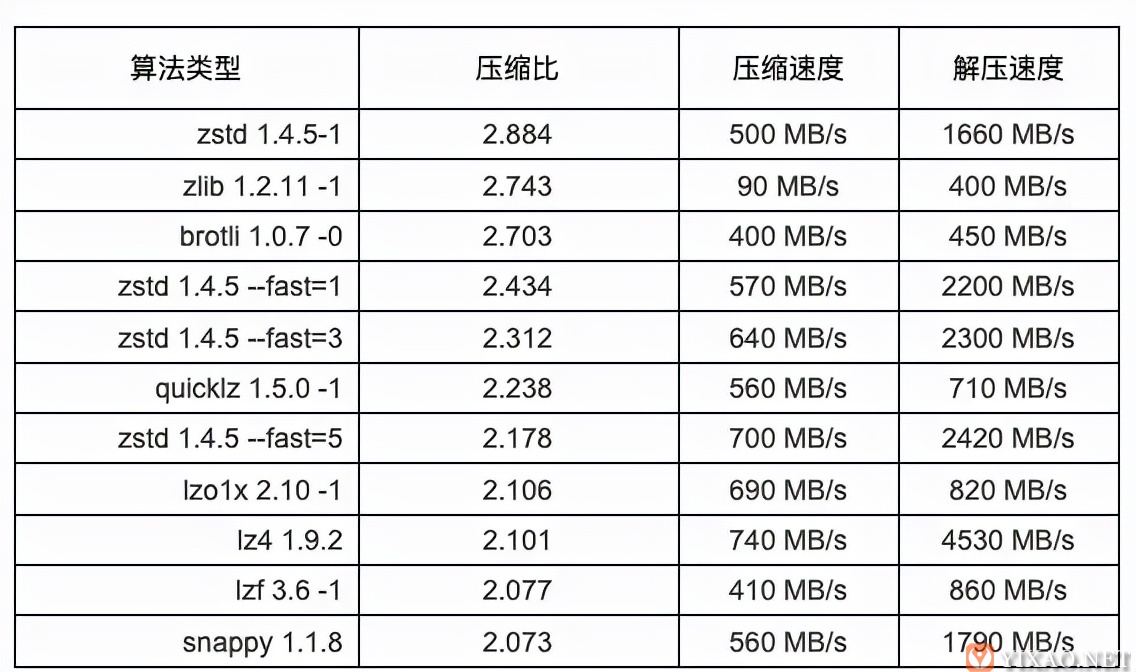
表 zstd算法性能对比
2 Function Approximation (FA)
函数近似类时序压缩算法FA的主要设计思想是假设时间序列可以表示为时间函数。由于难以避免出现无法处理的新值,找出能够准确描述整个时间序列的函数是不可行的,因此我们可以将时间序列划分成多个片段,对每个段找到一个近似时间函数来描述。
由于找到一个能完整描述时间序列的函数 f:T → X 是不可行的,因此实现上我们需要考虑找出一个函数簇,以及其对映的参数来描述分段时序数据相对可行,但这也使得压缩算法为松散的实现。
相比之下,FA类算法优点是它不依赖于数据取值范围,因此不需要有基于样本数据集的训练阶段,如果采用回归算法,我们只需要单独考虑划分好的单个时间片段。
Piecewise Polynomial Approximation (PPA)是FA类算法的常用实现,此技术将时间序列分为固定长度或可变长度的多个段,并尝试找到接近细分的最佳多项式表述。尽管压缩是有损的,但可以先于原始数据的最大偏差进行修复,以实现给定的重建精度。PPA算法应用贪婪的方法和三种不同的在线回归算法来近似恒定的函数、直线和多项式。
Chebyshev Polynomial Transform (CPT)实现原理与PPA算法类似,只是改进了支持使用不同类型多项式的能力。Discrete Wavelet Transform (DWT)使用Wavelet小波转换对时序数据进行转换。Wavelet是描述起止值都为0,中间值在此之间波动的函数,
3 Autoencoders
Autoencoder是一种特殊的神经网络,被训练生成用来处理时序数据。算法架构由对称的两部分组成:编码器encoder和解码器decoder。在给定n维时序数据输入的前提下,Autoencoder的编码器输出m(m<n)维的输出。解码器decoder则可以将m维输出还原为n维输入。Recurrent Neural Network Autoencoder (RNNA)是Autoencoder的一种典型实现,通过RNN来实现对时序数据的压缩表述。
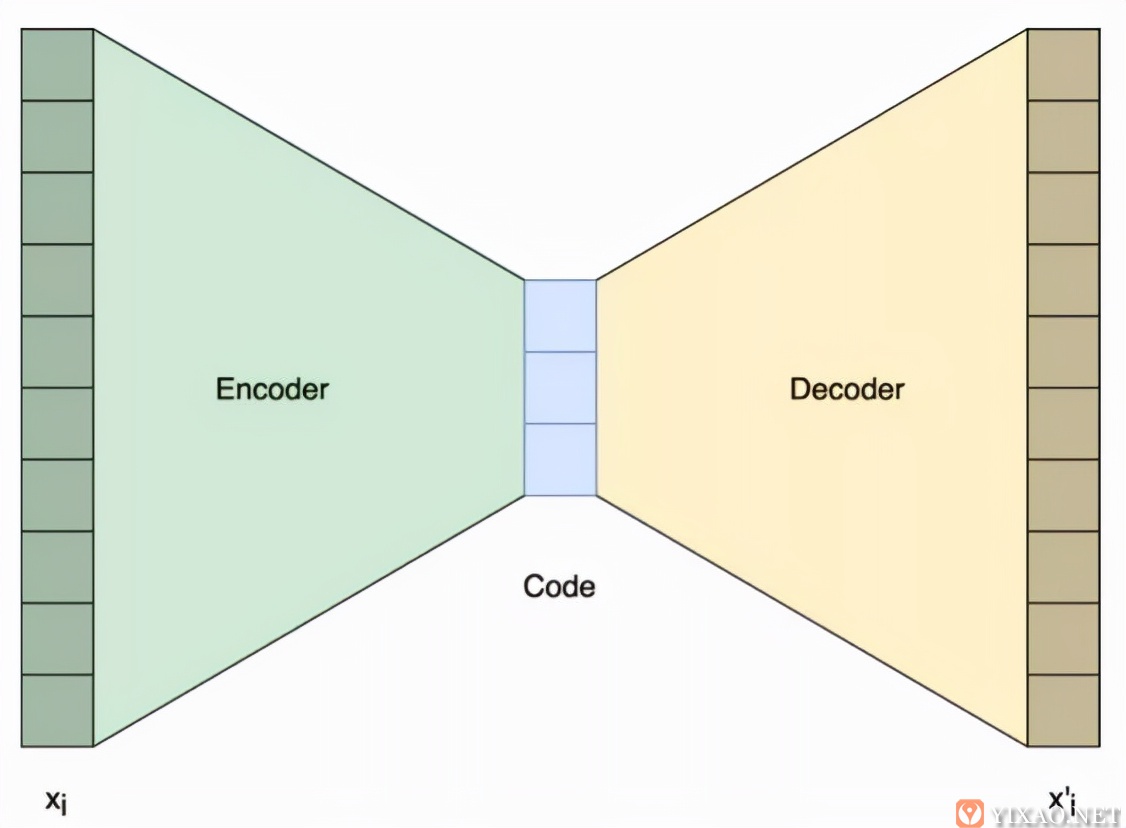
图 Autoencoder算法实现结构
4 序列化算法Sequential Algorithms(SA)
序列化算法SA实现原理是顺序融合多种简单压缩技术实现对时序数据压缩,常用技术有:
