为什么要做网络爬虫?
首先请问:都说现在是”大数据时代”,那数据从何而来?
企业产生的用户数据:百度指数、阿里指数、TBI腾讯浏览指数、新浪微博指数
数据平台购买数据:数据堂、国云数据市场、贵阳大数据交易所
政府/机构公开的数据:中华人民共和国国家统计局数据、世界银行公开数据、联合国数据、纳斯达克。
数据管理咨询公司:麦肯锡、埃森哲、艾瑞咨询
爬取网络数据:如果需要的数据市场上没有,或者不愿意购买,那么可以选择招/做一名爬虫工程师,自己动手丰衣足食。拉勾网Python爬虫职位
网络爬虫是什么?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫的更多用途
12306抢票
网站上的头票
短信轰炸
关于Python网络爬虫,我们需要学习的有:
- Python基础语法学习(基础知识)
- 对HTML页面的内容抓取(数据抓取)
- 对HTML页面的数据提取(数据提取)
- Scrapy框架以及scrapy-redis分布式策略(第三方框架)
- 爬虫(Spider)、反爬虫(Anti-Spider)、反反爬虫(Anti-Anti-Spider)之间的斗争…
通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.
通用爬虫
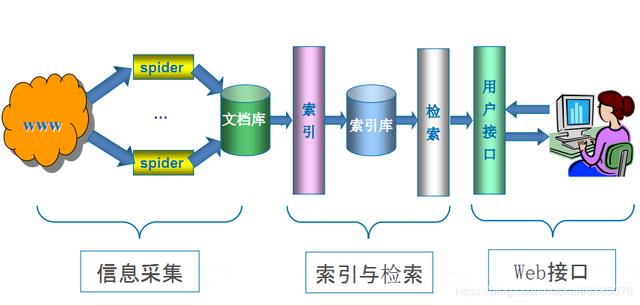
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
通用搜索引擎(Search Engine)工作原理
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
第一步:抓取网页
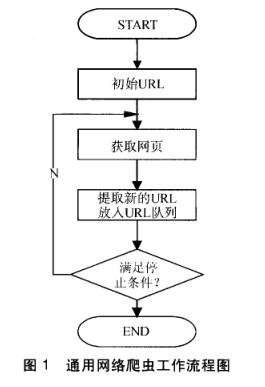
搜索引擎网络爬虫的基本工作流程如下:
首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环…

搜索引擎如何获取一个新网站的URL:
- 新网站向搜索引擎主动提交网址:(如百度http://zhanzhang.baidu.com/linksubmit/url)
- 在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
- 搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
- 但是搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容,如标注为nofollow的链接,或者是Robots协议。
Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
提取文字
中文分词
消除噪音(比如版权声明文字、导航条、广告等……)
索引处理
链接关系计算
特殊文件处理
…
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时会根据页面的PageRank值(链接的访问量排名)来进行网站排名,这样Rank值高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。
但是,这些通用性搜索引擎也存在着一定的局限性:
通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
针对这些情况,聚焦爬虫技术得以广泛使用。
聚焦爬虫
聚焦爬虫,是”面向特定主题需求”的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
而我们今后要学习的网络爬虫,就是聚焦爬虫。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/7645.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
借助Code Server将iPad Pro变为程序员的编码利器,用iPad Pro写代码
iPad Pro性能强大,配上妙控键盘更是如虎添翼。那我们怎么能让它称为程序员的生产力呢,下面我们通过本文将iPad Pro变为程序员的编码利器。 我们通过借助在一台电脑上安装Co…
-
免费工具帮你检测VPS服务器的真伪:VPS主机性能和速度测试方法
这年头VPS主机太多了,好多“二手”VPS开始横行其道,让人真假莫辨,想要购买某一个VPS主机,一般是先要看看这家的VPS主机的评测数据。之前分享VPS主机时都会给出VPS的性能与…
-
淘宝禁售VPS类商品,或因政策所致
不得不说今年国内互联网变化太大了,艾斯艾斯R被搞,苹果下架一些网络应用,国内网站需要双备案,国内域名注册商注册域名必须实名等,关键词数量大大增多,现在连VPS都危险了。据开网店的网…
-
Node.js 15.6.0 发布
Node.js 15.6.0 发布,Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时。 此版本主要更新内容包括: 一、child_process…
-
JavaScript已经到了悲剧时代
JavaScript 在过去几十年中的发展中,语言本身没有太多变化,但是使用方式上发生了翻天覆地的变化,简单归纳起来有这么三个阶段。 以 Dojo(1.x),Mootools,Ex…
-
如何使用LinkedInDumper并通过LinkedIn API转储企业员工信息
关于LinkedInDumper LinkedInDumper是一款针对LinkedIn社交媒体网络平台的数据收集工具,该工具基于Python 3开发,可以帮助广大企业网络安全管理…
-
新冠肺炎疫情对互联网行业的影响分析:线上产业链新机遇
2020年初的一场新冠肺炎疫情,让中国猝不及防,随后,一场声势浩大的疫情对抗战轰轰烈烈地拉开了序幕,整个中国都行动起来了,相信疫情也会在不长时间内得到控制,社会和人们的生活进入正常…
-
Vue CLI模式和环境变量
模式是Vue CLI项目中的一个重要概念,默认情况下它有三种模式: development 被 vue-cli-service serve 使用 test 由 vue-cli-se…
-
SQL优化必备:并行执行框架和执行计划
GaussDB(for openGauss)作为自主研发的新一代金融级分布式关系型数据库,采用可横向扩展的分布式架构,通过 SQL 优化器生成分布式算子以及分布式执行计划,提供了三种 stream 流(广播流、聚合流和重分布流)来降低数据在 DN 节点间的流动