- Huffman coding:编码器创建一个字典,将每个符号关联到二进制表示,并以相应的表示替换原始数据的每个符号。
- Delta encoding:此技术对目标文件进行编码,以处理一个或多个参考文件。在时间系列的特定情况下,每个元素在 t 被编码为∆(xt,xt=1)。
- Run-length encoding:在此技术中,每个运行(连续重复相同值的序列)都与对(vt, o)进行子图,其中vt是时间t值,o是连续发生次数。
- Fibonacci binary encoding:此编码技术基于 Fibonacci 序列实现。
Delta encoding, Run-length and Huffman (DRH)算法是一种融合了Delta encoding、Huffman coding、Run-length encoding和Huffman coding四种技术的压缩算法,算法实现是非松散的且计算复杂度相对较小,适合在边缘短实现对数据的压缩解压,也因此适合应用在物联网、工业互联网、车联网等需要边缘短采集处理时序数据的场景。
Sprintz就是一种专门针对物联网场景设计的SA算法,在算法设计中考虑了对物联网场景中能源消耗、速度等时序指标波动规律因素,为以下需求而特别优化了算法设计:
1)对较小片段数据的快速处理
2)底计算复杂度的压缩、解压缩,以适应边缘端有限的计算资源
3)对实时采集时序数据的快速压缩、解压缩
4)非松散压缩
为了在处理IoT物联网环境时序数据上取得更好的压缩效果,Sprintz算法通过预测数据生成趋势的方式来提升算法对数据的压缩性能,其主要实现的算法过程包括以下几部分:
1)预测:基于delta encoding或FIRE算法通过统计历史时序数据,对新样本数据生成规律进行预测;
2)Bit packing:打包预测错误信息数据和包头描述用来解压数据的信息;
3)Run-length encoding:如果压缩过程中通过预测算法未发现任何错误信息,则略过bit packing过程的错误信息发送,并在下次发生错误时在打包预测错误信息的包头中记录略过的数据长度;
4)Entropy coding:用Huffman coding对big packing生成的包文件进行编码。
Run-Length Binary Encoding (RLBE)算法 也是一种为IoT物联网场景下数据压缩解压,适应物联网边缘端有限计算、存储资源环境的常用非松散SA时序数据压缩算法,RLBE算法融合了delta encoding,run-length encoding和Fibonacci coding三种技术,其执行过程如下图所示。
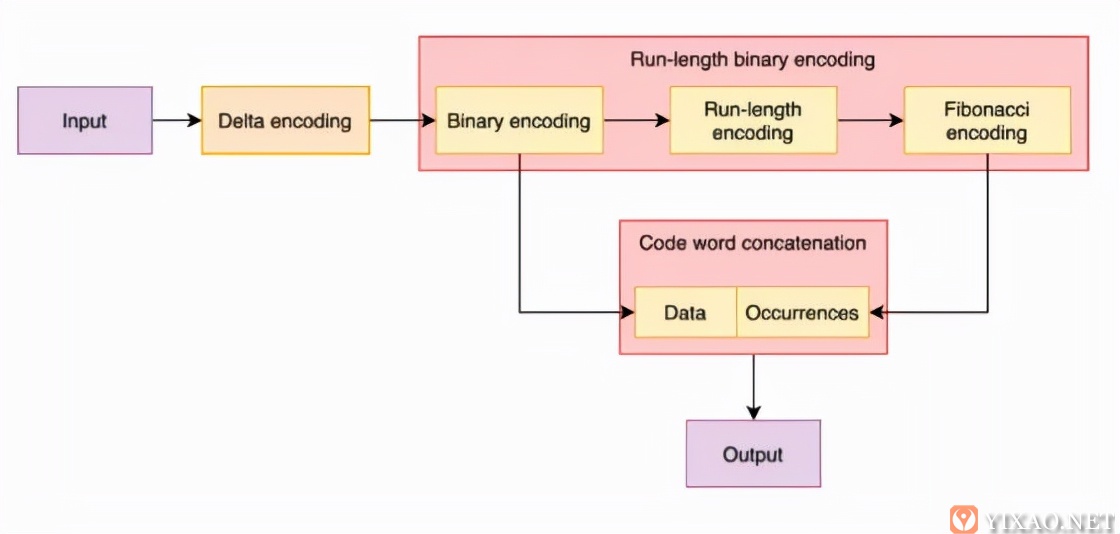
图 Run-Length Binary Encoding (RLBE)算法执行过程图示
RAKE算法原理是通过检测时序数据稀疏性来实现对数据的压缩。RAKE为非松散压缩,执行过程包涵预处理和压缩两个主要过程。预处理过程中,RAKE算法设计由字典表来转换原始数据。压缩过程则对预处理的输出数据进行稀疏性检测,压缩相邻的相同数据。
5 其他类型算法
Major Extrema Extractor (MEE)算法通过统计指定时间段的时序数据最大、最小值来对数据进行压缩。Segment Merging (SM)算法则把时序数据抽象为时间戳和值及偏差组成的片段,可用元组(t,y,δ)表述,其中t为开始时间,y是数值常量标识,δ是数据片段偏差。Continuous Hidden Markov Chain (CHMC)算法则利用马尔可夫链概率模型来将时序数据定义为一系列有限状态节点集合S及链接节点的状态迁移概率边集合A。
四 总结
时序数据是物联网、工业互联网、车联网等场景下生成数据总量中占比最高的数据类型,有效的压缩算法不但可以降低数据存储成本,同时可以在边缘到中心,中心到云的数据传输过程中节约网带宽资源,降低数据同步时间。对于作为时序数据核心存储中枢的时序数据库,压缩算法性能更是至关重要。阿里云多模数据库Lindorm核心数据库引擎之一时序引擎Lindorm TSDB内置的自研、高效数据压缩算法针对物联网、工业互联网、车联网等智能、互联场景针对性优化,进一步提升了时序数据存储的ROI,新一代云原生智能互联系统提供必要支撑。
作者 | 仁威
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/29540.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
微软Outlook的新功能可以缩短企业会议时间并加入休息时间
几十年来,像Outlook这样的日历软件一直默认为按小时开会,往往在无意中出现了车轮战开会的现象,其默认设置没有考虑中间休息的需要。因众多且冗长的线上会议,特别是背靠背的连续会议会…
-
测试服务器回程ping的小脚本 mPing
我们测试服务器延迟的时候有时会用17ce或者奇云测的多地ping工具,但是服务器回程到各地的延迟怎么样呢?一个个ping太麻烦了,用这个xiaoz分享的脚本就很方便。脚本里包含了一…
-
WSLg–微软官方内置,在Win 10上一键安装5大Linux发行版本
WSLg – 微软官方内置,在 Win 10 上一键安装 5 大 Linux 发行版本 WSLg(Windows Subsystem for Linux GUI)是微软官方 5 天…
-
Visual Studio Code 前端快速格式化设置
传统的Visual Studio Code自带的代码格式化,通过鼠标或者ctrl+a选中全部(或者部分),然后鼠标右键,在其中选择Format Document(或者Format Selection),进行前端代码的格式化,每次写完如果未严格按照代码规范注意格式就需要手动进行格式化。
-
同一服务器(VPS)IP下多站点多域名HTTPS实现
假设有这样一个场景,我们有多个站点(例如site1.yixao.net,site2.yixao.net和site3.yixao.net)绑定到同一个IP:PORT,并区分不同的主机…
-
修复Windows10更新导致打印蓝屏问题的解决方案
3 月 9 日的补丁星期二活动日上,微软面向尚处于支持状态的 Windows 10 发布了累积更新。其中,Windows 10 20H1/20H2 功能更新获得 KB5000802…
-
Google将放弃在 iOS 上使用Material Design
负责 Google 产品在苹果平台版本界面设计的首席工程师 Jeff Verkoeyen 在 Twitter 表示,Google 将从今年开始逐步放弃在 iOS 平台使用 Mate…
-
使用curl从命令行访问互联网
要在不使用图形界面的情况下从互联网上获取所需的信息,curl 是一种快速有效的方法。 • 来源:linux.cn • 作者:Seth Kenlon • 译者:MjSeven • (…
-
初识Vitess分库分表
Vitess,作为海外最为知名的分库分表产品,一直以来在国内声音不多。近期抽空了解下这个产品,特分享出来。本文部分内容取自Vitess官网https://vitess.io。 1….
-
微信8.0状态背景图怎么设置 微信状态背景图更改教程
微信状态背景图这个新功能,不少玩家都不清楚该如何设置,那么详细的操作方法是什么,下面为大家介绍微信状态背景图更改教。 微信状态背景图更改教程 1、打开8.0版本的微信,“我”界面点…